Bewertung eines Clustering
Unsupervised Learning in Python

Benjamin Wilson
Director of Research at lateral.io
Die Anzahl der Cluster
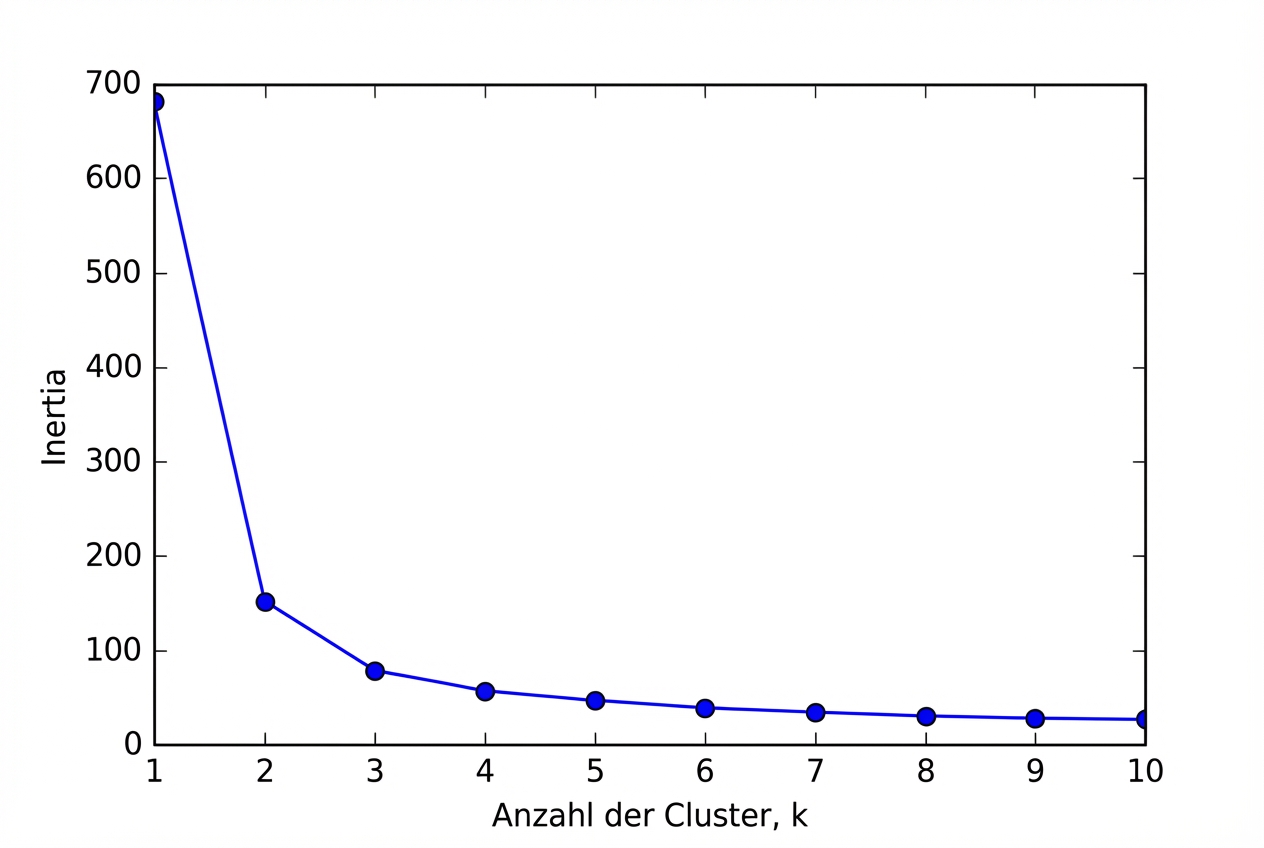
Wie viele Cluster soll man wählen?
Unsupervised Learning in Python
Benjamin Wilson
Director of Research at lateral.io

