Evaluar varios modelos
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Diferentes modelos para diferentes problemas
Algunos principios rectores
- Tamaño del conjunto de datos
- Menos características = modelo más simple, tiempo de entrenamiento más rápido
- Algunos modelos requieren grandes cantidades de datos para funcionar bien.
- Interpretabilidad
- Algunos modelos son más fáciles de explicar, lo que puede ser importante para las partes interesadas.
- La regresión lineal tiene una gran interpretabilidad, ya que podemos entender los coeficientes.
- Flexibilidad
- Puede mejorar la precisión, al hacer menos suposiciones sobre los datos.
- KNN es un modelo más flexible, no asume ninguna relación lineal
Todo está en las métricas
Rendimiento del modelo de regresión:
- Error cuadrático medio (RMSE)
- R-cuadrado
Rendimiento del modelo de clasificación:
- Precisión
- Matriz de confusión
- Precisión, exhaustividad, puntuación F1
- ROC AUC
Entrena varios modelos y evalúa el rendimiento nada más empezar
Nota sobre el escalado
- Modelos afectados por la escala:
- KNN
- Regresión lineal (más Ridge, Lasso)
- Regresión logística
- Red neuronal artificial
- Es mejor escalar nuestros datos antes de evaluar los modelos.
Evaluar los modelos de clasificación
import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score, KFold, train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifierX = music.drop("genre", axis=1).values y = music["genre"].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
Evaluar los modelos de clasificación
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()} results = []for model in models.values():kf = KFold(n_splits=6, random_state=42, shuffle=True)cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)results.append(cv_results)plt.boxplot(results, labels=models.keys()) plt.show()
Visualizar los resultados
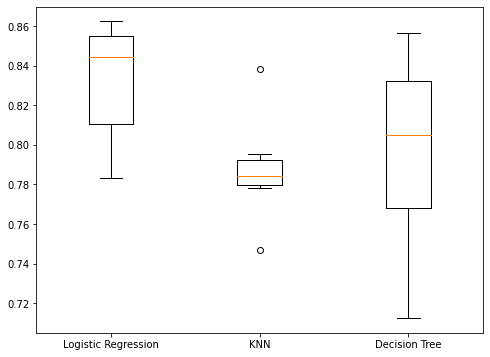
Rendimiento del conjunto de pruebas
for name, model in models.items():model.fit(X_train_scaled, y_train)test_score = model.score(X_test_scaled, y_test)print("{} Test Set Accuracy: {}".format(name, test_score))
Logistic Regression Test Set Accuracy: 0.844
KNN Test Set Accuracy: 0.82
Decision Tree Test Set Accuracy: 0.832
¡Vamos a practicar!
Aprendizaje supervisado con scikit-learn

