Validación cruzada
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Fundamentos de la validación cruzada

Fundamentos de la validación cruzada

Fundamentos de la validación cruzada

Fundamentos de la validación cruzada

Fundamentos de la validación cruzada
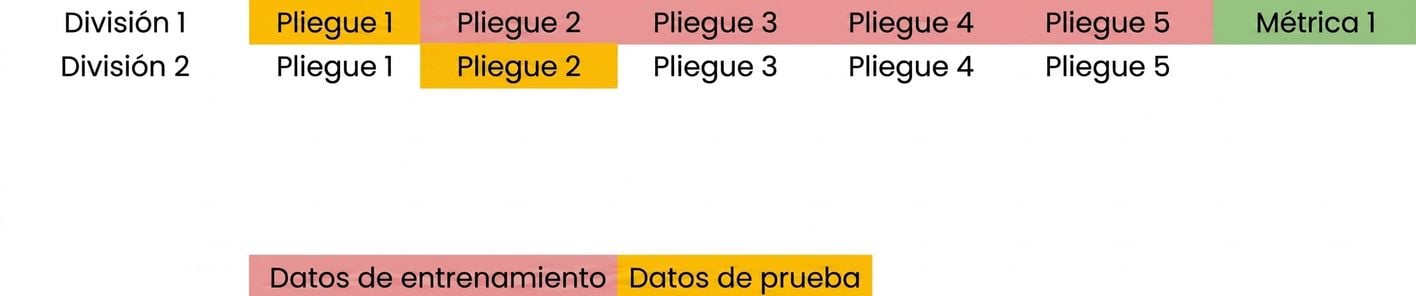
Fundamentos de la validación cruzada
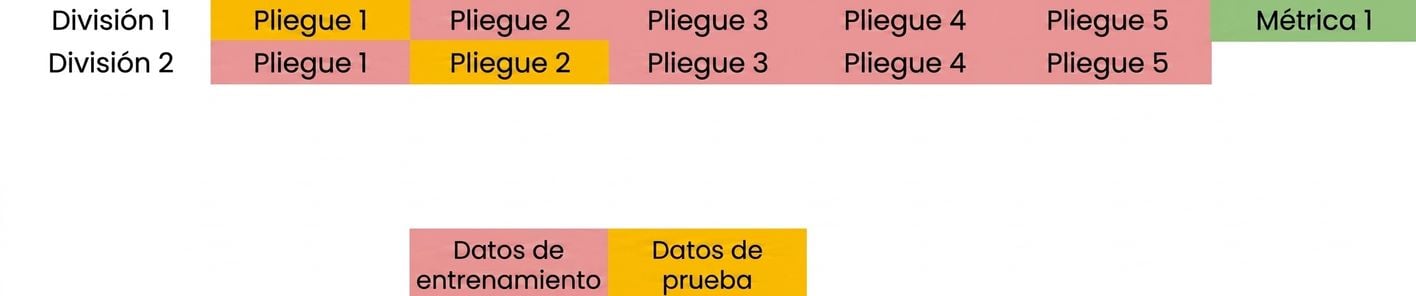
Fundamentos de la validación cruzada
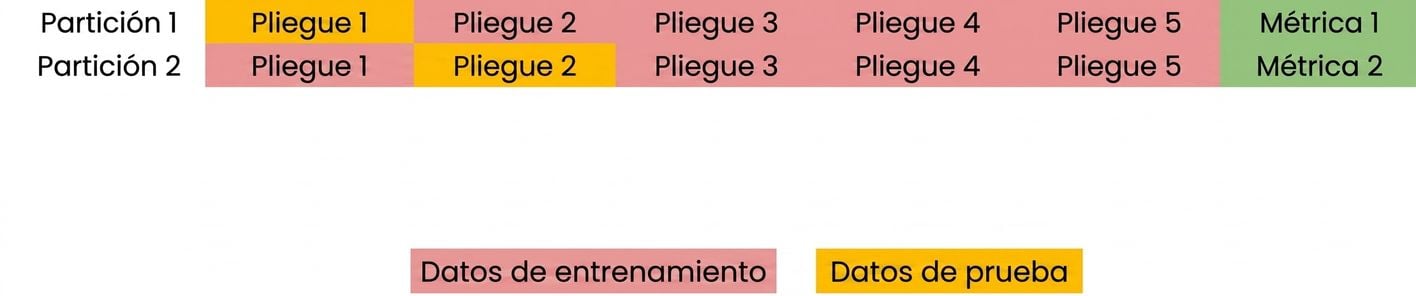
Fundamentos de la validación cruzada

Fundamentos de la validación cruzada
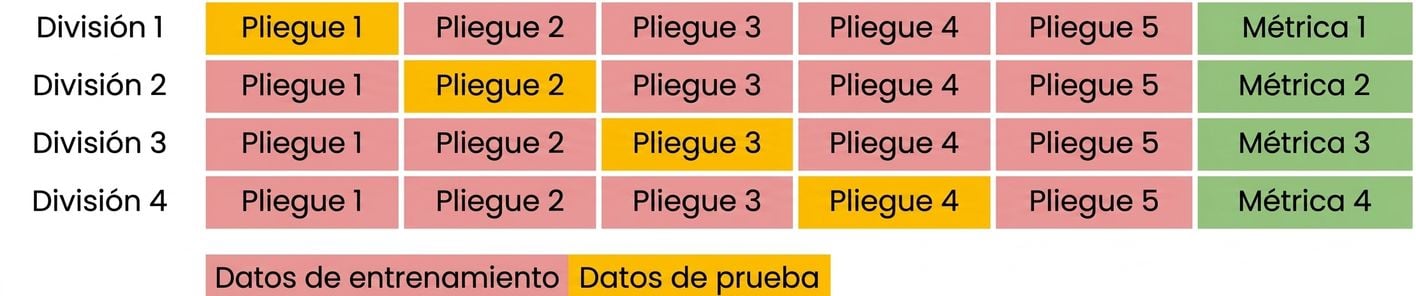
Fundamentos de la validación cruzada


