Desaparecimento e explosão de gradientes
Aprendizagem profunda intermediária com PyTorch

Michal Oleszak
Machine Learning Engineer
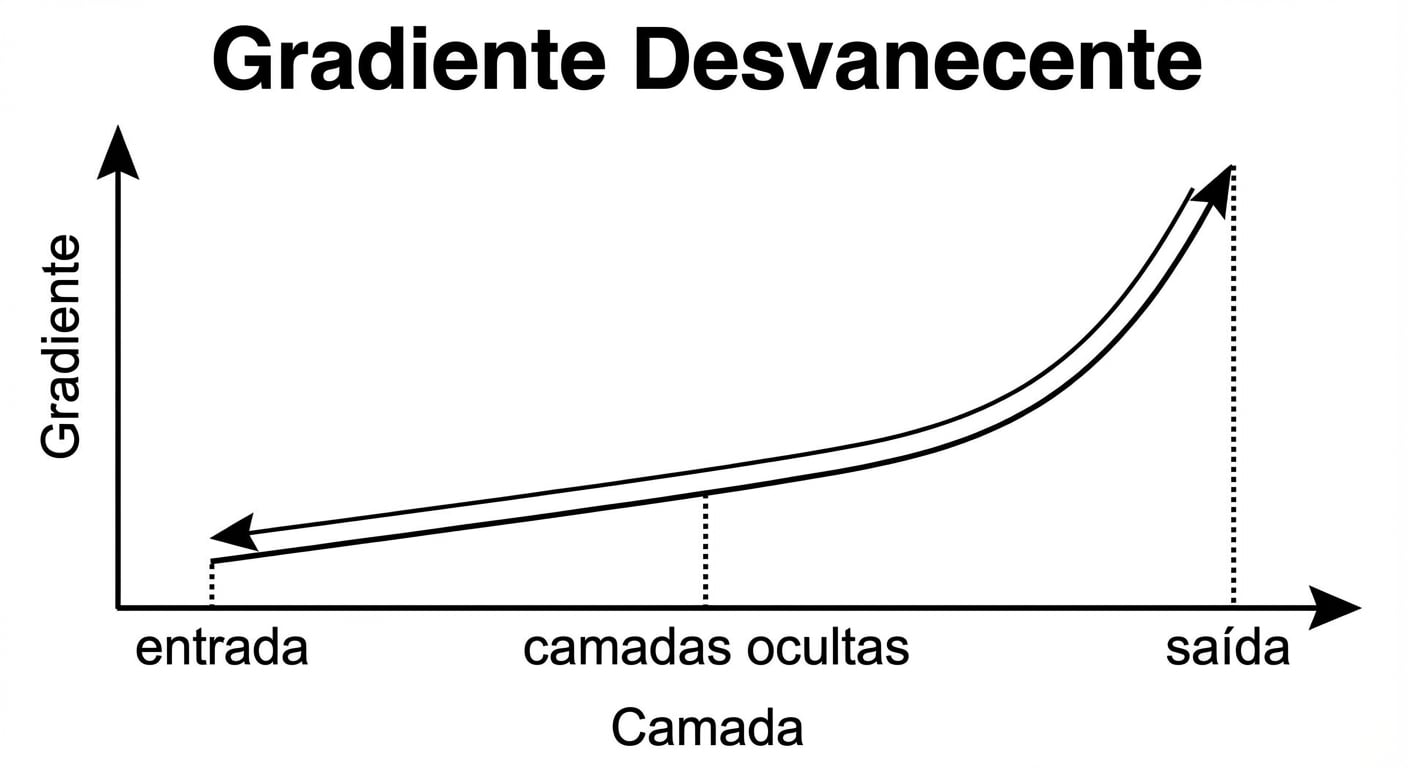
Gradientes que somem
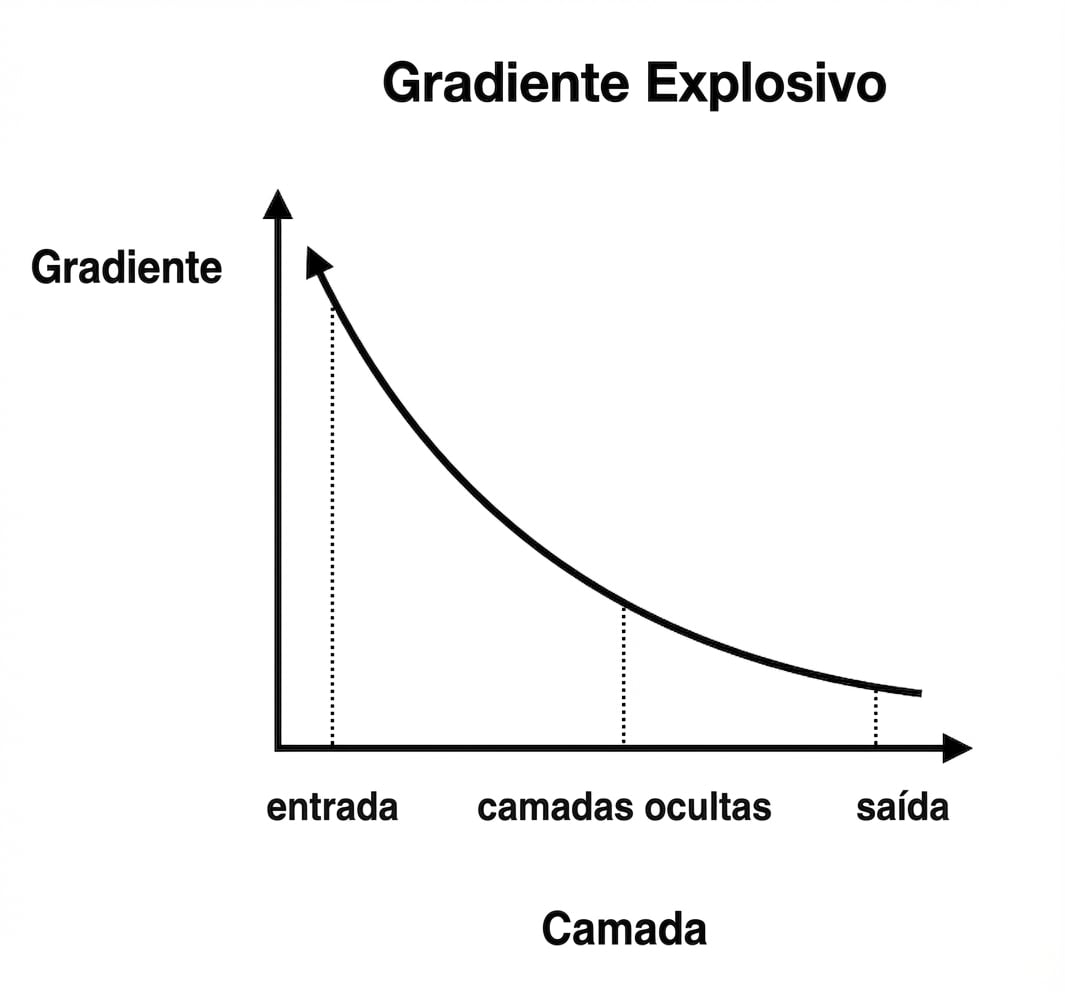
Gradientes que explodem
Solução para gradientes instáveis
- Inicialização correta dos pesos
- Boas ativações
- Batch normalization
Funções de ativação
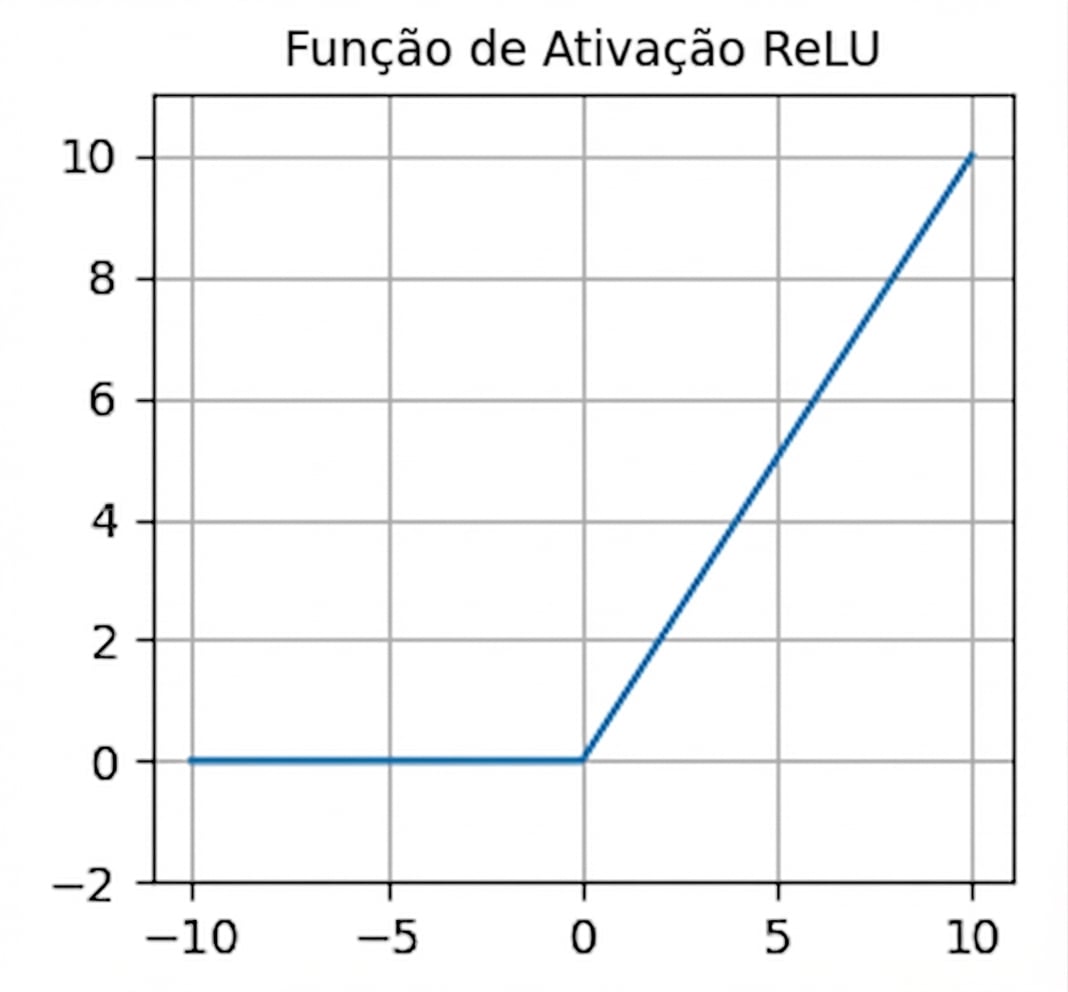
- Geralmente a ativação padrão
nn.functional.relu()- Zero para entradas negativas — neurônios mortos
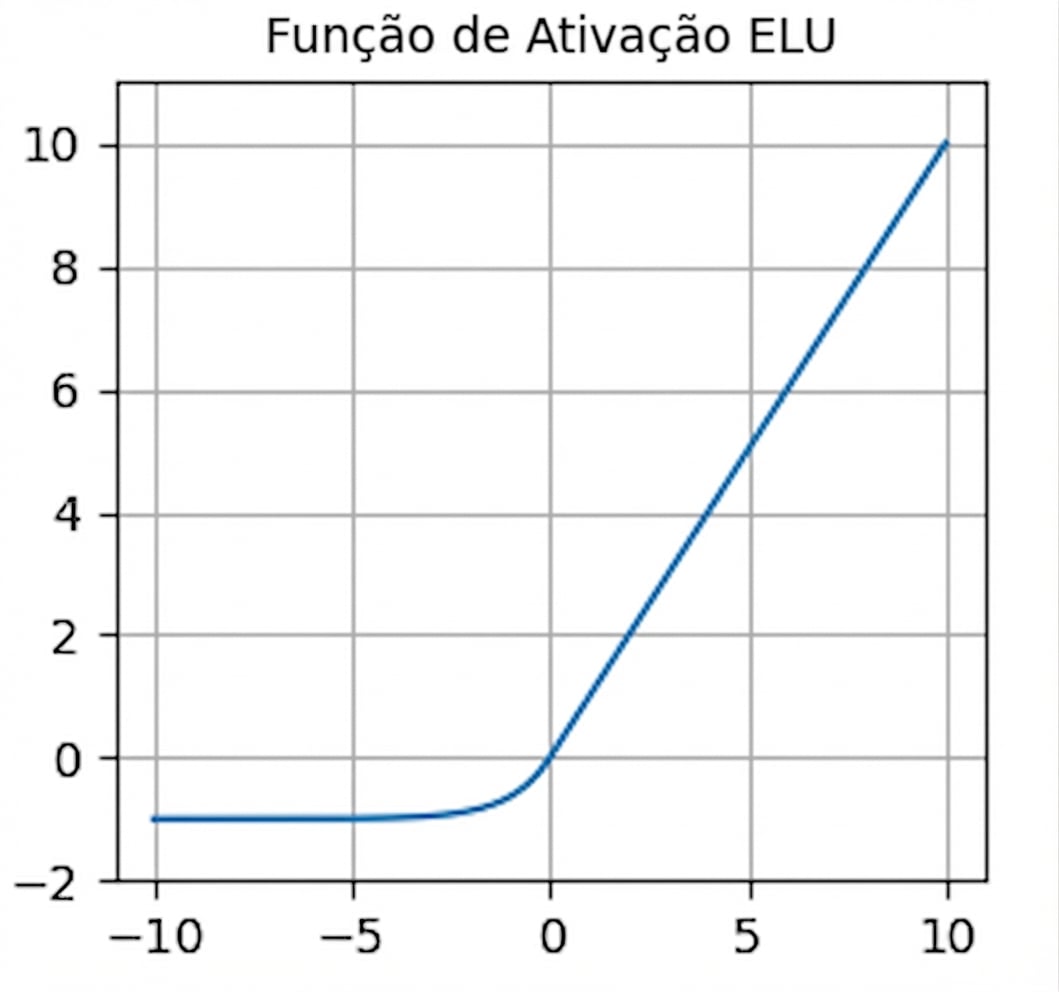
nn.functional.elu()- Gradientes não nulos para valores negativos — evita neurônios mortos
- Saída média perto de zero — ajuda contra gradientes que somem

