Preprocesamiento de datos
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Variables ficticias

Variables ficticias
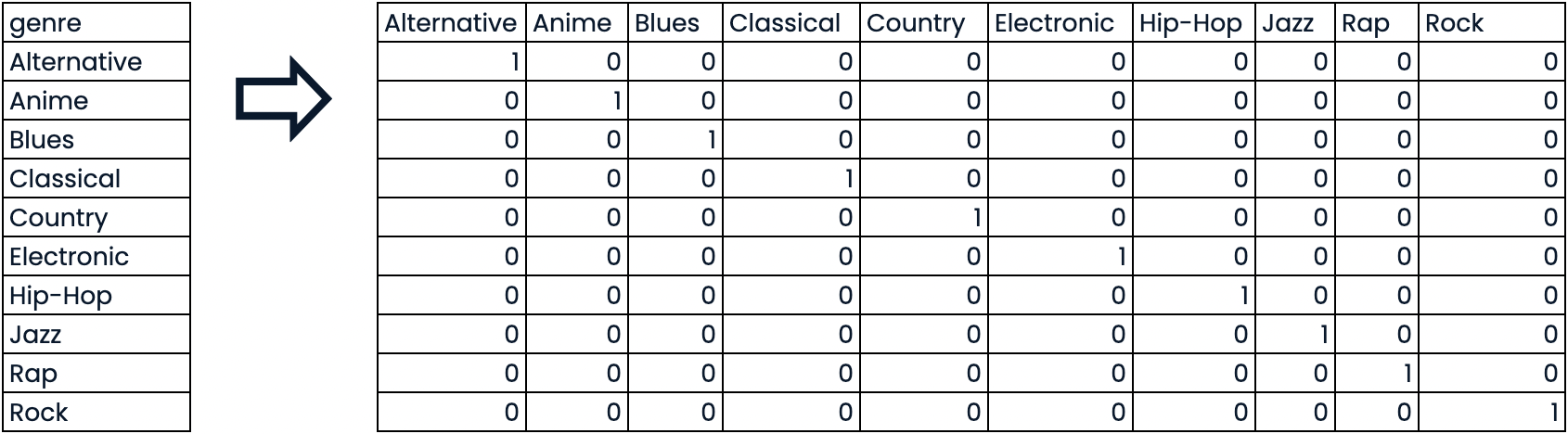
Variables ficticias
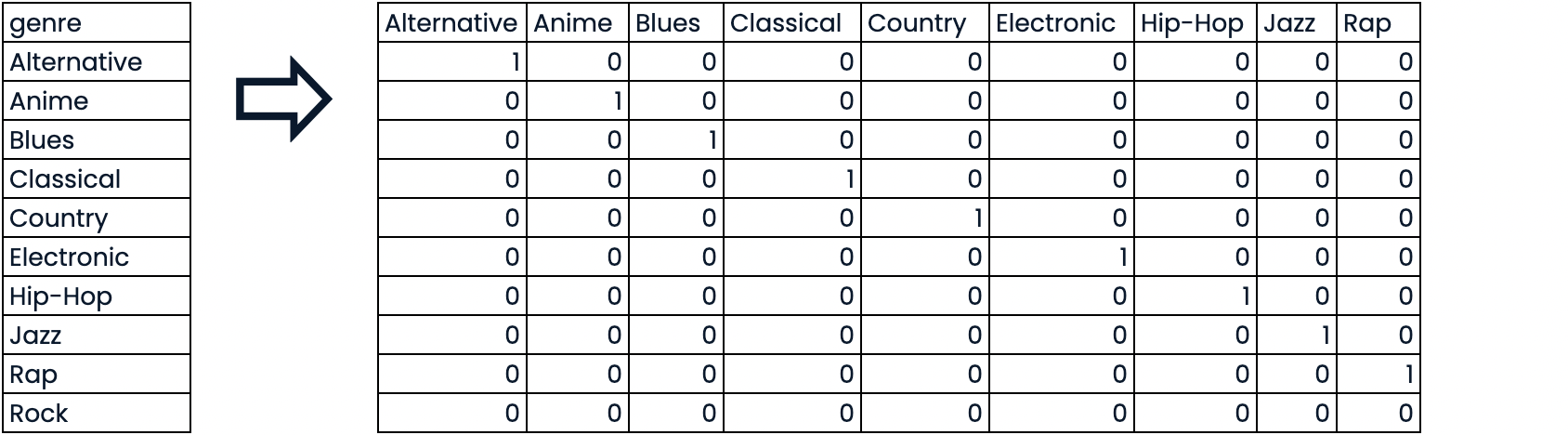
EDA con característica categórica
Aprendizaje supervisado con scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

