Optimización de hiperparámetros
Aprendizaje supervisado con scikit-learn

George Boorman
Core Curriculum Manager
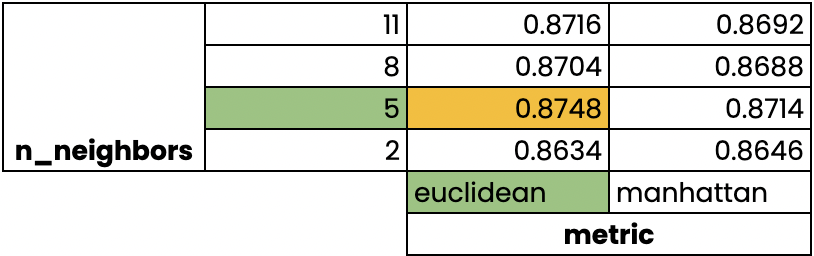
Validación cruzada de búsqueda en cuadrícula
Validación cruzada de búsqueda en cuadrícula
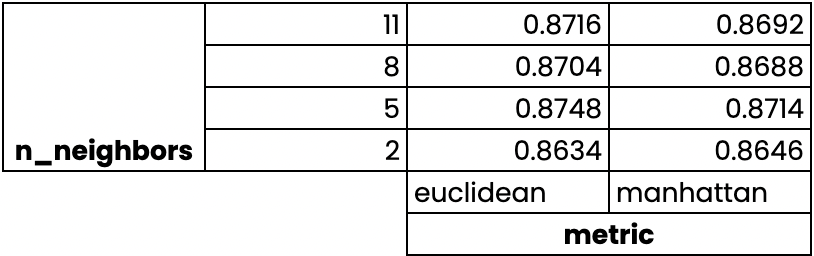
Validación cruzada de búsqueda en cuadrícula