Data Pipelines on Kubernetes
Introduction to Kubernetes

Frank Heilmann
Platform Architect and Freelance Instructor
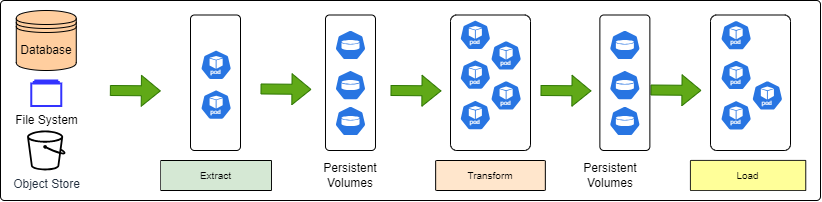
What are Data Pipelines?

Data Pipelines on Kubernetes
Introduction to Kubernetes
Frank Heilmann
Platform Architect and Freelance Instructor

