Generalisierungsfehler
Maschinelles Lernen mit baumbasierten Modellen in Python

Elie Kawerk
Data Scientist
Überwachtes Lernen – Ein Blick hinter die Kulissen
- Überwachtes Lernen: $y =f(x)$, $f$ ist nicht bekannt.

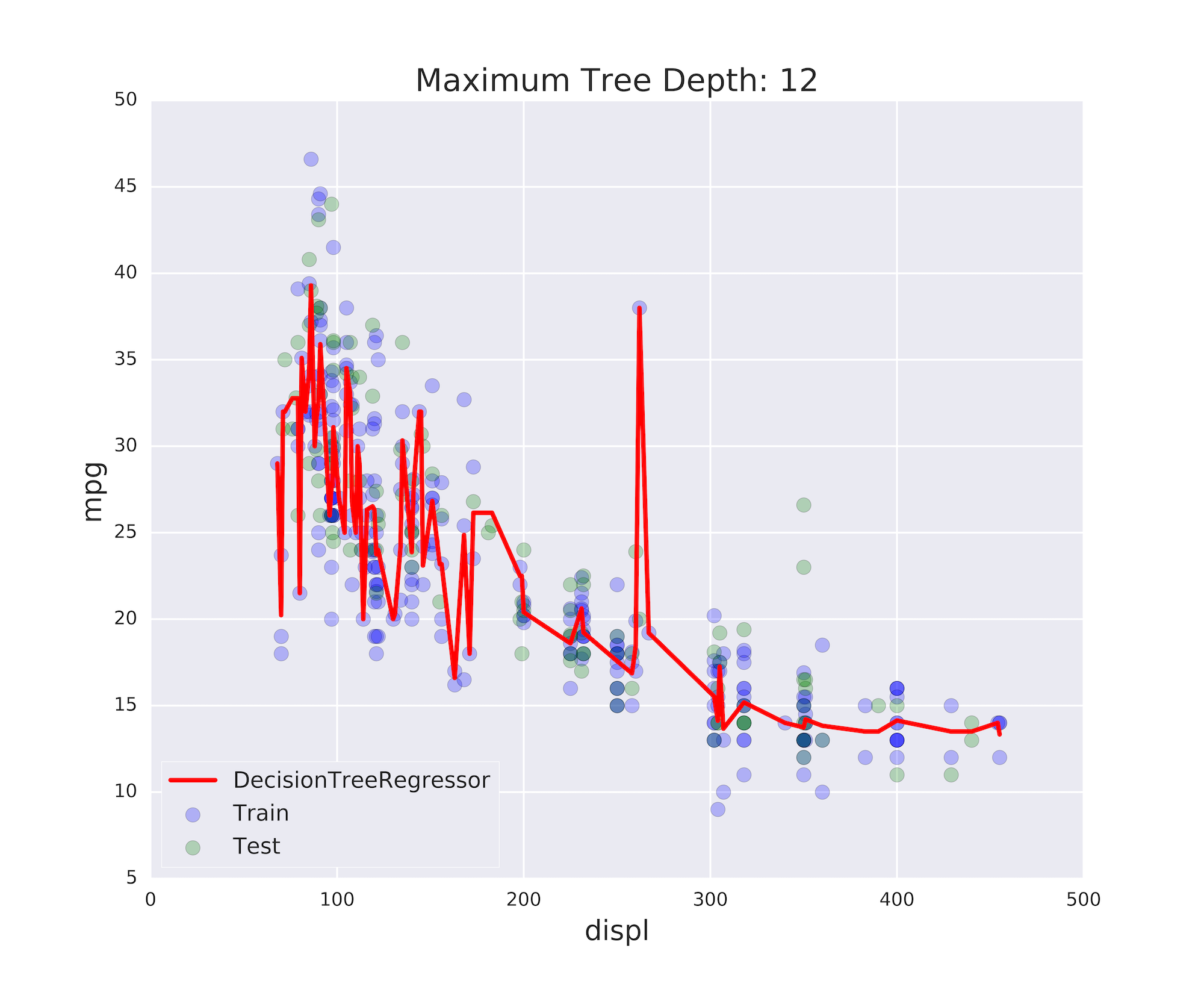
Überanpassung
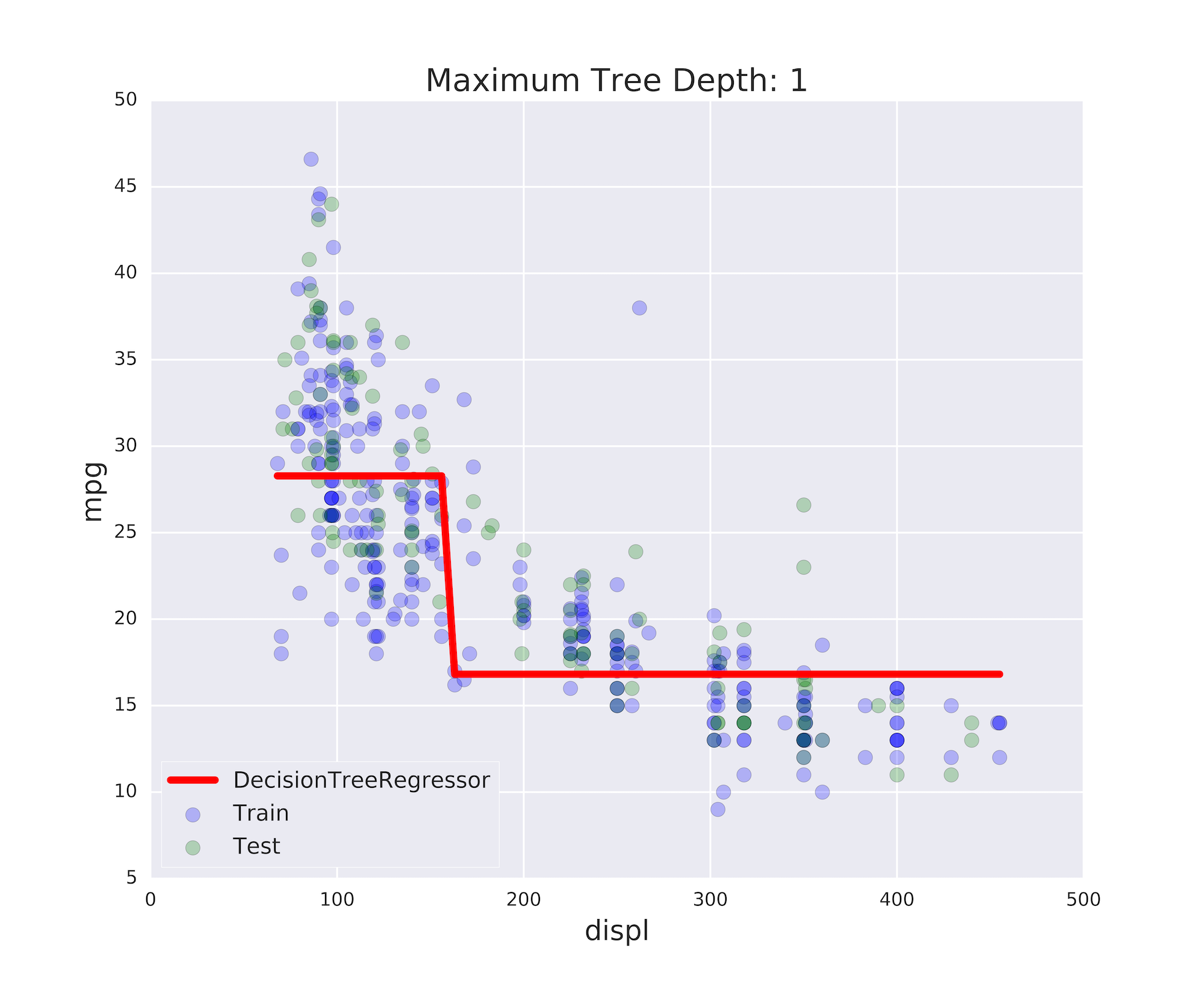
Unteranpassung
Bias
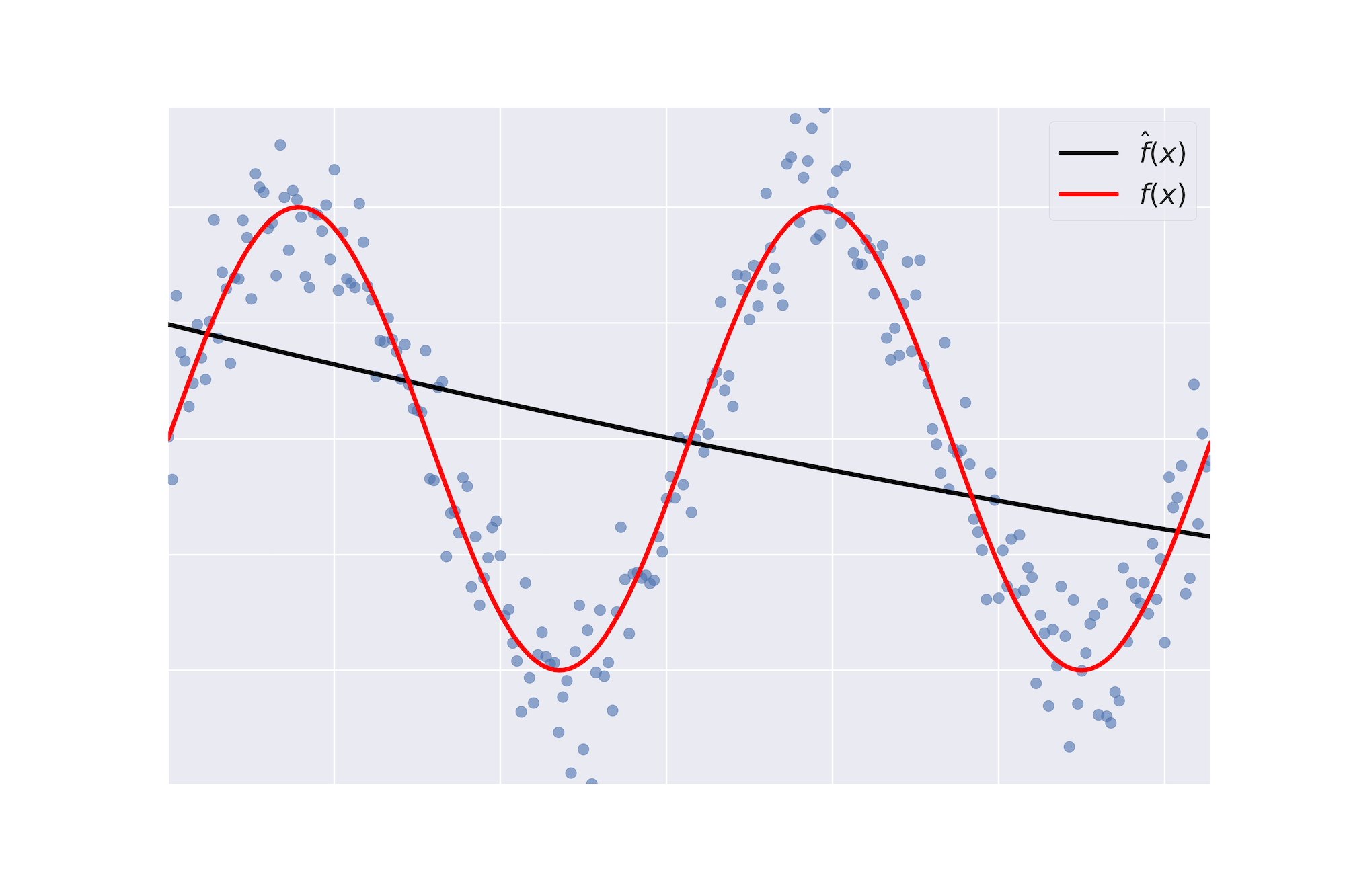
- Bias: Fehlerbegriff, der dir im Durchschnitt sagt, wie viel $\hat{f} \neq f$.
Varianz
- Varianz: Zeigt dir, wie unbeständig $\hat{f}$ über verschiedene Trainingsdatensätze hinweg ist.
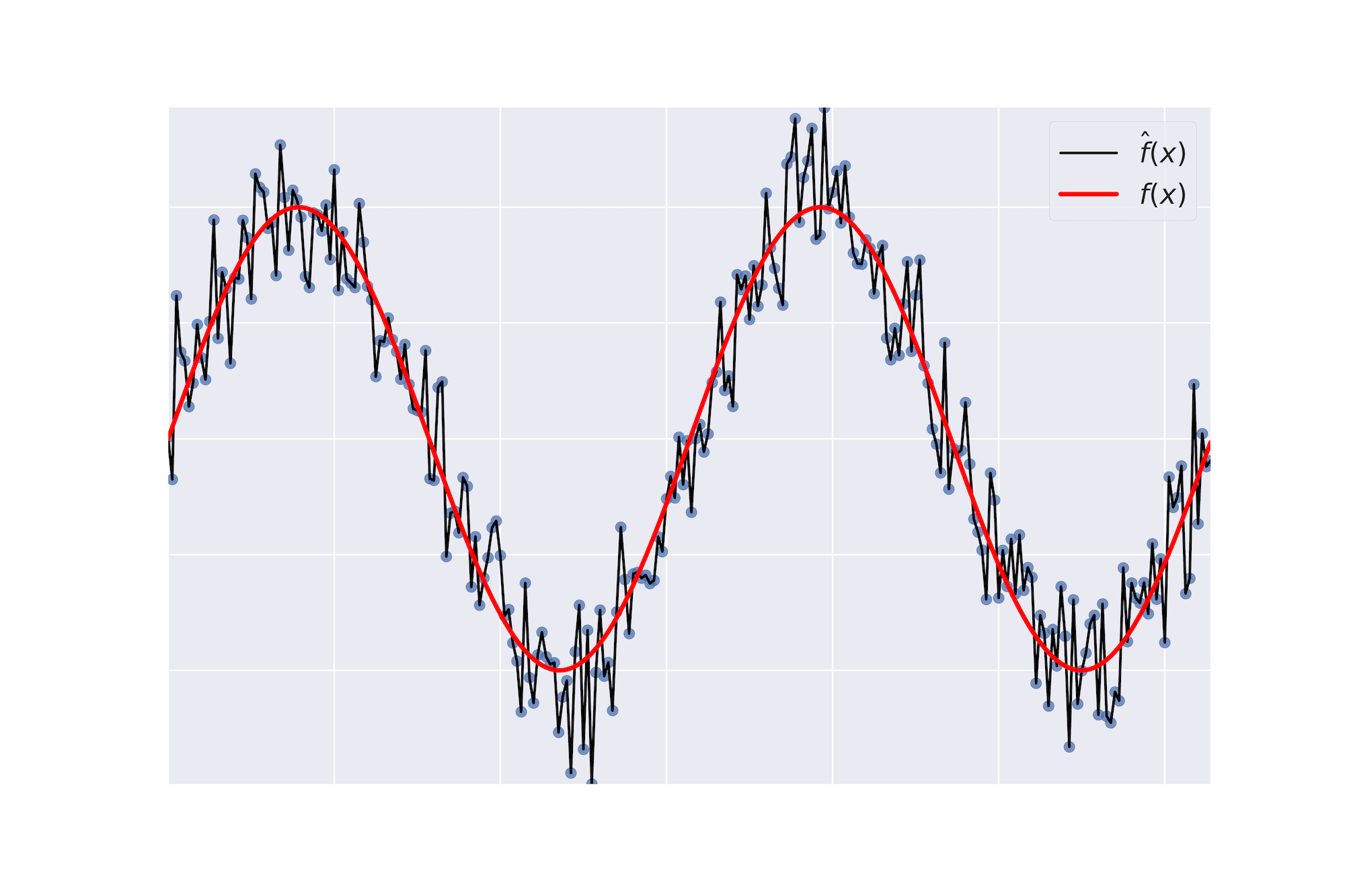
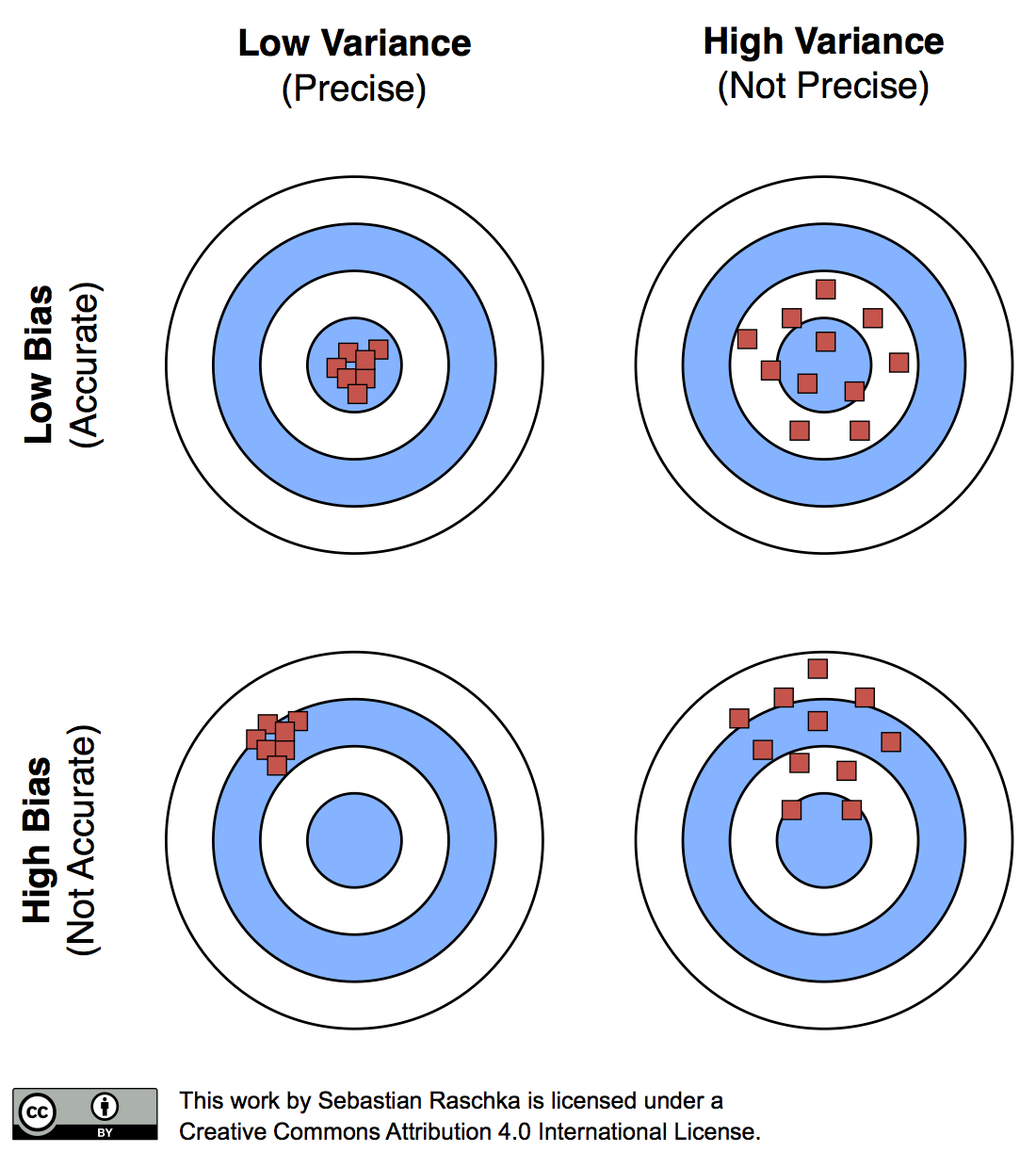
Bias-Varianz-Abwägung
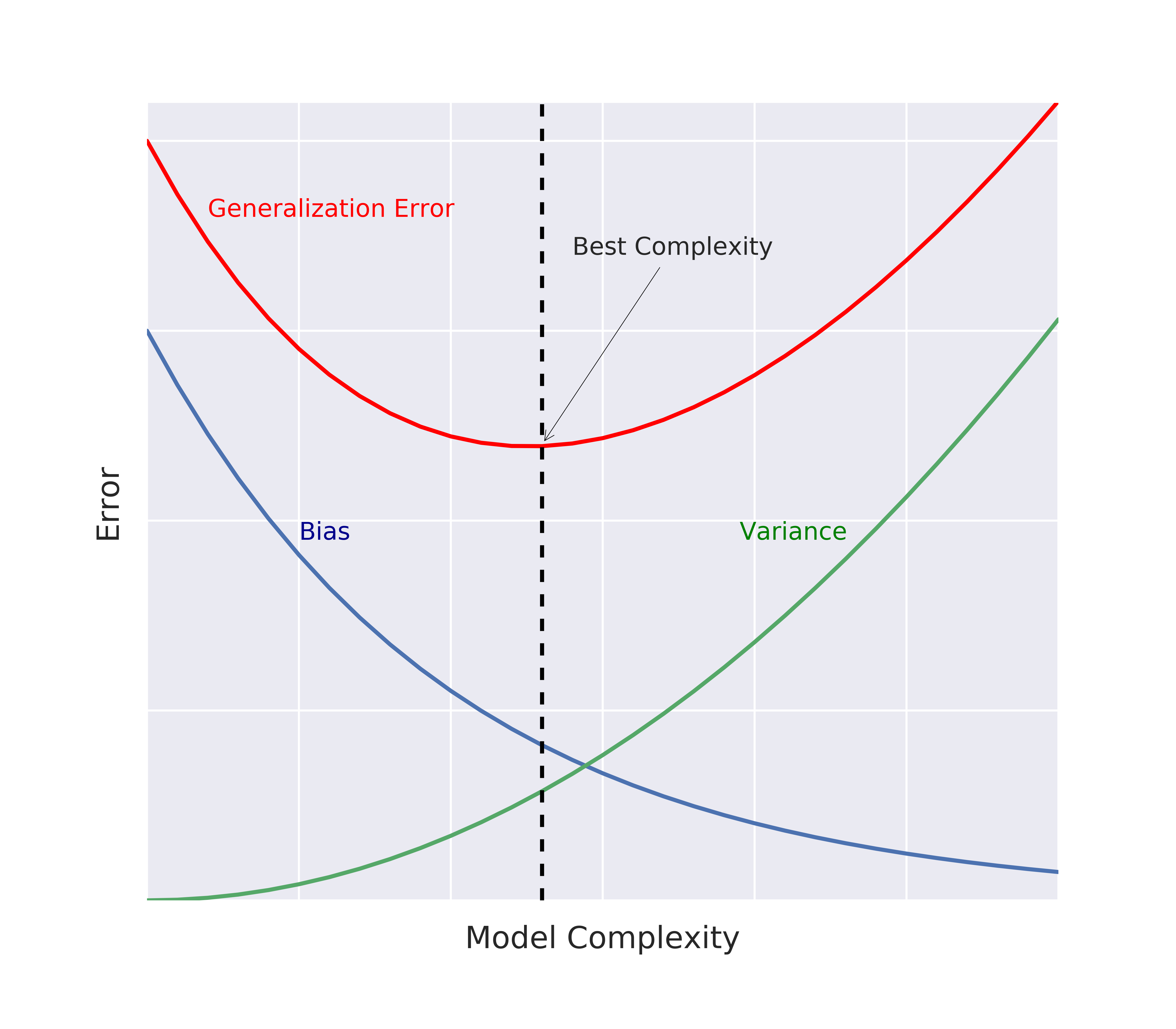
Bias-Varianz-Abwägung: Eine visuelle Erklärung