¿Es bueno tu modelo?
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
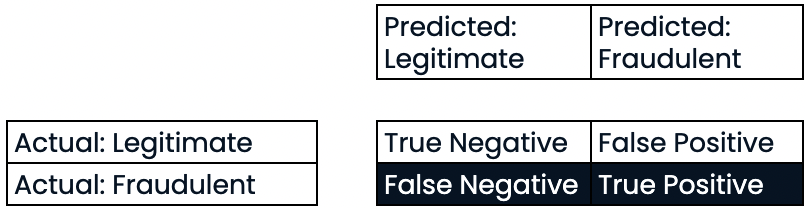
Matriz de confusión para evaluar el rendimiento de la clasificación
- Matriz de confusión
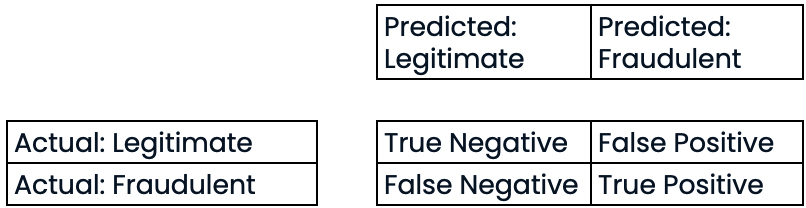
Evaluar el rendimiento de la clasificación
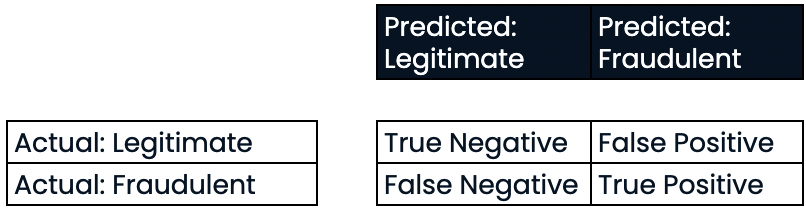
Evaluar el rendimiento de la clasificación

Evaluar el rendimiento de la clasificación
Evaluar el rendimiento de la clasificación
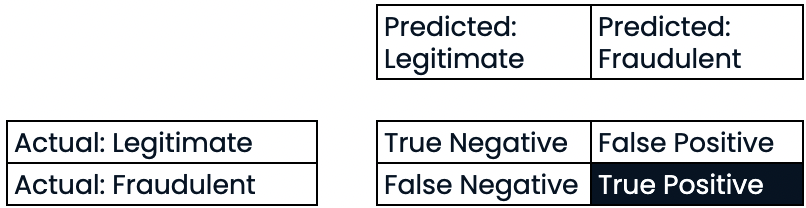
Evaluar el rendimiento de la clasificación
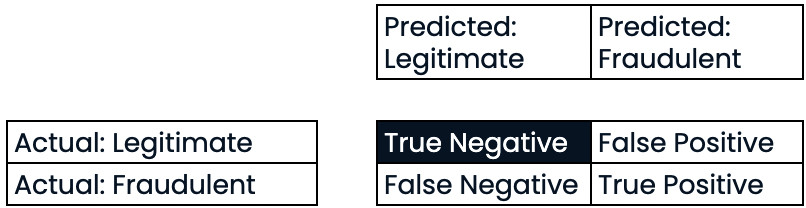
Evaluar el rendimiento de la clasificación
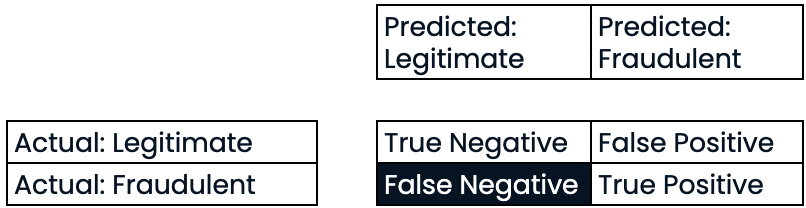
Evaluar el rendimiento de la clasificación
Evaluar el rendimiento de la clasificación
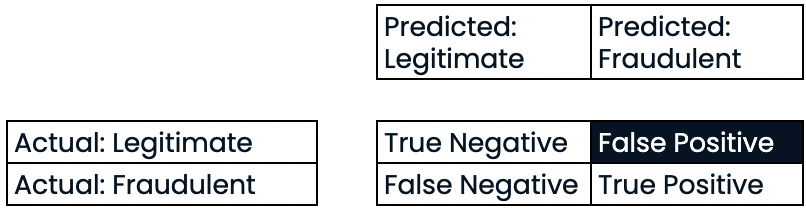
- Precisión:
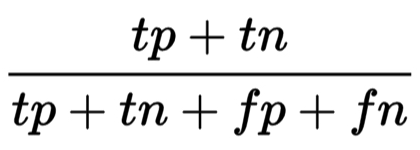
Precisión
- Precisión
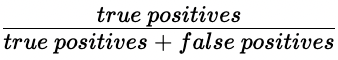
- Alta precisión = menor tasa de falsos positivos
- Con una alta precisión, no se prevé que muchas transacciones legítimas sean fraudulentas.
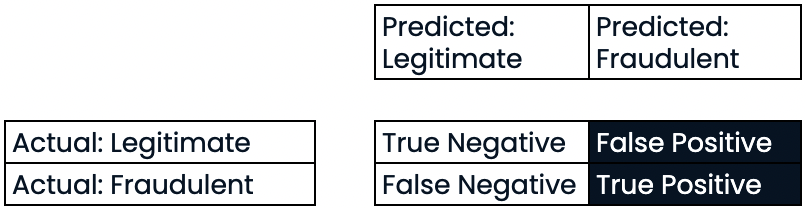
Sensibilidad o exhaustividad (recall))
- Sensibilidad o exhaustividad (recall)
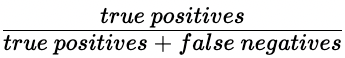
- Alta exhaustividad = menor tasa de falsos negativos
- Con una alta exhaustividad, se predijeron correctamente la mayoría de las transacciones fraudulentas.

