Entscheidungsbaum für die Klassifizierung
Maschinelles Lernen mit baumbasierten Modellen in Python

Elie Kawerk
Data Scientist
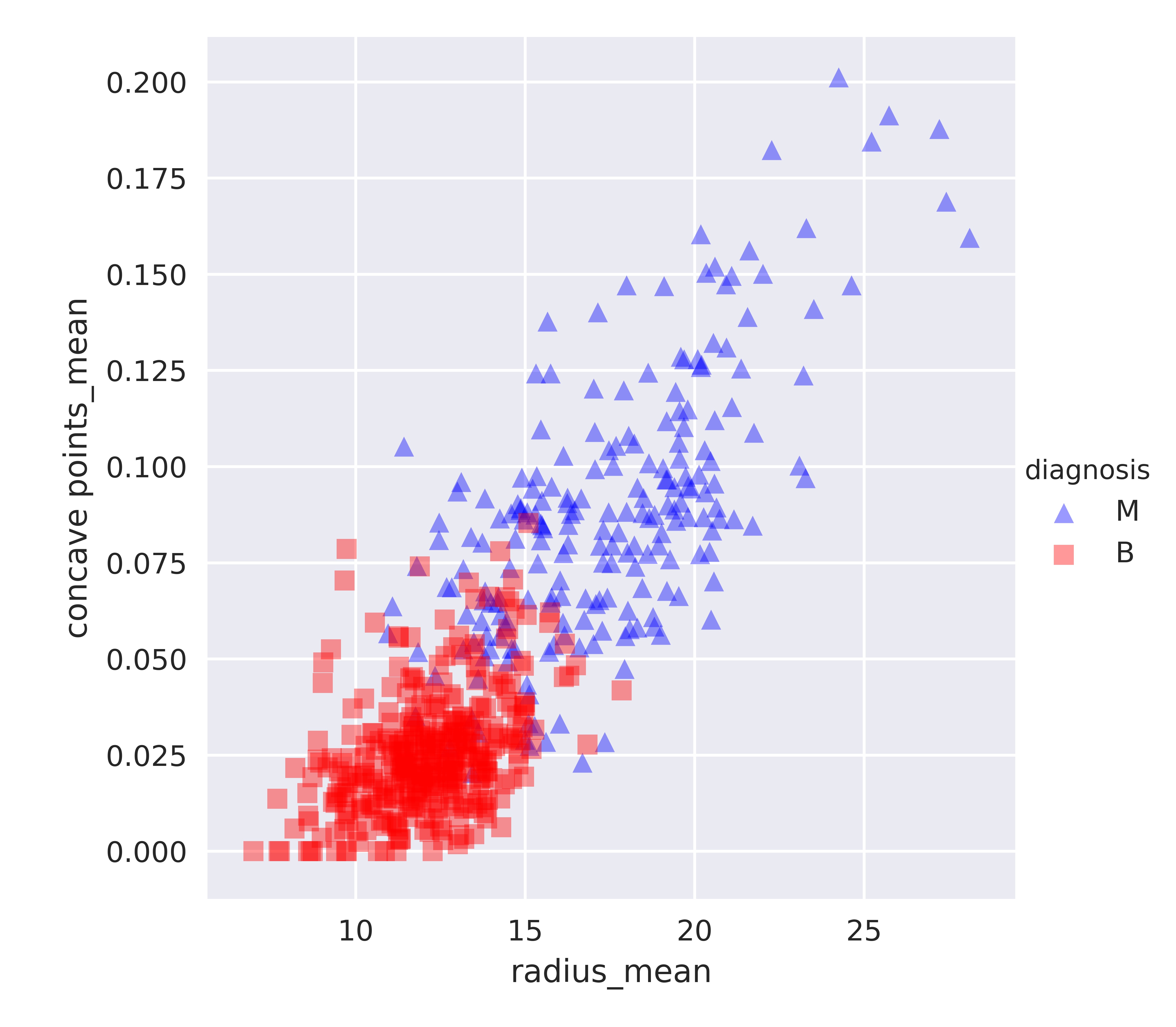
Brustkrebs-Datensatz in 2D
Entscheidungsbaum-Diagramm

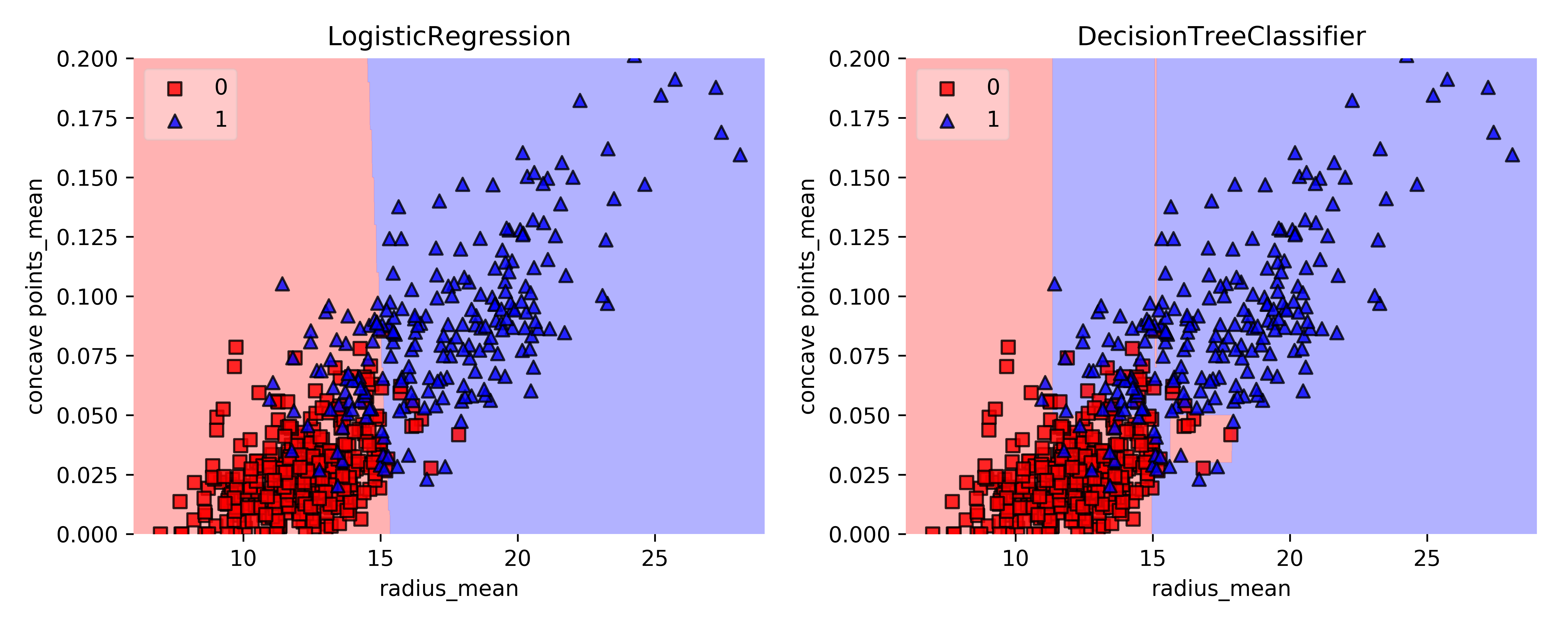
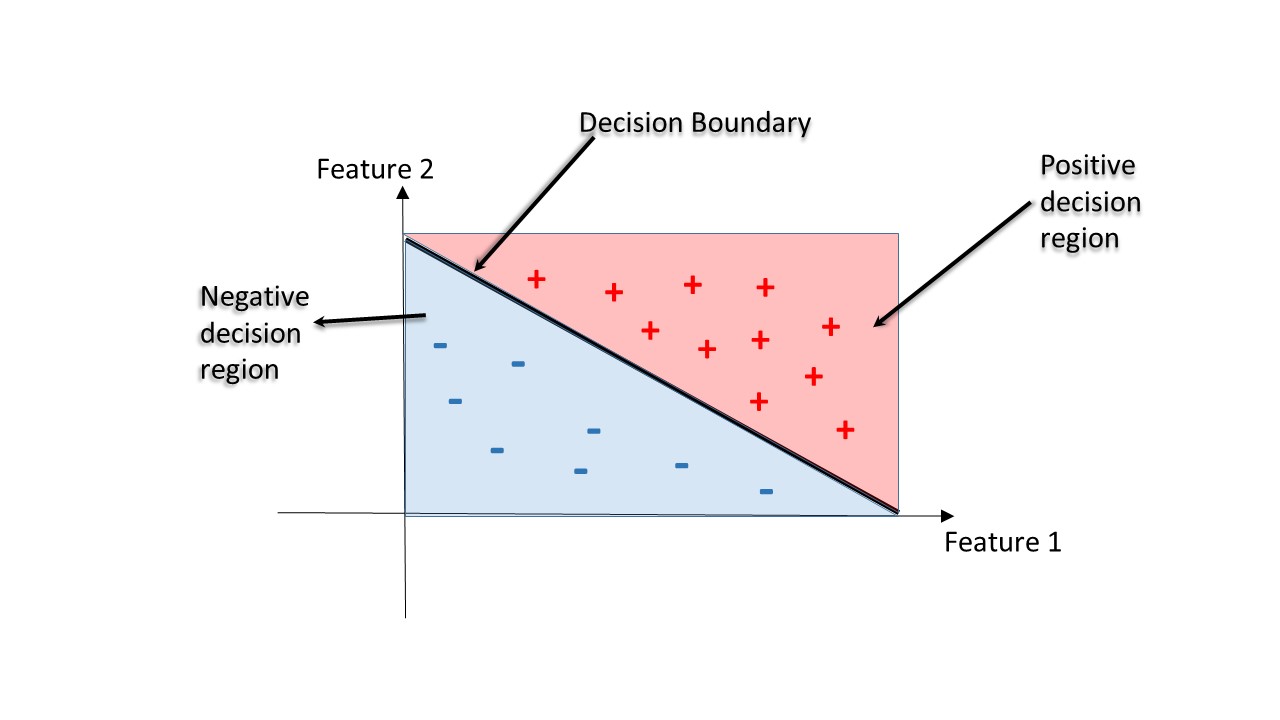
Decision Regions
Decision region: Der Bereich im Merkmalsraum, wo alle Fälle zu genau einem Klassenlabel gehören.
Decision Boundary: Die Fläche, die verschiedene Entscheidungsbereiche voneinander trennt.
Decision Regions: CART vs. Lineares Modell