Bucle de entrenamiento
import torch.nn as nn
import torch.optim as optim
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
for epoch in range(1000):
for features, labels in dataloader_train:
optimizer.zero_grad()
outputs = net(features)
loss = criterion(
outputs, labels.view(-1, 1)
)
loss.backward()
optimizer.step()
- Define la función de pérdida y el optimizador.
BCELoss para clasificación binaria- Optimizador
- Repite las épocas y los lotes de entrenamiento.
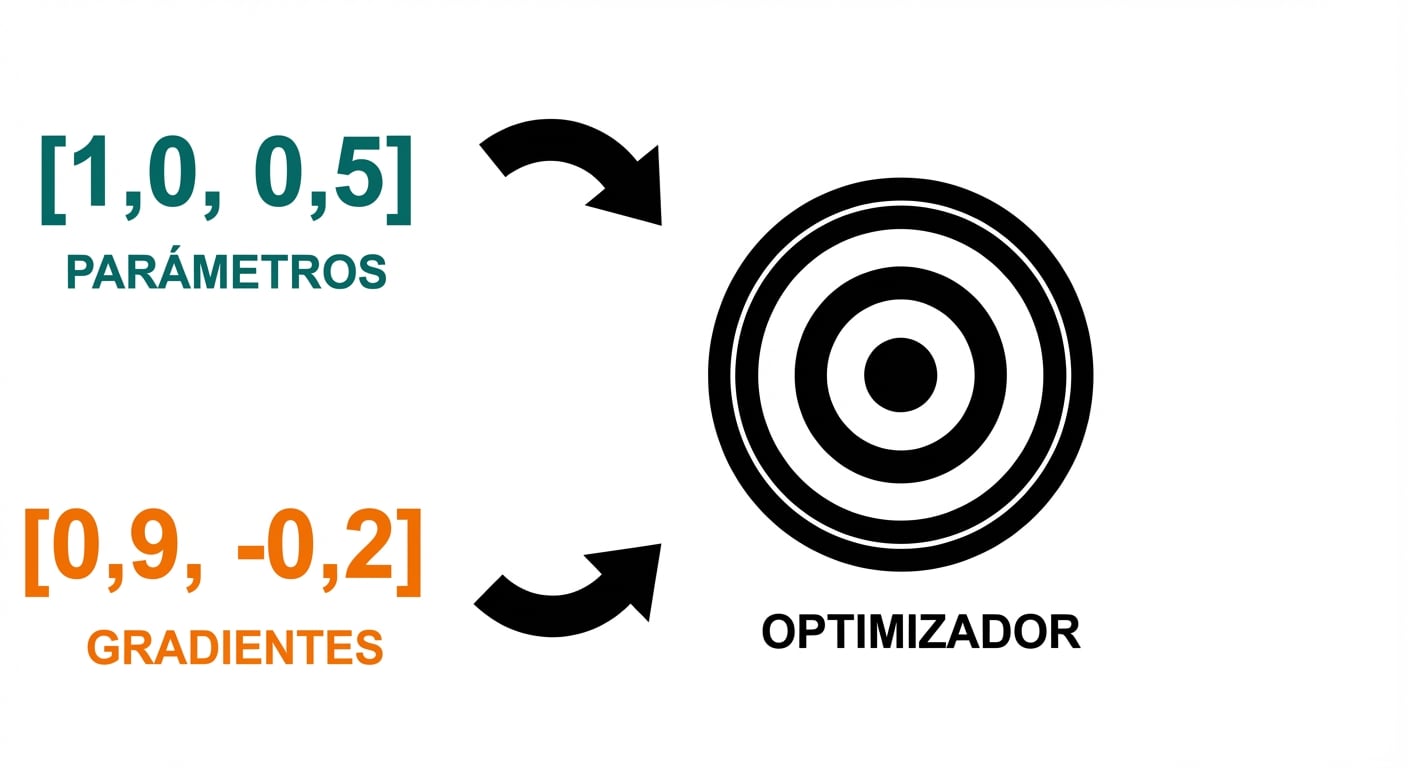
- Gradientes claros
- Pase hacia adelante: obtener los resultados del modelo
- Calcular la pérdida
- Calcular gradientes
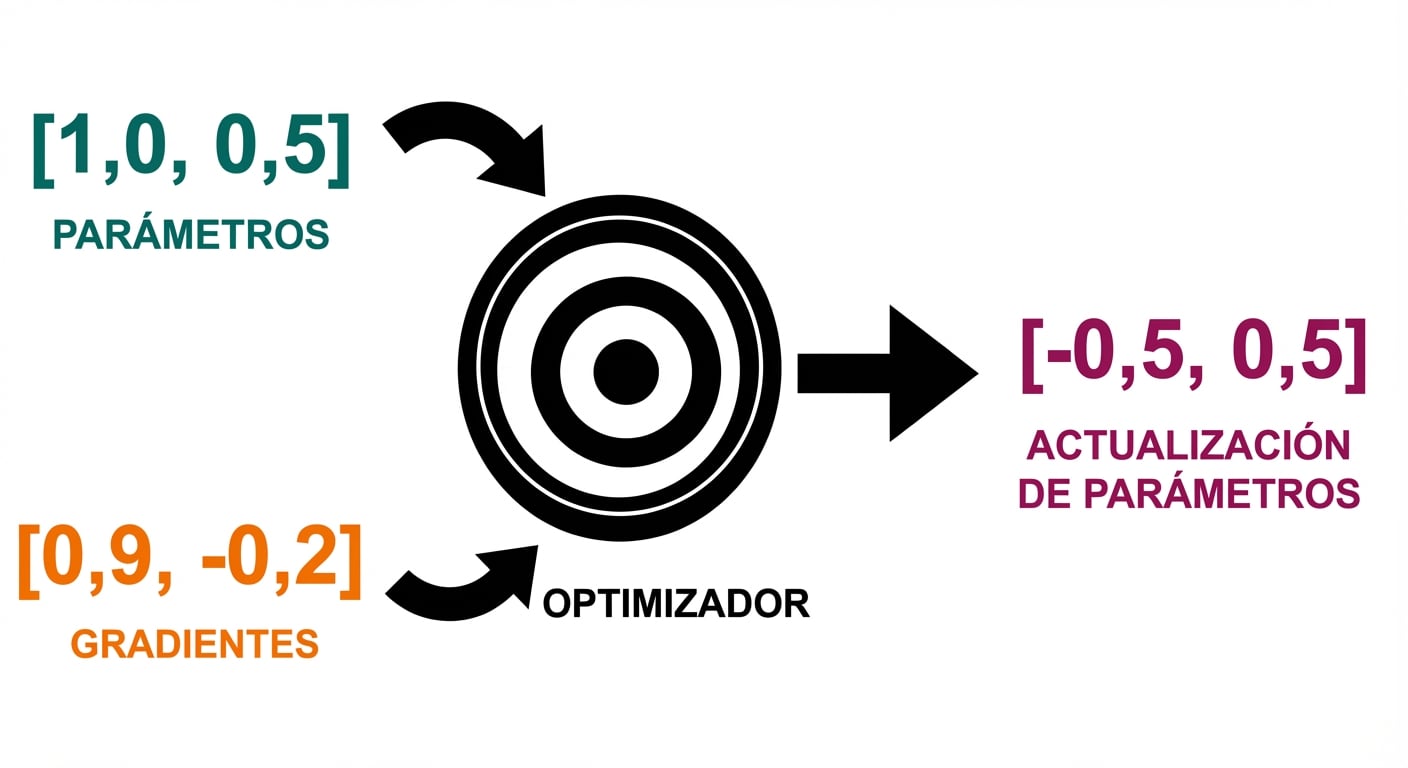
- Paso del optimizador: actualizar parámetros