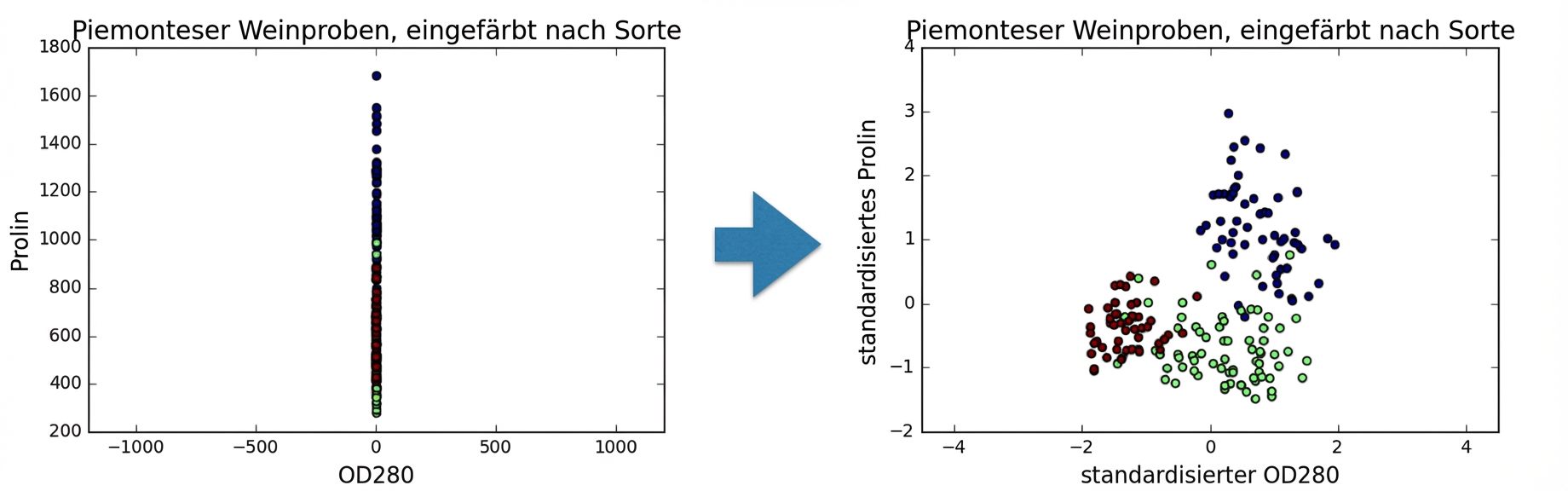
Transformationen von Merkmalen für bessere Clusterings
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
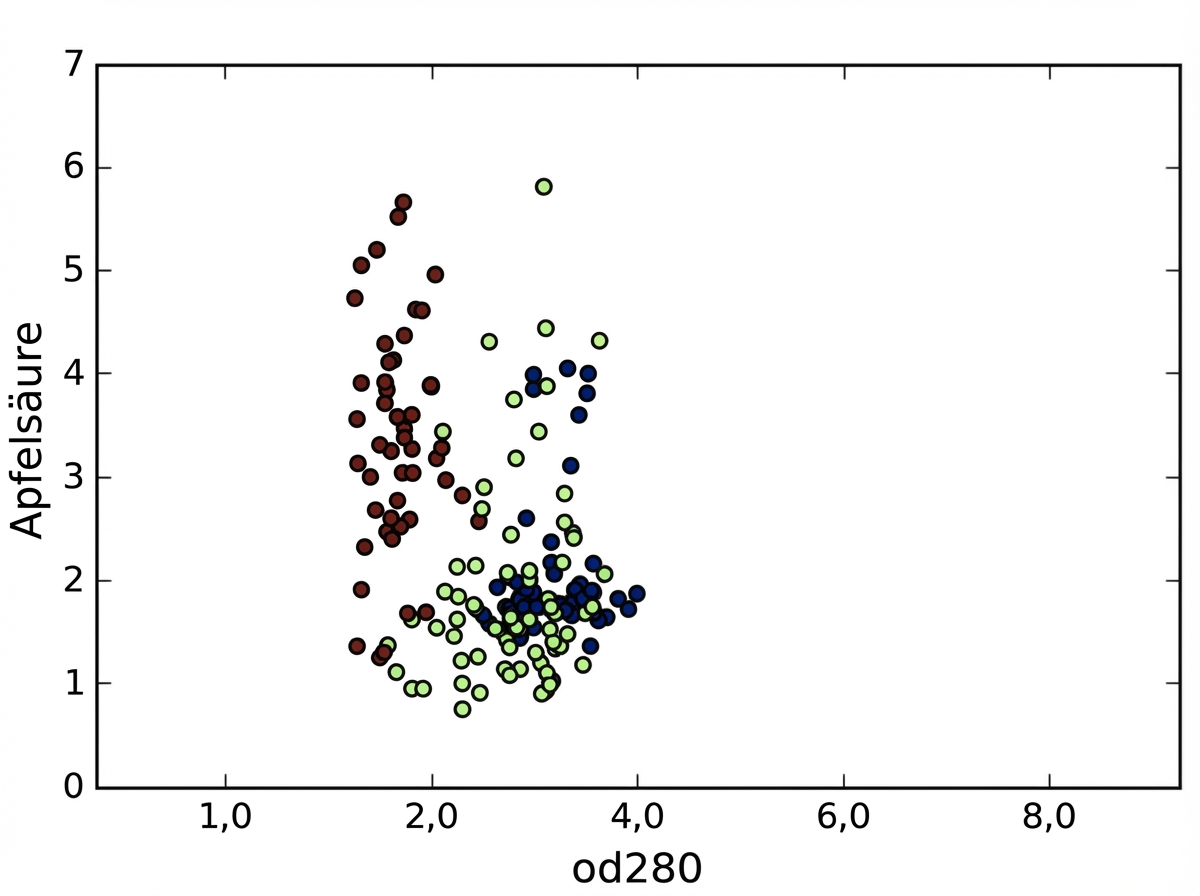
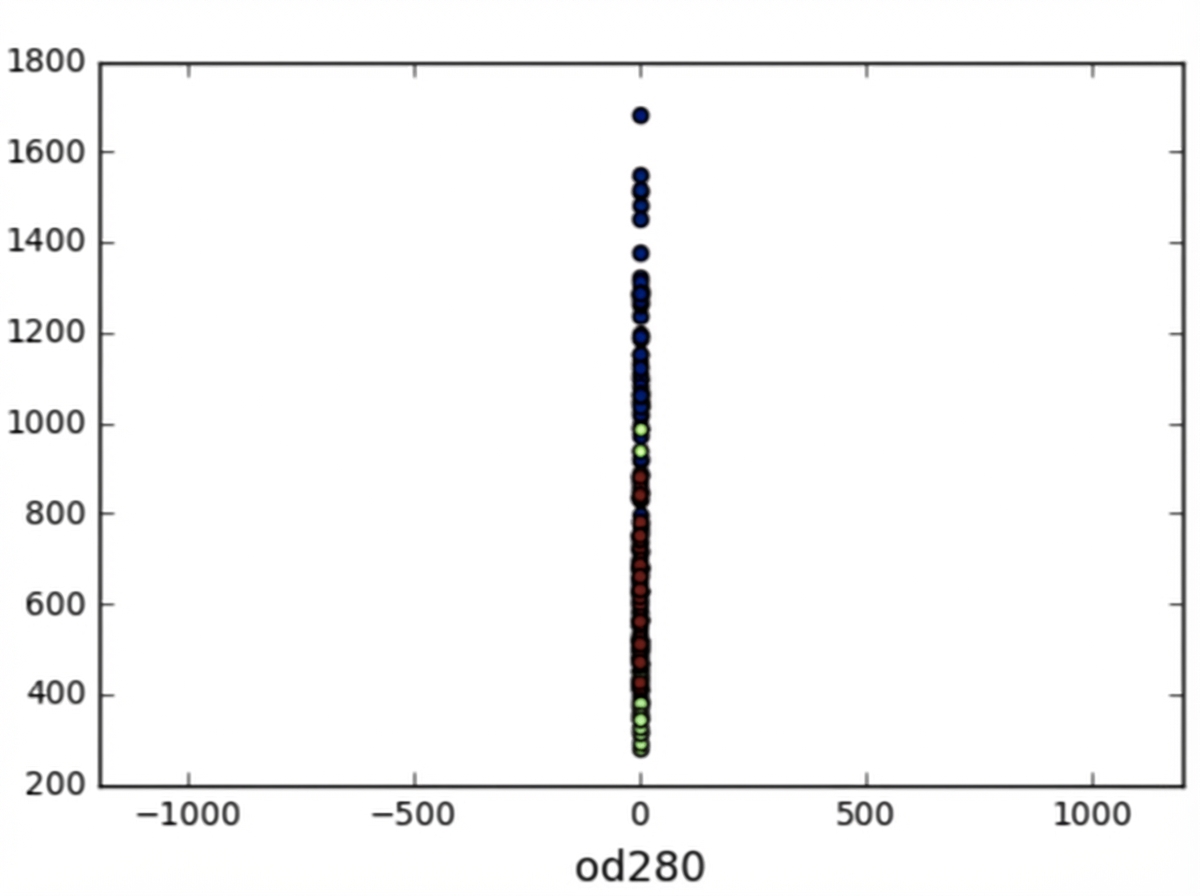
Varianzen von Merkmalen
Varianzen von Merkmalen
StandardScaler
Bei k-Means: Merkmalsvarianz = Einfluss des Merkmals
StandardScalerwandelt jedes Merkmal so um, dass es den Mittelwert 0 und die Varianz 1 aufweist.Merkmale werden „standardisiert“.