Regresión regularizada
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
¿Por qué regularizar?
Sensibilidad o exhaustividad (también conocida como recall): la regresión lineal minimiza una función de pérdida
Elige un coeficiente $a$ para cada variable de característica más $b$
Los coeficientes grandes pueden llevar a un sobreajuste
La regularización: penaliza los coeficientes elevados
Regresión Ridge
Función de pérdidas = función de pérdidas MCO + $$ \alpha * \sum_{i=1}^{n} {a_i}^2$$
Ridge penaliza los coeficientes positivos o negativos grandes
$\alpha$: parámetro que tenemos que elegir
Elegir $\alpha$ es similar a elegir
ken KNNHiperparámetro: variable utilizada para optimizar los parámetros del modelo
$\alpha$ controla la complejidad del modelo
$\alpha$ = 0 = MCO (puede llevar a un sobreajuste)
$\alpha$ muy elevado: puede llevar a un ajuste insuficiente
Regresión Ridge en Scikit-learn
from sklearn.linear_model import Ridgescores = [] for alpha in [0.1, 1.0, 10.0, 100.0, 1000.0]:ridge = Ridge(alpha=alpha)ridge.fit(X_train, y_train) y_pred = ridge.predict(X_test)scores.append(ridge.score(X_test, y_test))print(scores)
[0.2828466623222221, 0.28320633574804777, 0.2853000732200006,
0.26423984812668133, 0.19292424694100963]
Regresión Lasso
- Función de pérdidas = función de pérdidas MCO + $$ \alpha * \sum_{i=1}^{n} |a_i|$$
Regresión Lasso en scikit-learn
from sklearn.linear_model import Lassoscores = [] for alpha in [0.01, 1.0, 10.0, 20.0, 50.0]: lasso = Lasso(alpha=alpha) lasso.fit(X_train, y_train) lasso_pred = lasso.predict(X_test) scores.append(lasso.score(X_test, y_test)) print(scores)
[0.99991649071123, 0.99961700284223, 0.93882227671069, 0.74855318676232, -0.05741034640016]
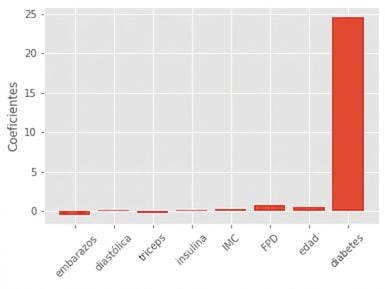
Regresión Lasso para la selección de características
Lasso puede seleccionar características importantes de un conjunto de datos.
Reduce a cero los coeficientes de las características menos importantes.
Las características no reducidas a cero se seleccionan mediante Lasso.
Lasso para la selección de características en scikit-learn
from sklearn.linear_model import LassoX = diabetes_df.drop("glucose", axis=1).values y = diabetes_df["glucose"].values names = diabetes_df.drop("glucose", axis=1).columnslasso = Lasso(alpha=0.1)lasso_coef = lasso.fit(X, y).coef_plt.bar(names, lasso_coef) plt.xticks(rotation=45) plt.show()
Lasso para la selección de características en scikit-learn
¡Vamos a practicar!
Aprendizaje supervisado con scikit-learn

