Diagnose von Bias- und Varianzproblemen
Maschinelles Lernen mit baumbasierten Modellen in Python

Elie Kawerk
Data Scientist
Den Generalisierungsfehler einschätzen
Wie schätzen wir den Generalisierungsfehler eines Modells?
Das geht nicht direkt, weil:
$f$ ist nicht bekannt
Normalerweise hat man nur einen Datensatz
Rauschen ist unberechenbar
Den Generalisierungsfehler einschätzen
Lösung:
- Teile die Daten in Trainings- und Testsätze auf.
- $\hat{f}$ an den Trainingsdatensatz anpassen
- den Fehler von $\hat{f}$ beim unbekannten Testdatensatz analysieren
- Generalisierungsfehler von $\hat{f} \approx$ Testdatensatzfehler von $\hat{f}$.
Bessere Modellbewertung mit Kreuzvalidierung
Der Testdatensatz sollte nicht angerührt werden, bis wir uns über die Leistung von $\hat{f}$ sicher sind.
$\hat{f}$-Bewertung mithilfe des Trainingsdatensatzes: verzerrte Schätzung, $\hat{f}$ hat bereits alle Trainingspunkte gesehen.
Lösung $\rightarrow$ Kreuzvalidierung (CV: Cross Validation):
K-Fold CV
Hold-Out CV
K-Fold CV
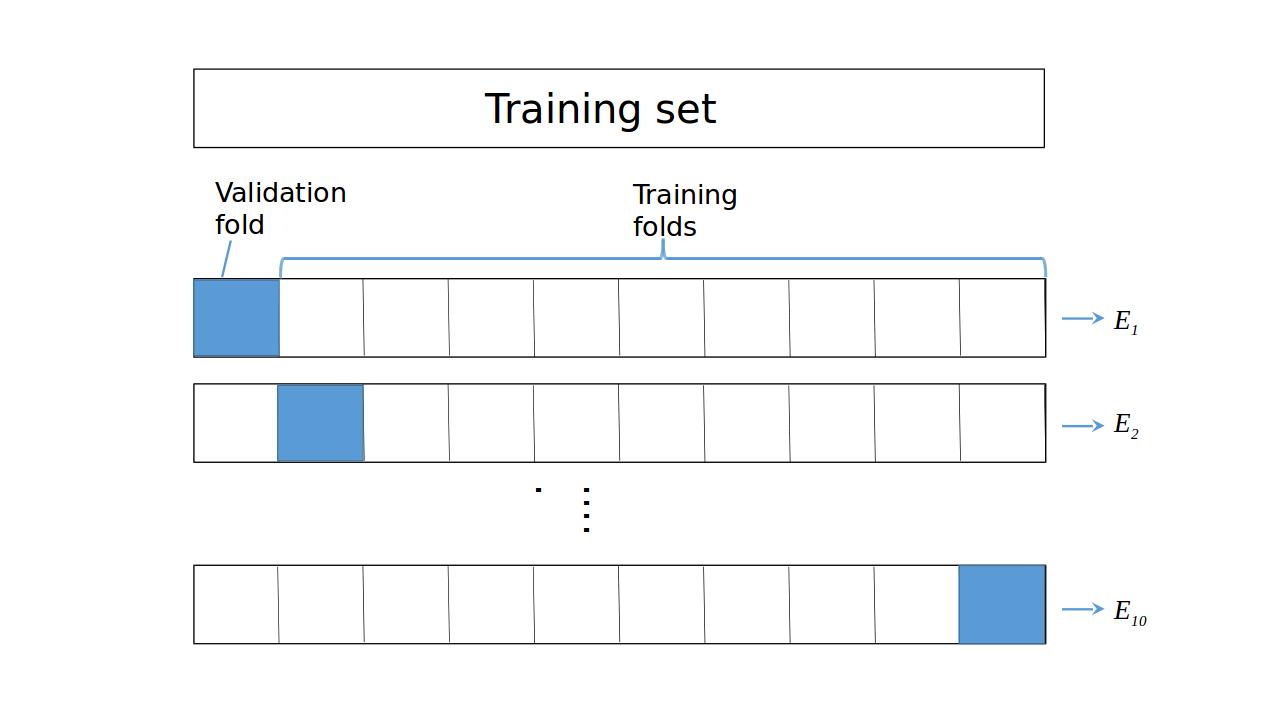
K-Fold CV
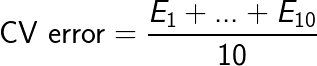
Diagnose von Varianzproblemen
Wenn $\hat{f}$ eine hohe Varianz hat:
CV-Fehler von $\hat{f}$ > Trainingsdatensatzfehler von $\hat{f}$.
- $\hat{f}$ führt Überanpassungen des Trainingsset aus. Um Überanpassung zu vermeiden:
- die Komplexität des Modells verringern
- zum Beispiel: maximale Tiefe verringern, minimale Anzahl von Samples pro Blatt erhöhen
- mehr Daten sammeln
Diagnose von Bias-Problemen
Wenn $\hat{f}$ einen starken Bias aufweist:
CV-Fehler von $\hat{f} \approx$ Fehler des Trainingsdatensatzes von $\hat{f} >>$ gewünschter Fehler
$\hat{f}$ führt Unteranpassung des Trainingsdatensatz aus. Um Unteranpassung zu beheben:
- die Komplexität des Modells erhöhen
- zum Beispiel: die maximale Tiefe erhöhen, die minimale Anzahl an Samples pro Blatt verringern
- mehr relevante Merkmale sammeln
K-Fold CV in sklearn auf dem Auto-Datensatz
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-Fold CV in sklearn auf dem Auto-Datensatz
# Evaluate the list of MSE ontained by 10-fold CV # Set n_jobs to -1 in order to exploit all CPU cores in computation MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' to the training set dt.fit(X_train, y_train) # Predict the labels of training set y_predict_train = dt.predict(X_train) # Predict the labels of test set y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training set MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test set MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Lass uns üben!
Maschinelles Lernen mit baumbasierten Modellen in Python

