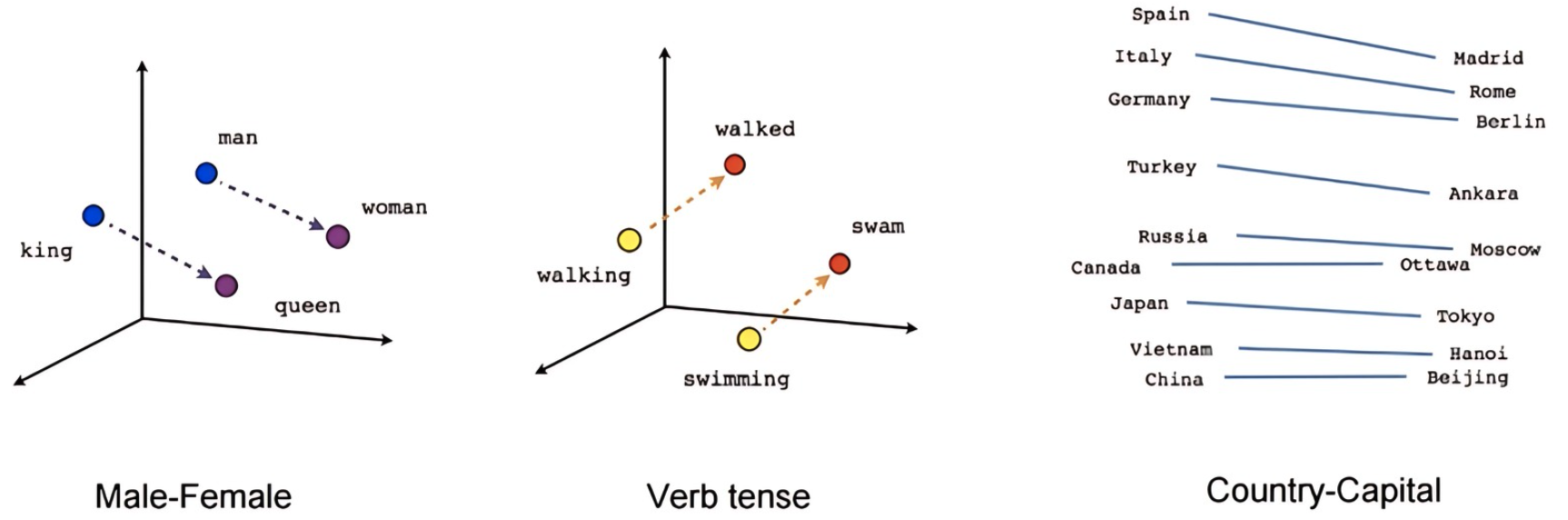
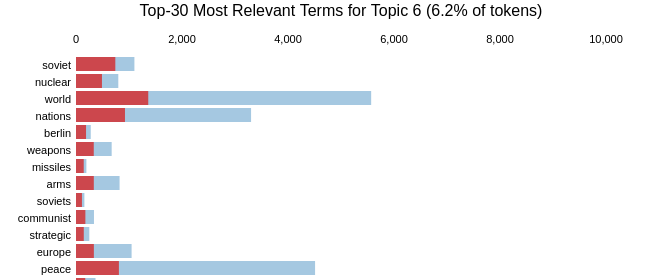from gensim.corpora.dictionary import Dictionary
from nltk.tokenize import word_tokenize
my_documents = ['The movie was about a spaceship and aliens.',
'I really liked the movie!',
'Awesome action scenes, but boring characters.',
'The movie was awful! I hate alien films.',
'Space is cool! I liked the movie.',
'More space films, please!',]
tokenized_docs = [word_tokenize(doc.lower())
for doc in my_documents]
dictionary = Dictionary(tokenized_docs)
dictionary.token2id