Ensemble Learning
Maschinelles Lernen mit baumbasierten Modellen in Python

Elie Kawerk
Data Scientist
Vorteile von CARTs
Einfach zu verstehen
Einfach zu interpretieren
Einfach anzuwenden
Flexibilität: die Fähigkeit, nichtlineare Abhängigkeiten zu beschreiben.
Vorverarbeitung: Es ist nicht nötig, Merkmale zu standardisieren oder zu normalisieren
Einschränkungen von CARTs
Klassifizierung: kann nur orthogonale Entscheidungsgrenzen erzeugen.
Reagieren empfindlich auf kleine Abweichungen im Trainingsdatensatz
Hohe Varianz: Uneingeschränkte CARTs können den Trainingsdatensatz überanpassen.
Lösung: Ensemble Learning
Ensemble Learning
Trainieren verschiedener Modelle mit demselben Datensatz
Jedes Modell trifft seine Vorhersagen
Metamodell: Sammelt die Vorhersagen einzelner Modelle.
Endgültige Prognose: robuster und weniger fehleranfällig
Beste Ergebnisse: Die Modelle sind auf unterschiedliche Weise gut.
Ensemble Learning: Eine visuelle Erklärung
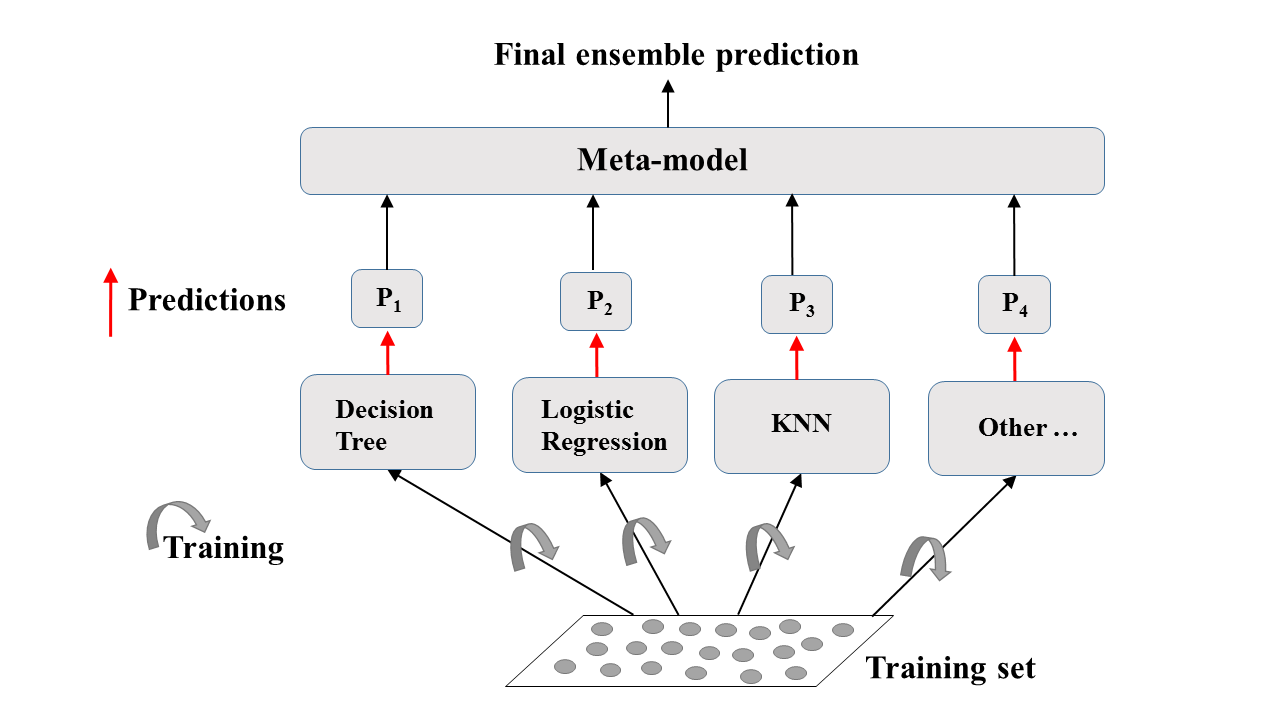
Ensemble-Learning in der Praxis: Voting Classifier
Binäre Klassifizierungsaufgabe.
$N$ Klassifikatoren machen Vorhersagen: $P_1$, $P_2$, ..., $P_N$ mit $P_i$ = 0 oder 1.
Metamodellvorhersage: Hard Voting
Hard Voting

Voting Classifier in sklearn (Brustkrebs-Datensatz)
# Import functions to compute accuracy and split data
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import models, including VotingClassifier meta-model
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
# Set seed for reproducibility
SEED = 1
Voting Classifier in sklearn (Brustkrebs-Datensatz)
# Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, random_state= SEED) # Instantiate individual classifiers lr = LogisticRegression(random_state=SEED) knn = KNN() dt = DecisionTreeClassifier(random_state=SEED)# Define a list called classifier that contains the tuples (classifier_name, classifier) classifiers = [('Logistic Regression', lr), ('K Nearest Neighbours', knn), ('Classification Tree', dt)]
# Iterate over the defined list of tuples containing the classifiers
for clf_name, clf in classifiers:
#fit clf to the training set
clf.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = clf.predict(X_test)
# Evaluate the accuracy of clf on the test set
print('{:s} : {:.3f}'.format(clf_name, accuracy_score(y_test, y_pred)))
Logistic Regression: 0.947
K Nearest Neighbours: 0.930
Classification Tree: 0.930
Voting Classifier in sklearn (Brustkrebs-Datensatz)
# Instantiate a VotingClassifier 'vc'
vc = VotingClassifier(estimators=classifiers)
# Fit 'vc' to the traing set and predict test set labels
vc.fit(X_train, y_train)
y_pred = vc.predict(X_test)
# Evaluate the test-set accuracy of 'vc'
print('Voting Classifier: {.3f}'.format(accuracy_score(y_test, y_pred)))
Voting Classifier: 0.953
Lass uns üben!
Maschinelles Lernen mit baumbasierten Modellen in Python

