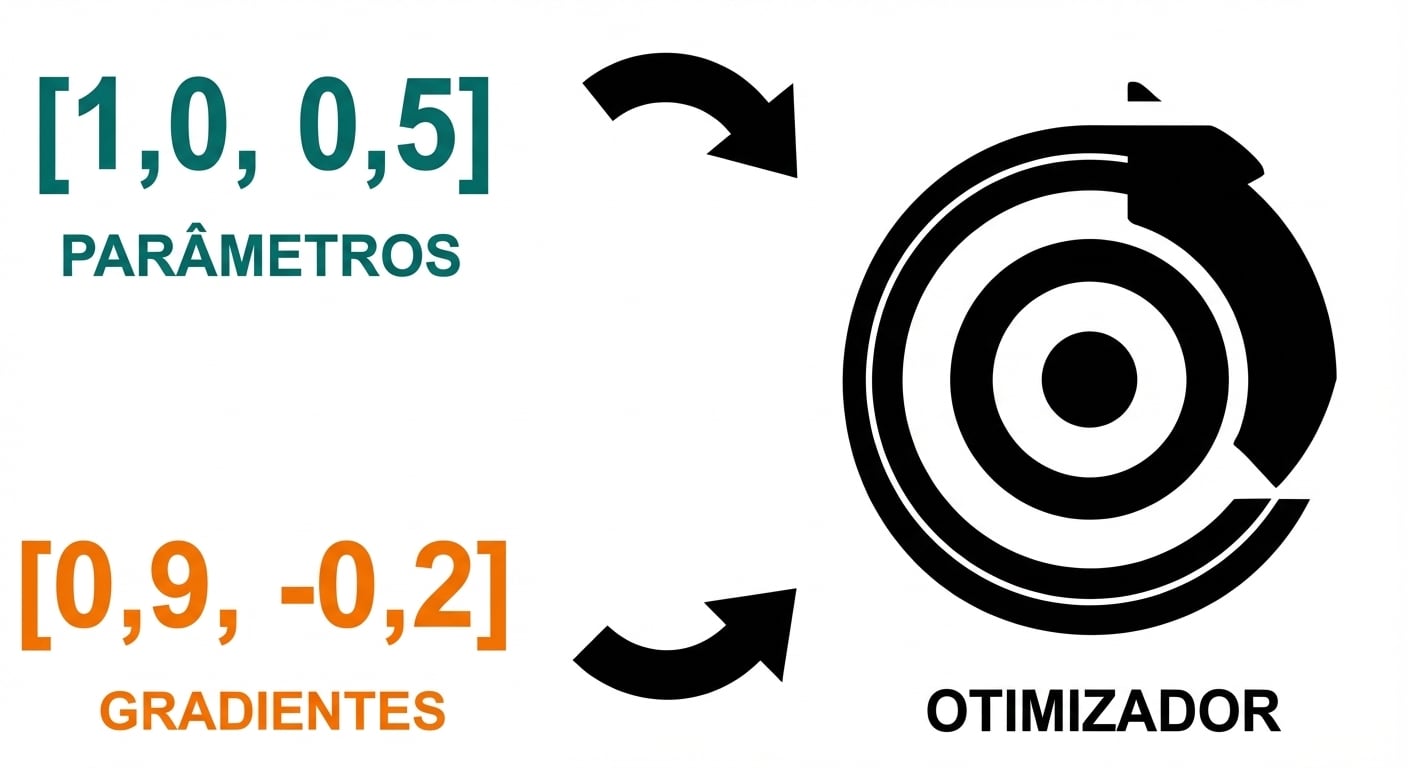
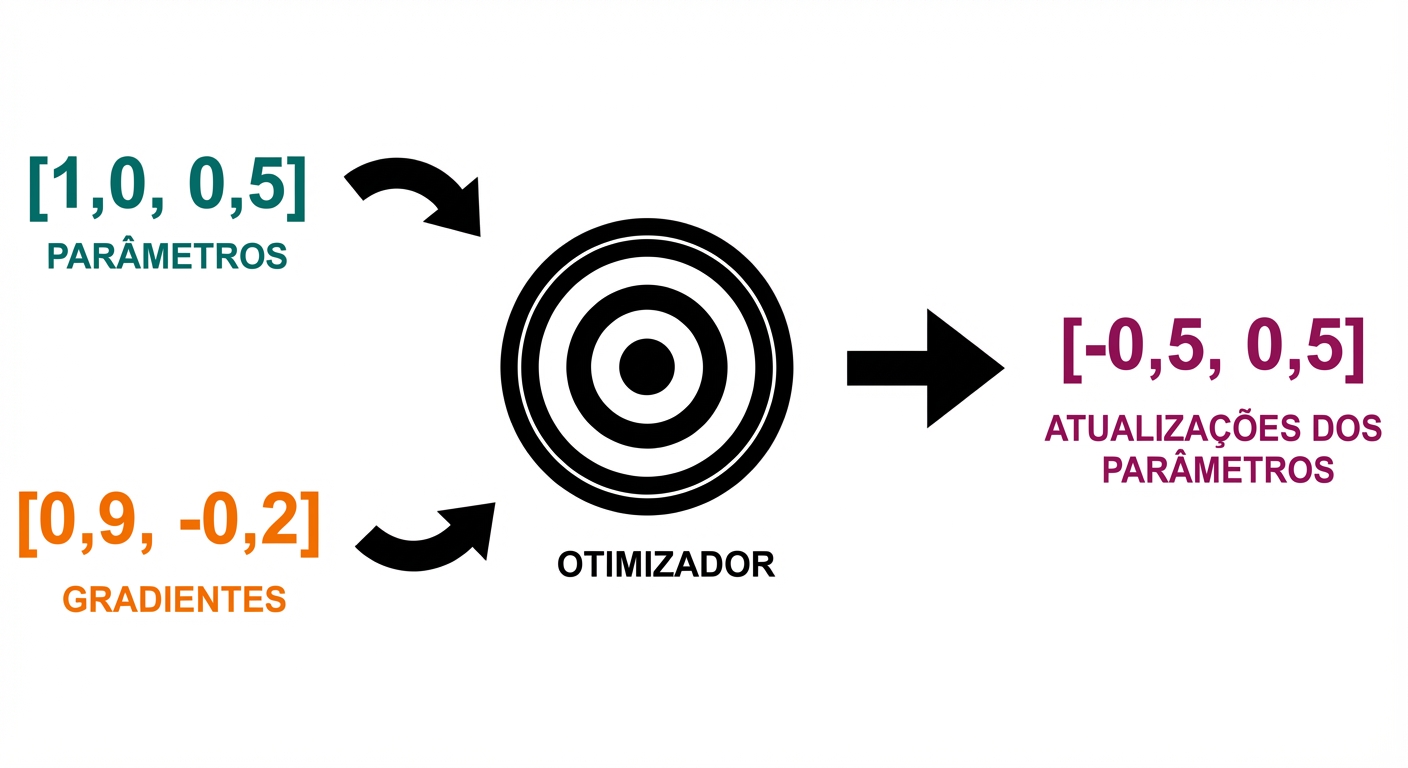
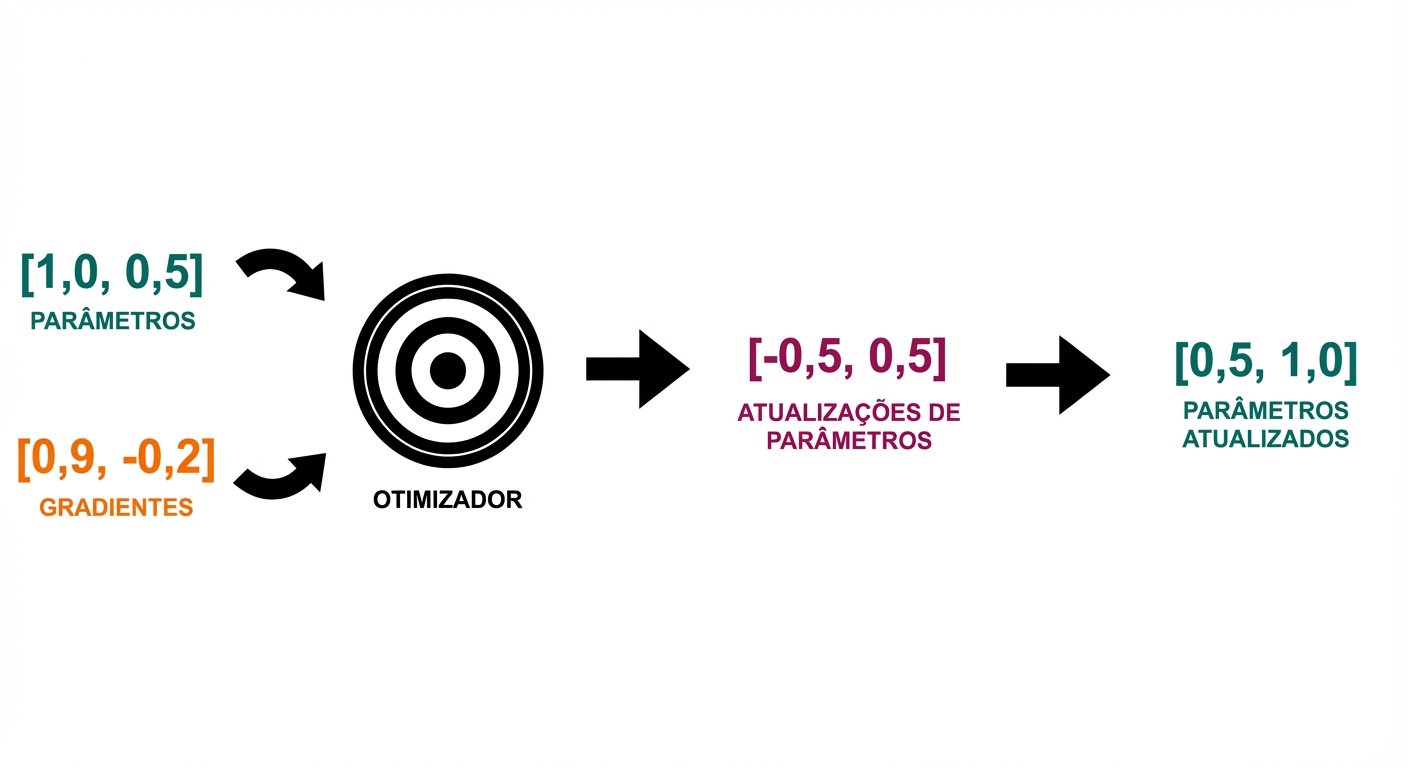
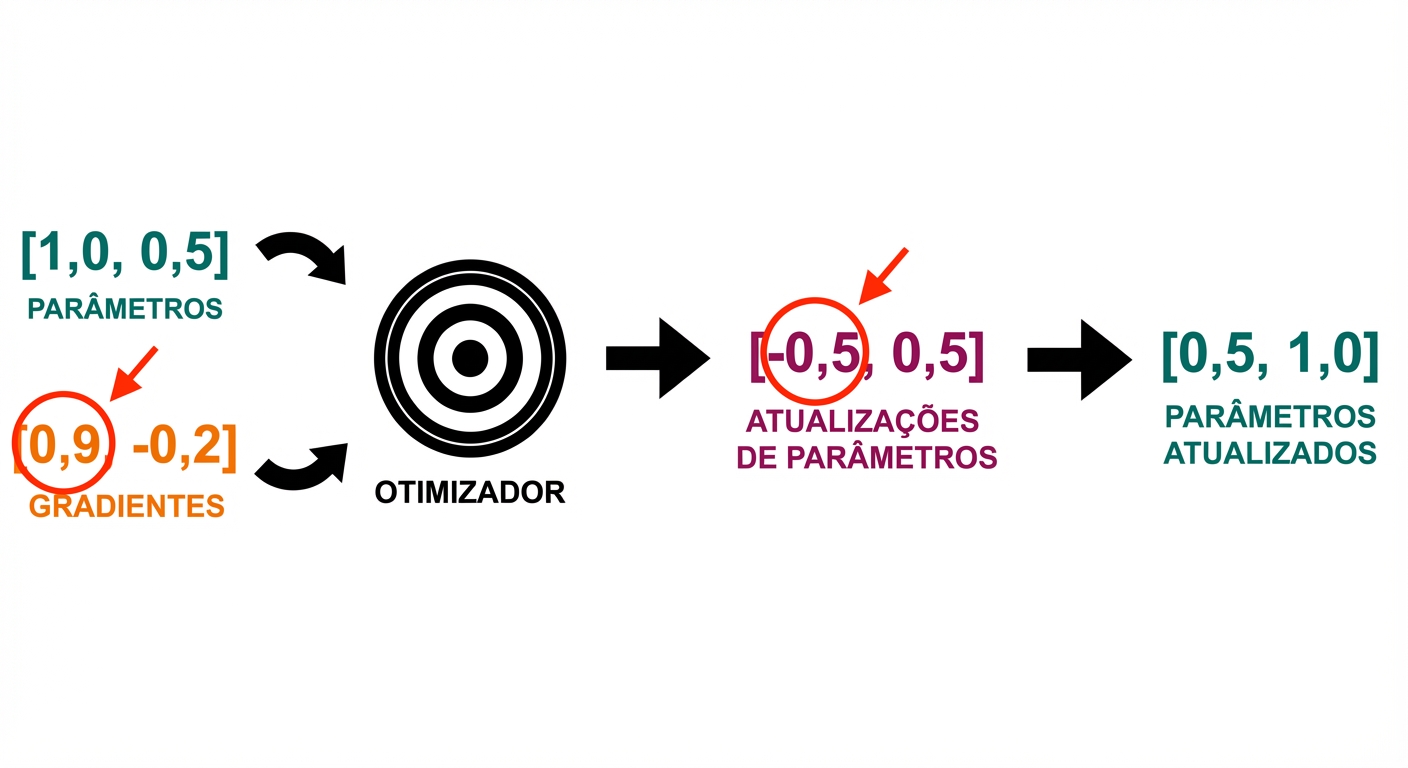
Loop de treino
import torch.nn as nn
import torch.optim as optim
criterion = nn.BCELoss()
otimizer = optim.SGD(net.parameters(), lr=0.01)
for epoch in range(1000):
for features, labels in dataloader_train:
optimizer.zero_grad()
outputs = net(features)
loss = criterion(
outputs, labels.view(-1, 1)
)
loss.backward()
optimizer.step()
- Defina função de perda e otimizador
BCELoss para classificação binária- Otimizador
SGD
- Itere por épocas e batches de treino
- Zere os gradientes
- Passagem forward: obtenha saídas
- Calcule a perda
- Calcule os gradientes
- Passo do otimizador: atualize parâmetros