Explaining unsupervised models
Explainable AI in Python

Fouad Trad
Machine Learning Engineer
Clustering
Group similar data points without pre-defined labels
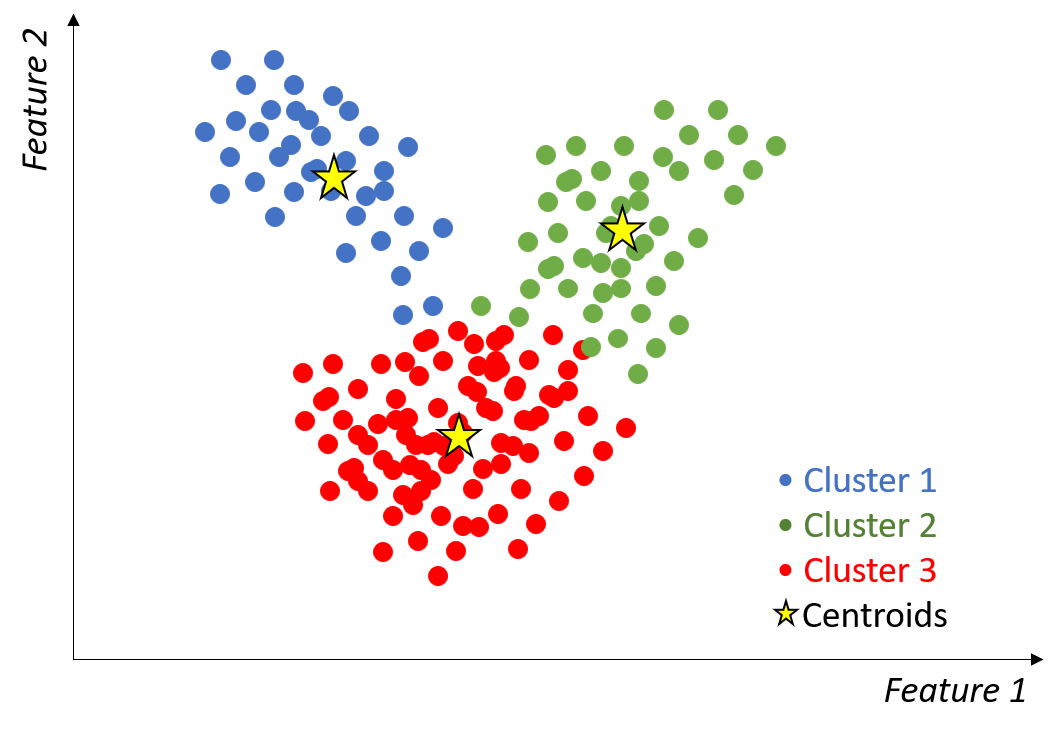
Silhouette score

Silhouette score

Feature impact on cluster quality

Feature impact on cluster quality

Feature impact on cluster quality

- $\text{Impact(}f) > 0$ → positive contribution for $f$
- $\text{Impact(}f) < 0$ → $f$ introduces noise
Adjusted rand index (ARI)
- Measures how well cluster assignments match

- Maximum ARI = 1 → perfect cluster alignment
Adjusted rand index (ARI)
- Measures how well cluster assignments match
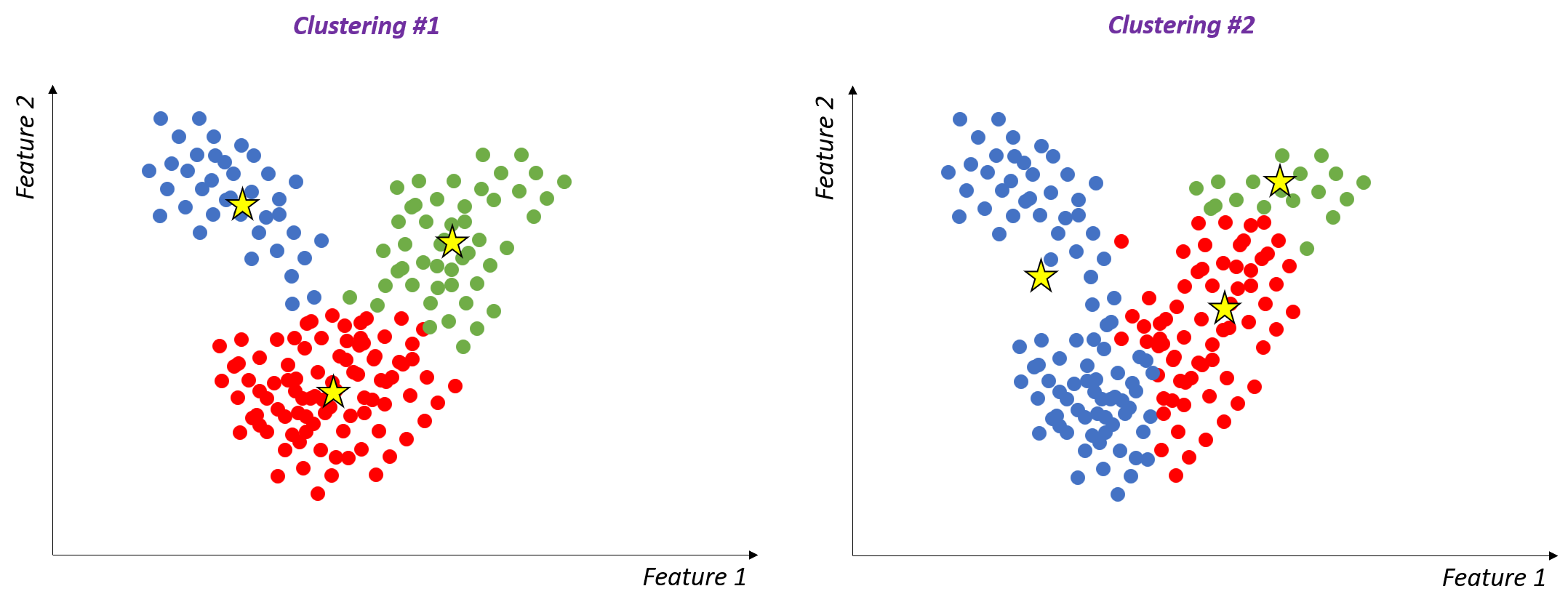
- Maximum ARI = 1 → perfect cluster alignment
- Lower ARI → greater difference in clusterings

