Daten speichern
Datenbankdesign

Lis Sulmont
Curriculum Manager
Daten strukturieren

1 Blume von Sam Oth und Datenbankdiagramm von Nick Jenkins über Wikimedia Commons https://commons.wikimedia.org/wiki/File:Languages_xml.png
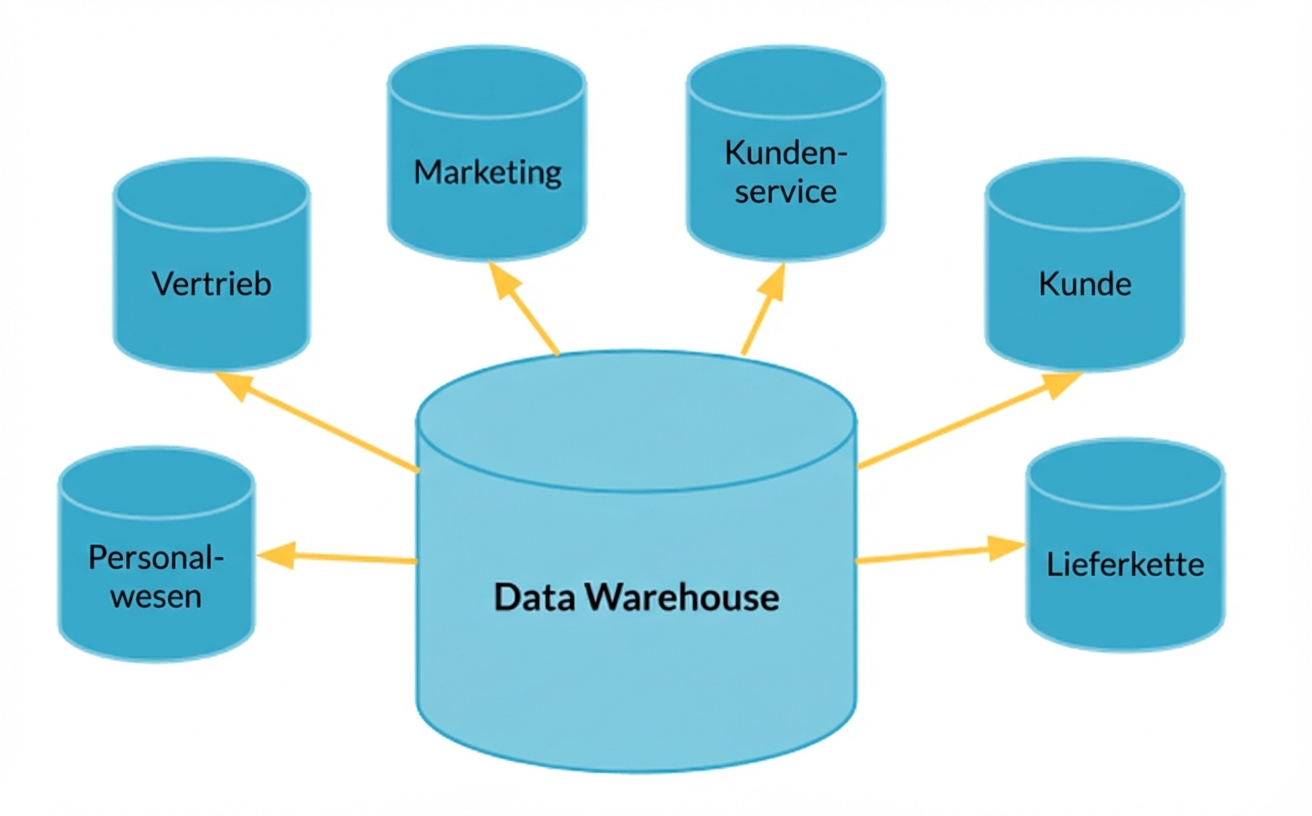
Data Warehouses
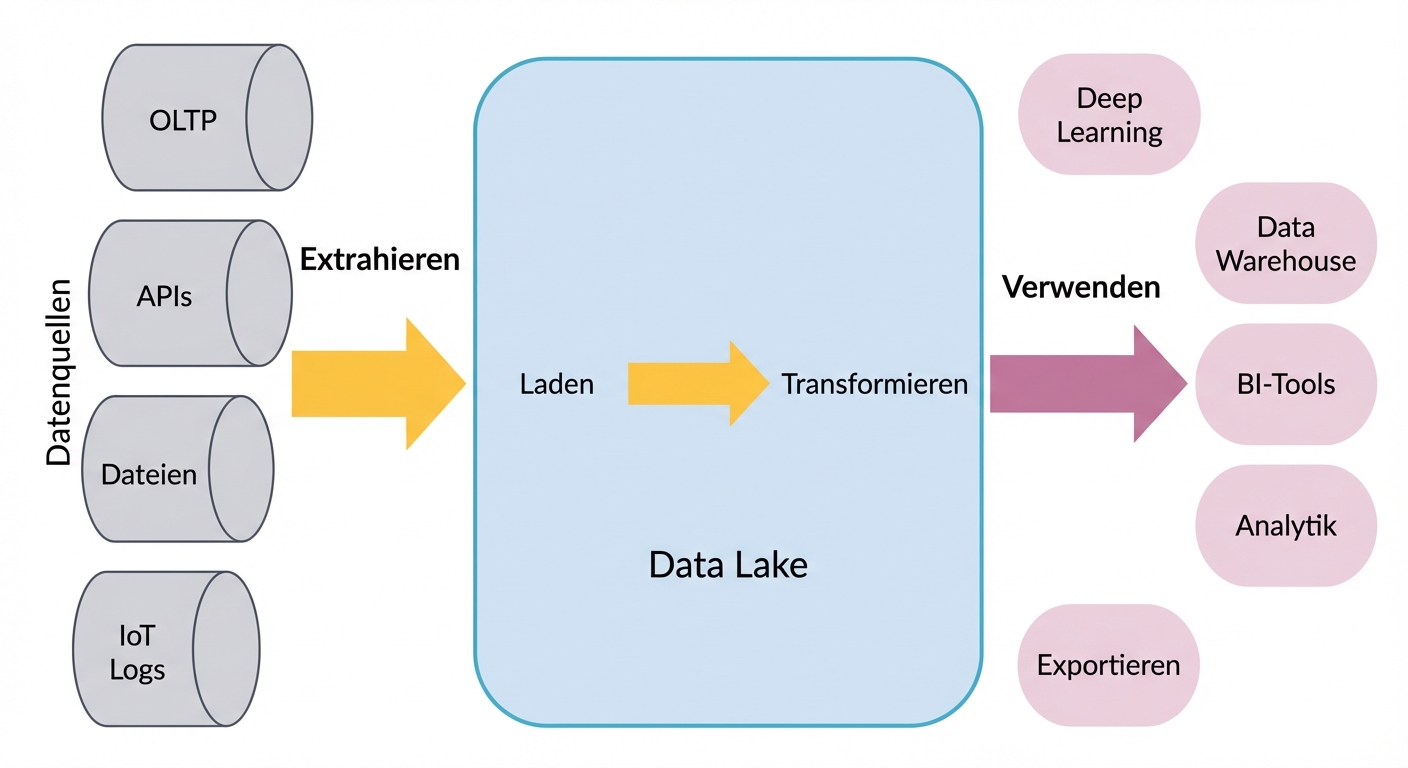
Data Lakes
- Speichern alle Arten von Daten zu geringeren Kosten:
- z. B. Rohdaten, Betriebsdatenbanken, IoT-Geräteprotokolle, Echtzeitdaten, relationale und nicht relationale Daten
- Speichern alle Daten und umfassen oft Petabytes
- Schema-on-read im Gegensatz zu Schema-on-write
- Daten müssen katalogisiert werden, sonst schnell Data Swamp
- Big-Data-Analytics mit Diensten wie Apache Spark und Hadoop.
- Nützlich für Deep Learning und Datenermittlung, weil die Aktivitäten so viele Daten brauchen

ETL
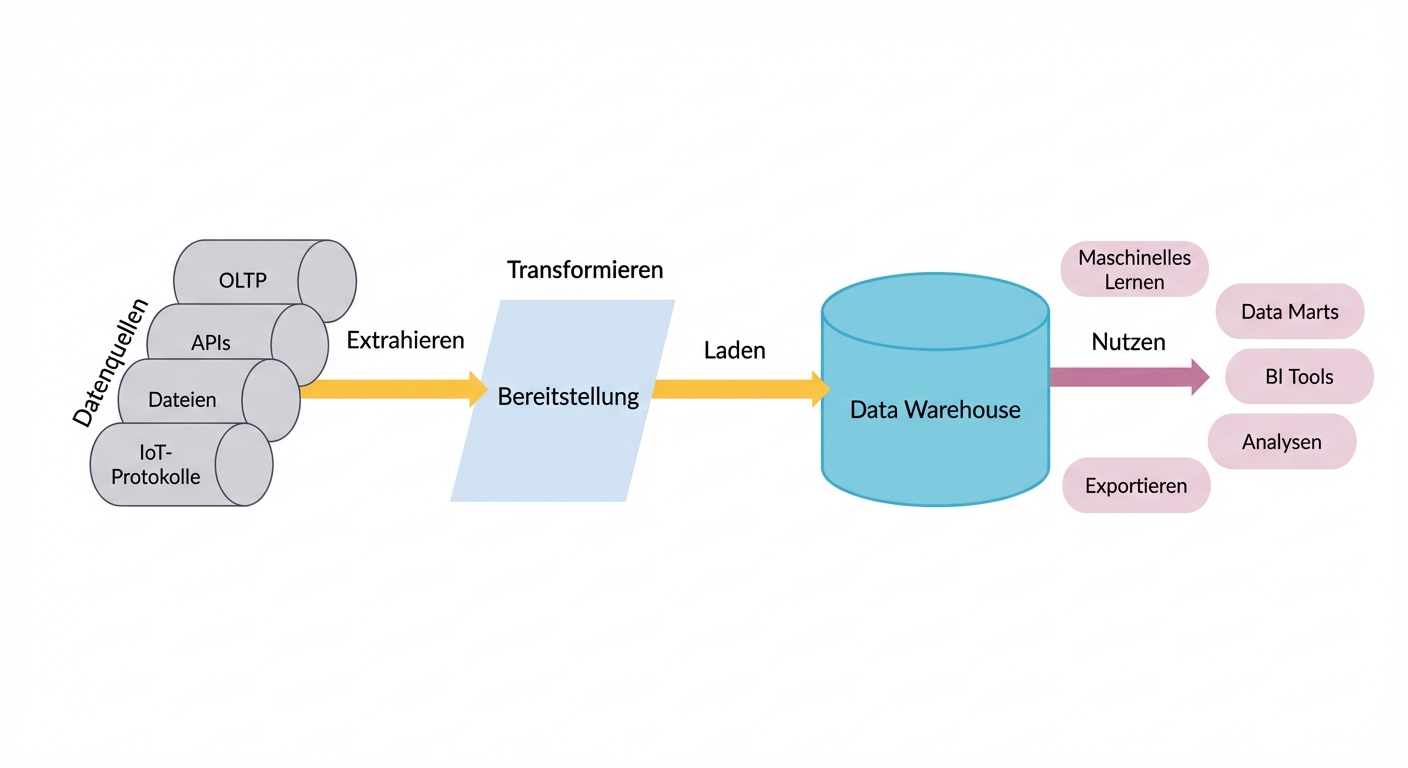
ELT