El reto de la clasificación
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
k vecinos más cercanos (KNN)
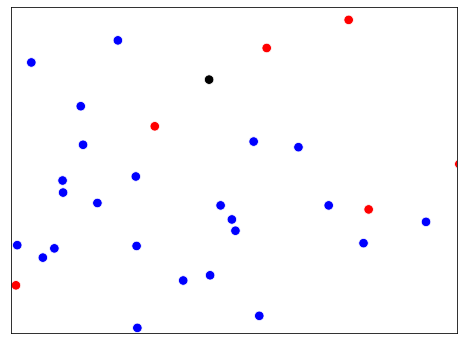
k vecinos más cercanos (KNN)
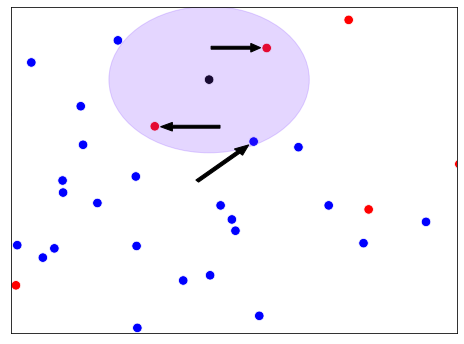
k vecinos más cercanos (KNN)
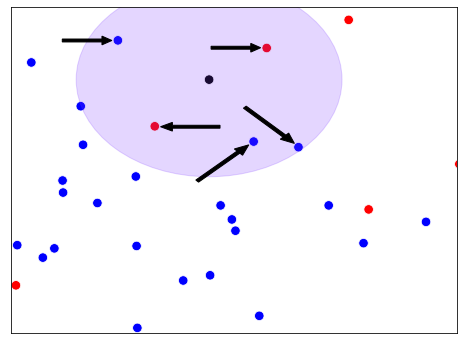
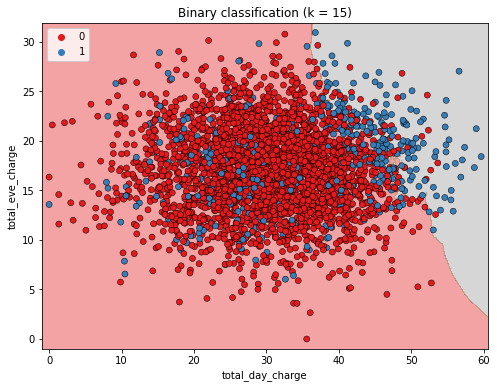
Intuición KNN
Intuición KNN
Aprendizaje supervisado con scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

