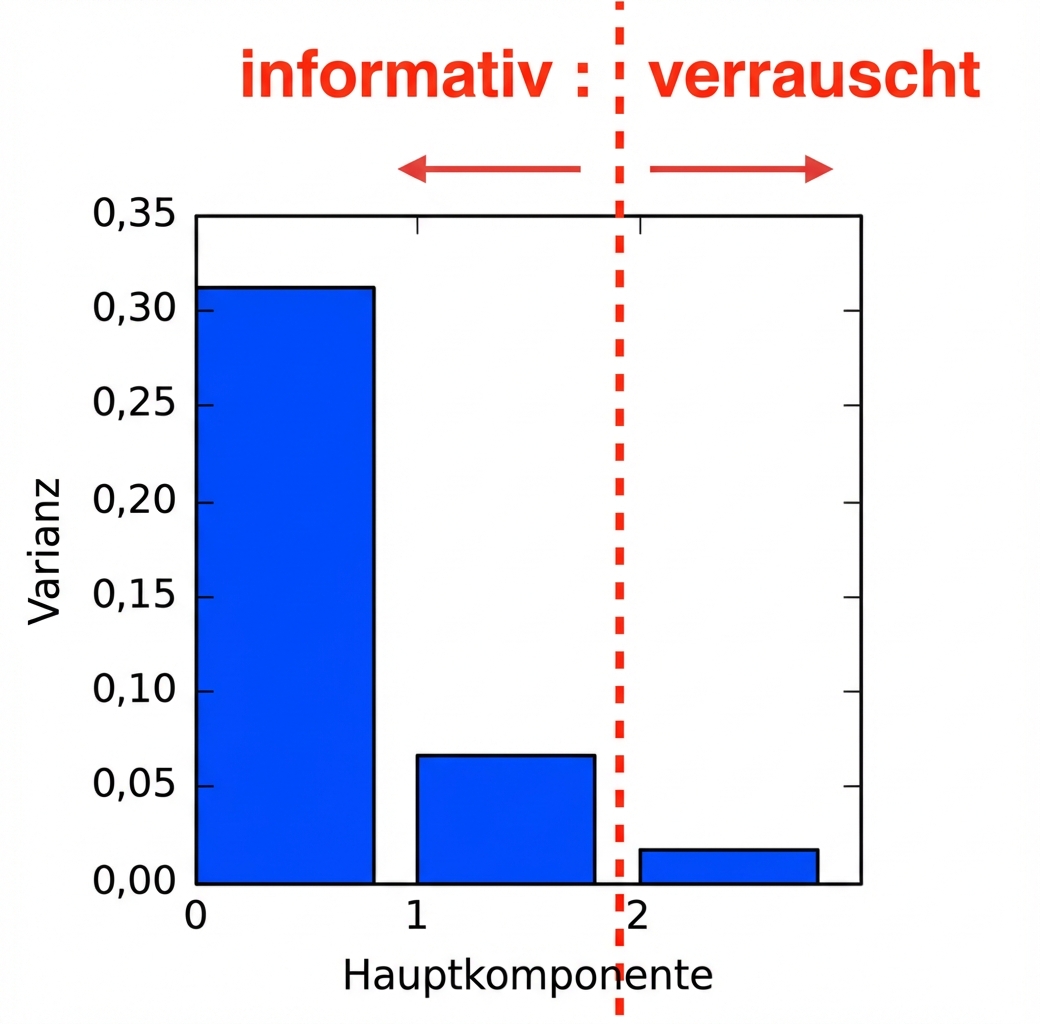
Dimensionsreduktion mit PCA
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
Dimensionsreduktion mit PCA
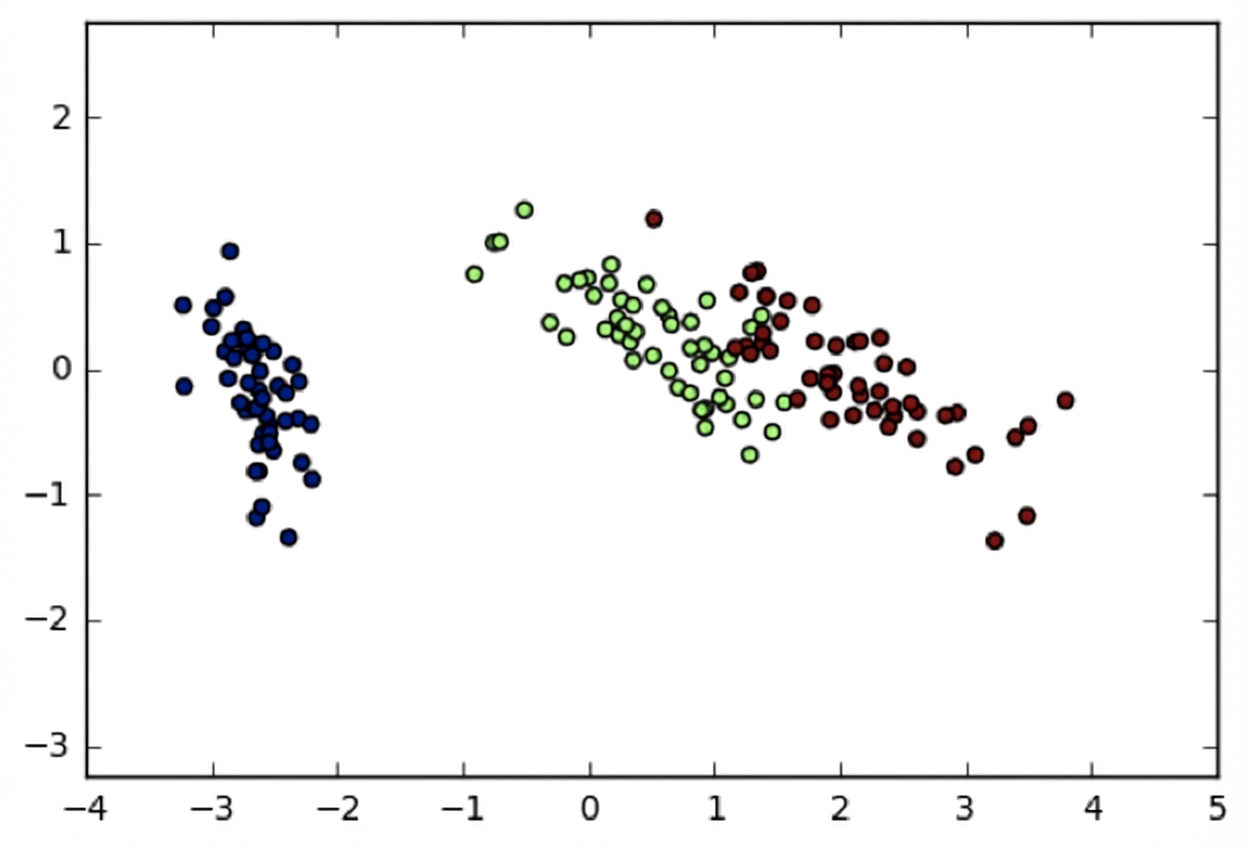
Iris-Datensatz in zwei Dimensionen
import matplotlib.pyplot as plt
xs = transformed[:,0]
ys = transformed[:,1]
plt.scatter(xs, ys, c=species)
plt.show()
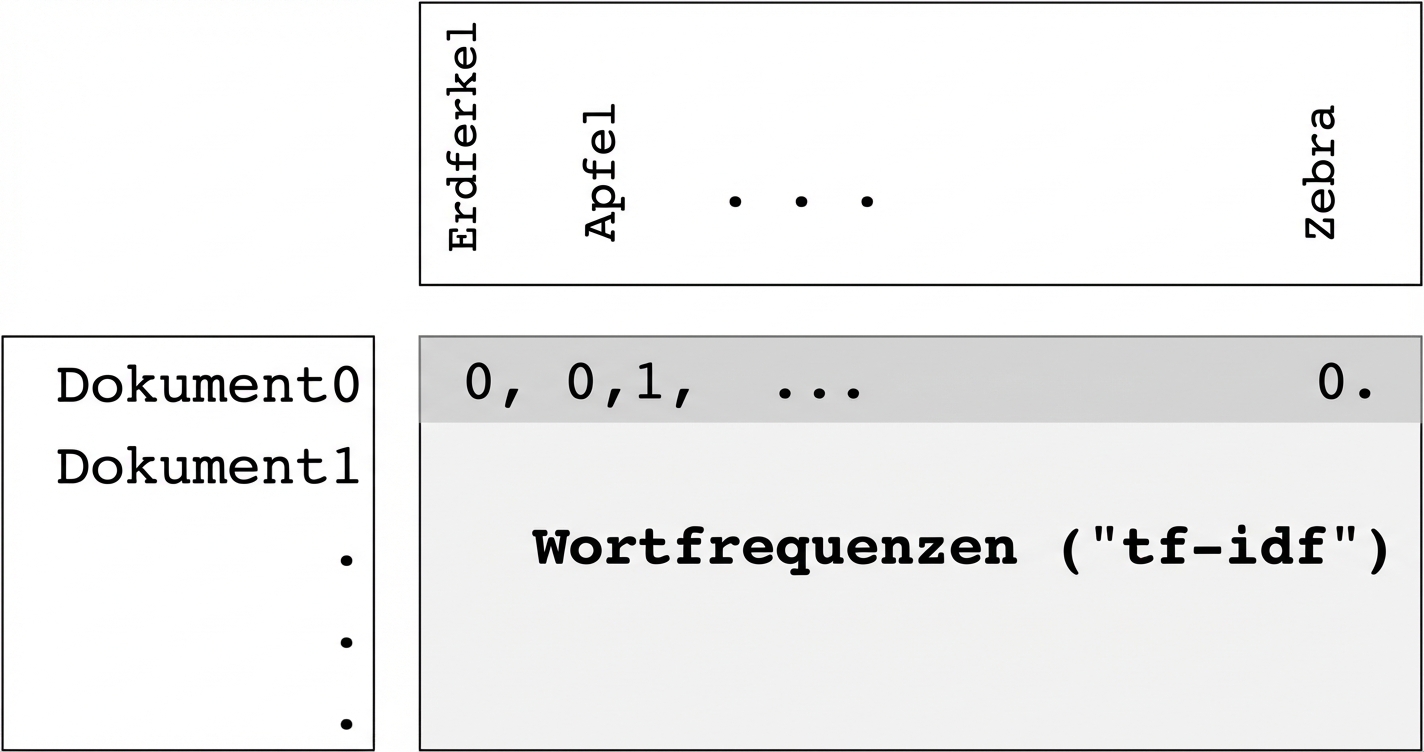
Worthäufigkeit-Arrays
- Die Zeilen stehen für Dokumente, die Spalten für Wörter.
- Die Einträge repräsentieren die Häufigkeit jedes Wortes in jedem Dokument.
- Messung mittels „tf-idf” (mehr dazu später)
Sparse-Arrays und csr_matrix
- „Sparse“: Die meisten Einträge mit dem Wert Null.
- Du kannst
scipy.sparse.csr_matrixanstelle von NumPy-Arrays verwenden. csr_matrixmerkt sich nur die Einträge, die nicht Null sind (spart Speicherplatz!)

