Aufteilen externer Daten für den Abruf
Entwickeln von LLM-Anwendungen mit LangChain

Jonathan Bennion
AI Engineer & LangChain Contributor
RAG-Entwicklungsschritte
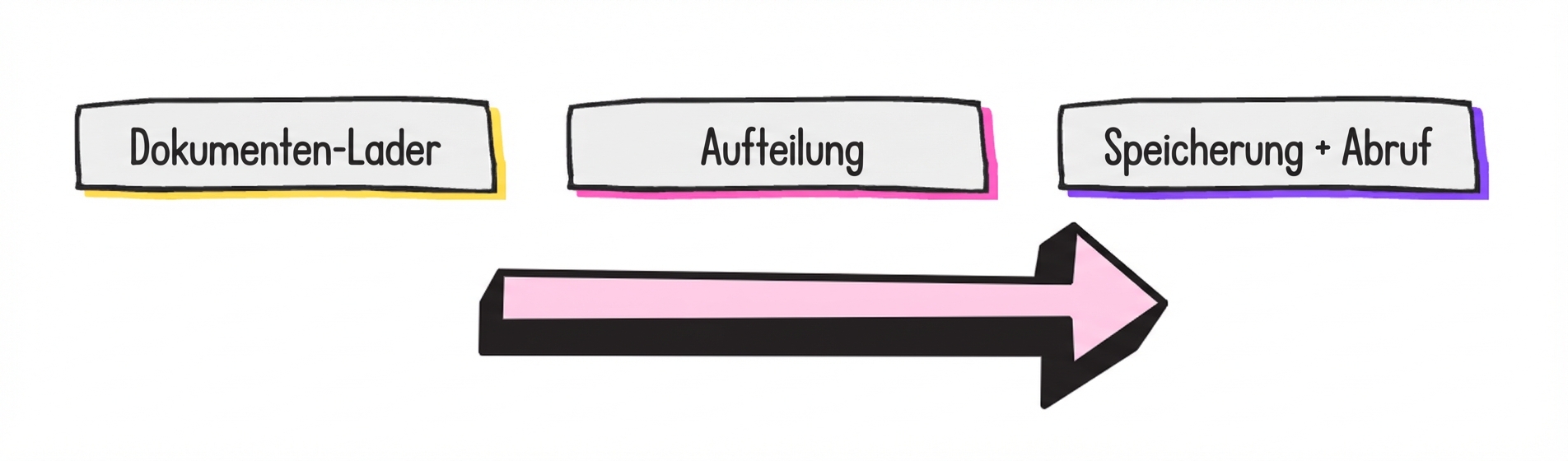
- Document splitting: Dokument in Chunks aufteilen
- Dokumente so aufteilen, dass sie in das Kontextfenster eines LLM passen
Über eine Trennung nachdenken...

1 https://arxiv.org/abs/1706.03762
Chunk-Überlappung

Was ist die beste Strategie zum Aufteilen von Dokumenten?

1 Wikipedia Commons

