Medir el rendimiento del modelo
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Medir el rendimiento del modelo
En clasificación, se utiliza a menudo la métrica de la precisión.
Precisión:
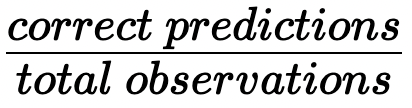
Precisión de cálculo
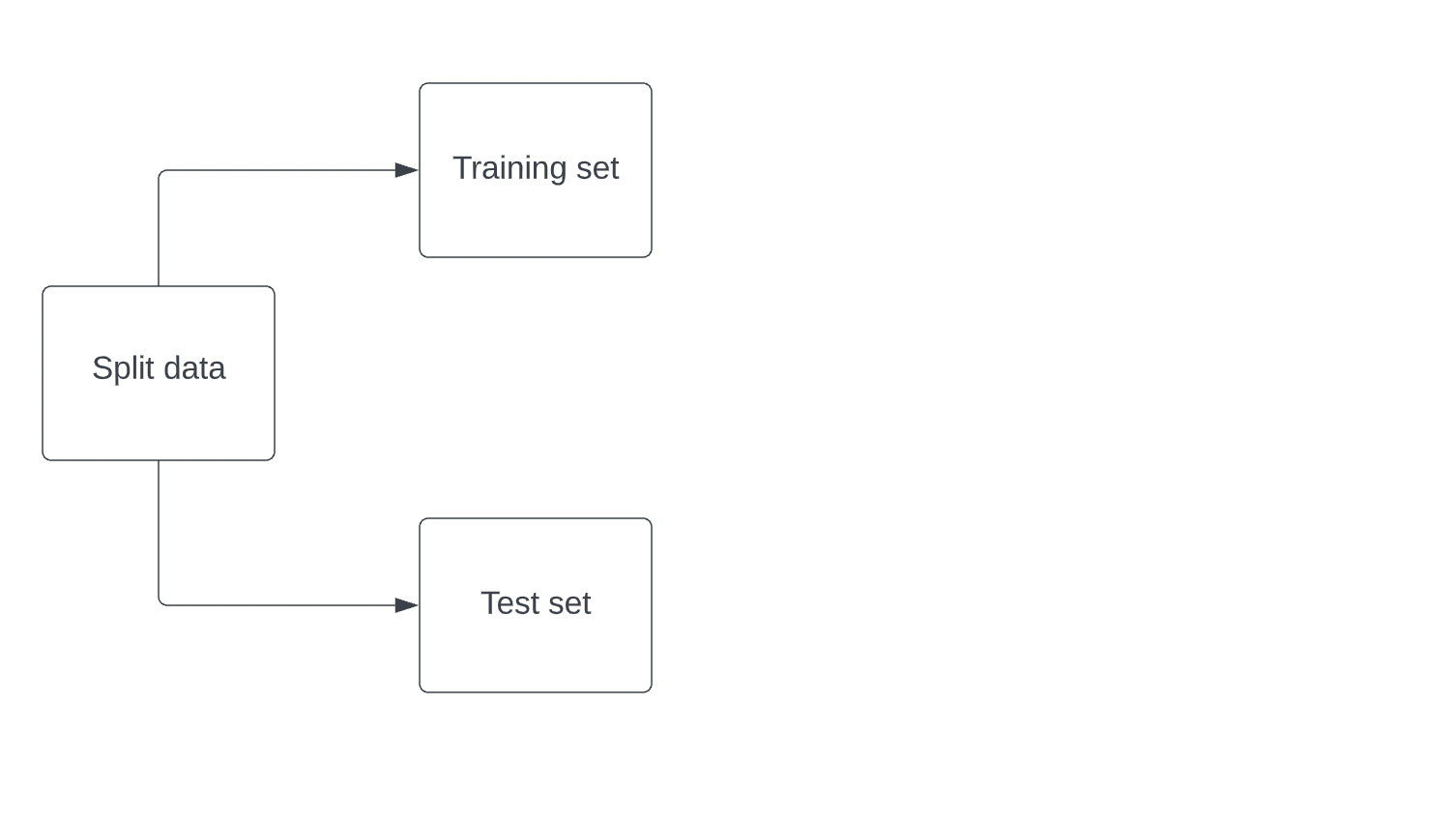
Precisión de cálculo
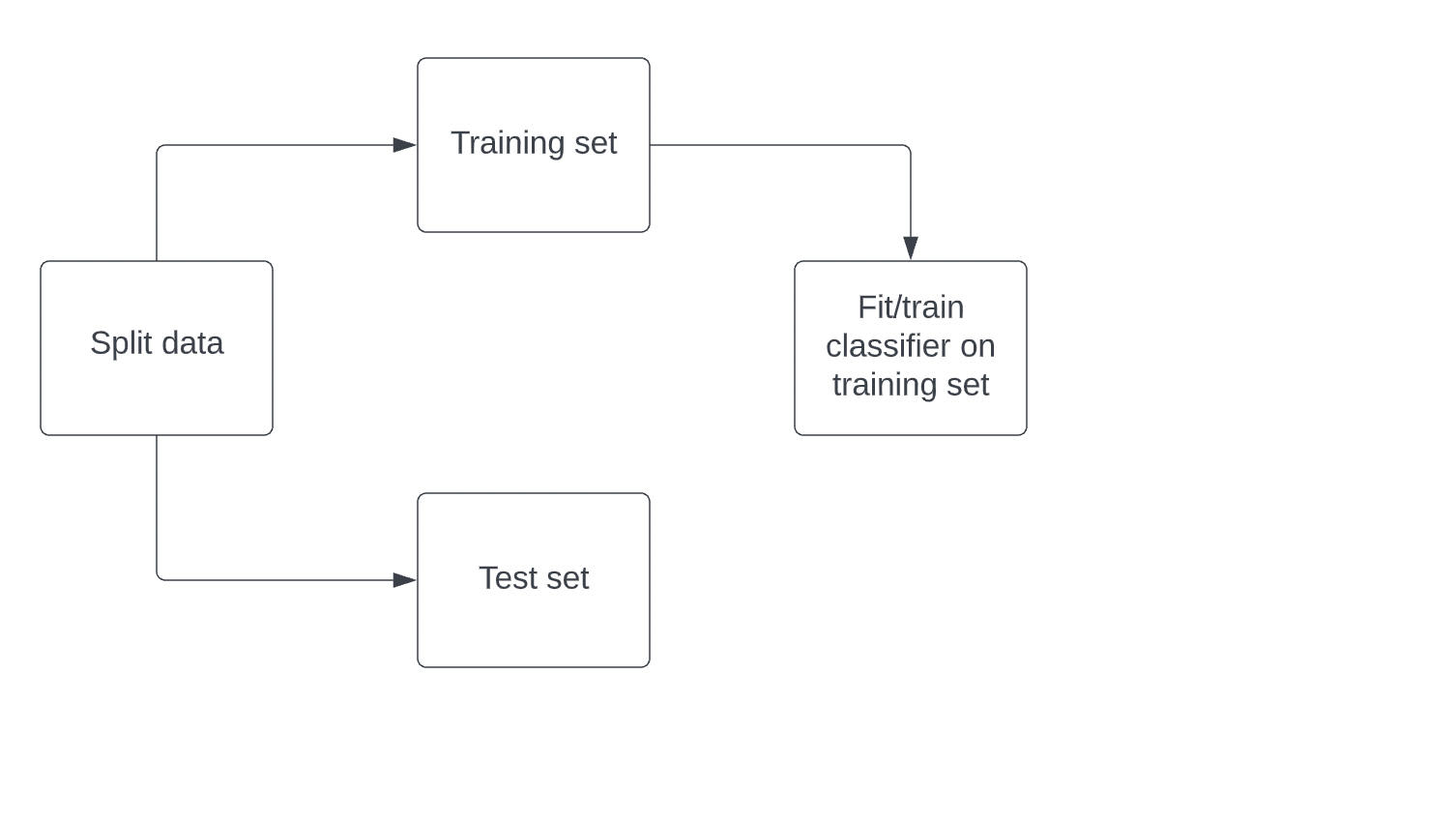
Precisión de cálculo
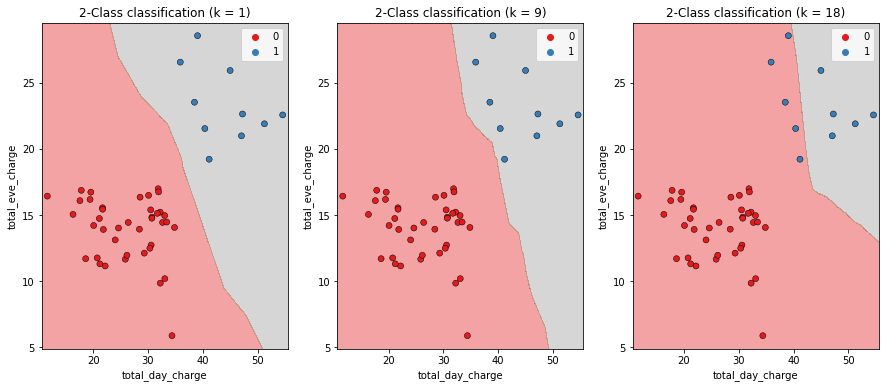
Complejidad del modelo
k mayor = modelo menos complejo = puede provocar un ajuste insuficiente
k menor = modelo más complejo = puede llevar a un sobreajuste
Curva de complejidad del modelo
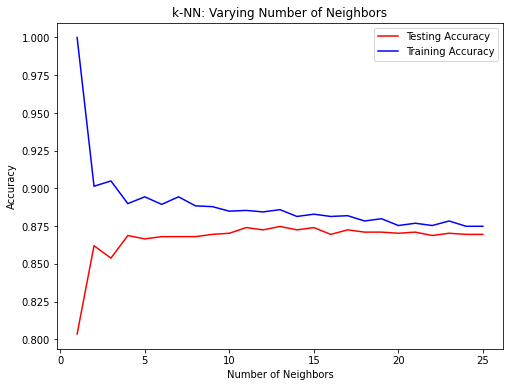
Curva de complejidad del modelo
![]()

