Desvanecimiento y explosión de gradientes
Aprendizaje profundo intermedio con PyTorch

Michal Oleszak
Machine Learning Engineer
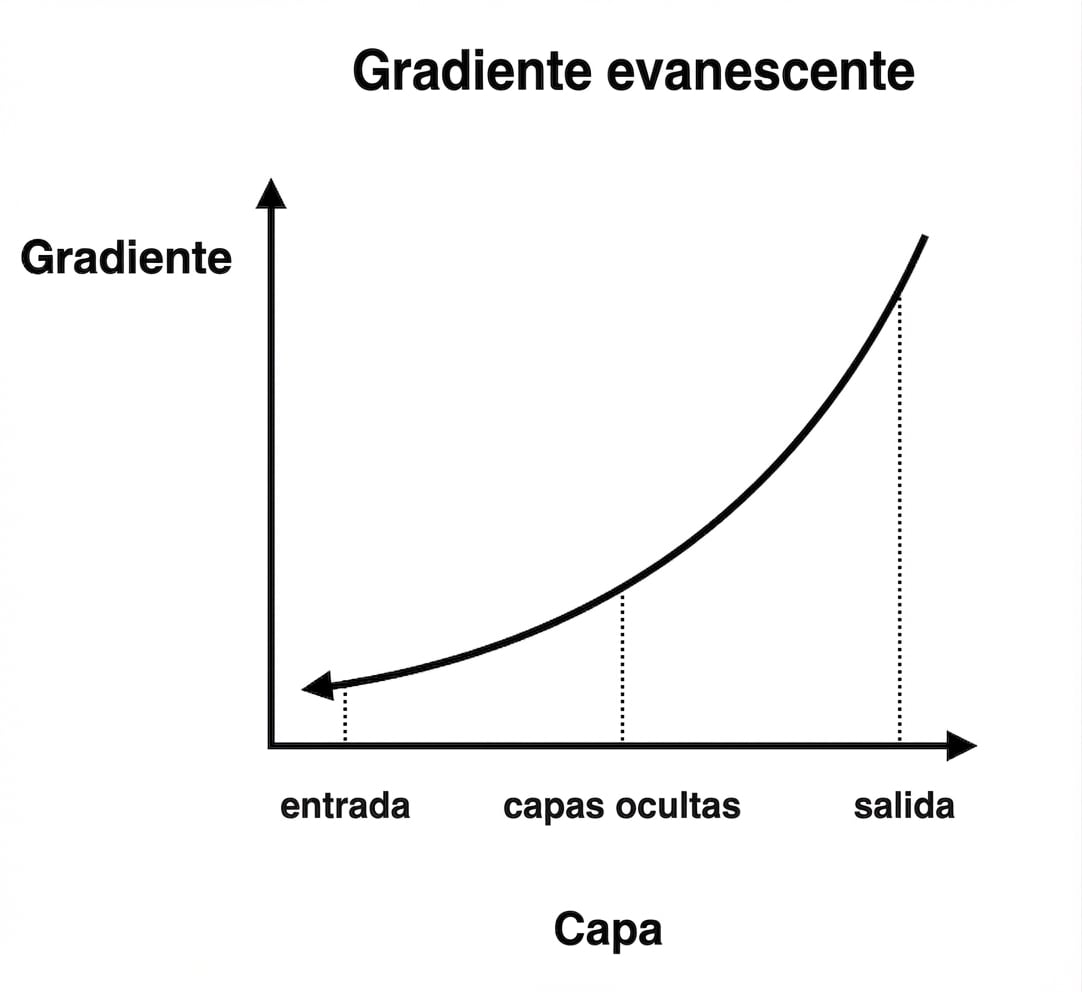
Gradientes de desaparición
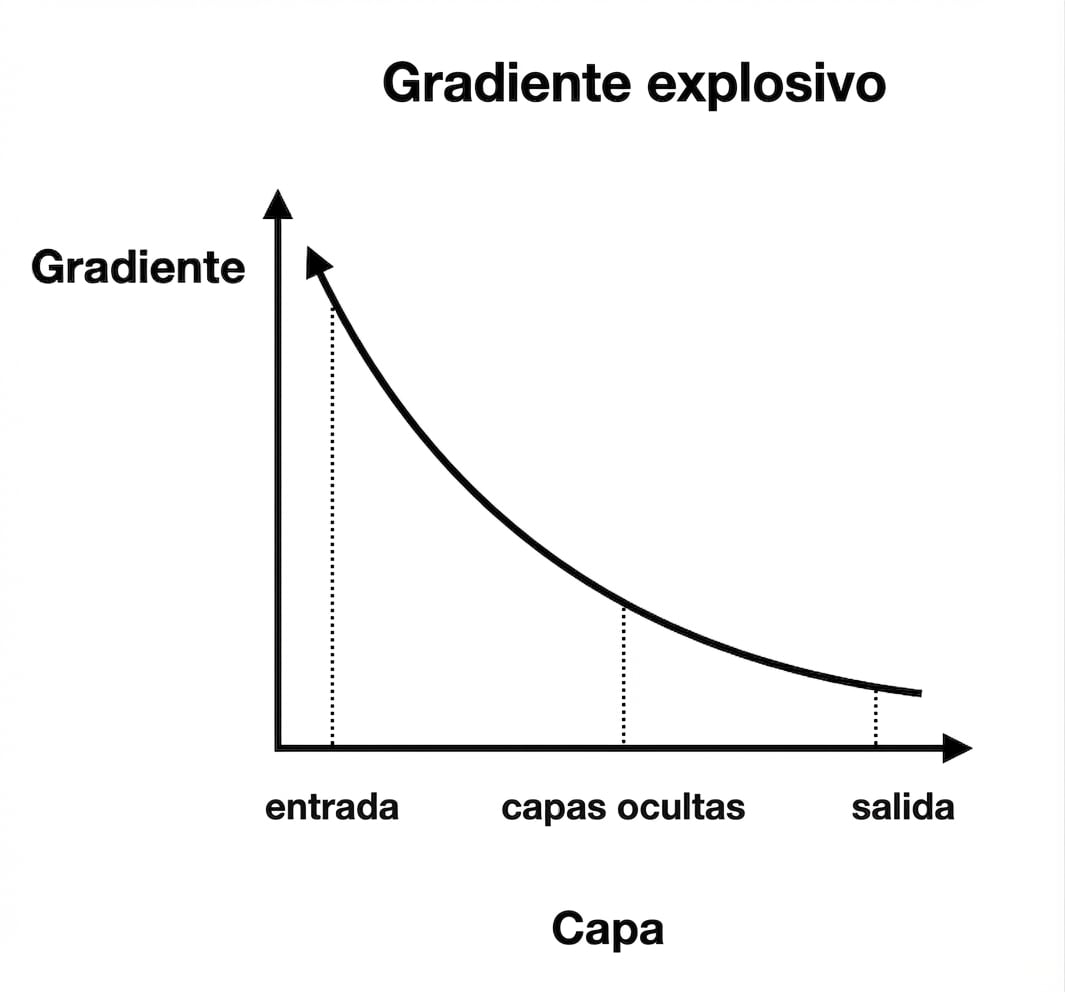
Gradientes explosivos
Solución a gradientes inestables
- Inicialización correcta de los pesos
- Buenas activaciones
- Normalización por lotes
Funciones de activación
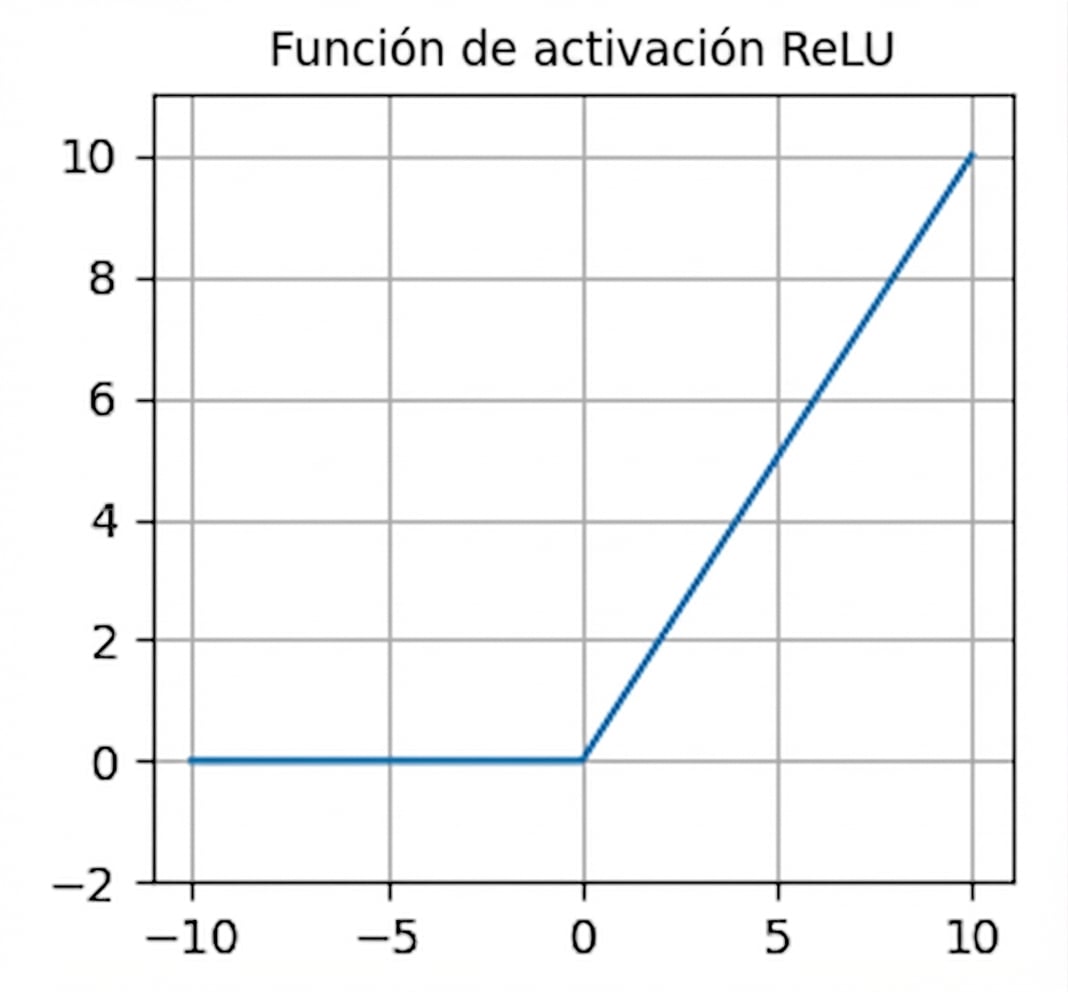
- A menudo utilizado como activación predeterminada.
nn.functional.relu()- Cero para entradas negativas: neuronas moribundas.
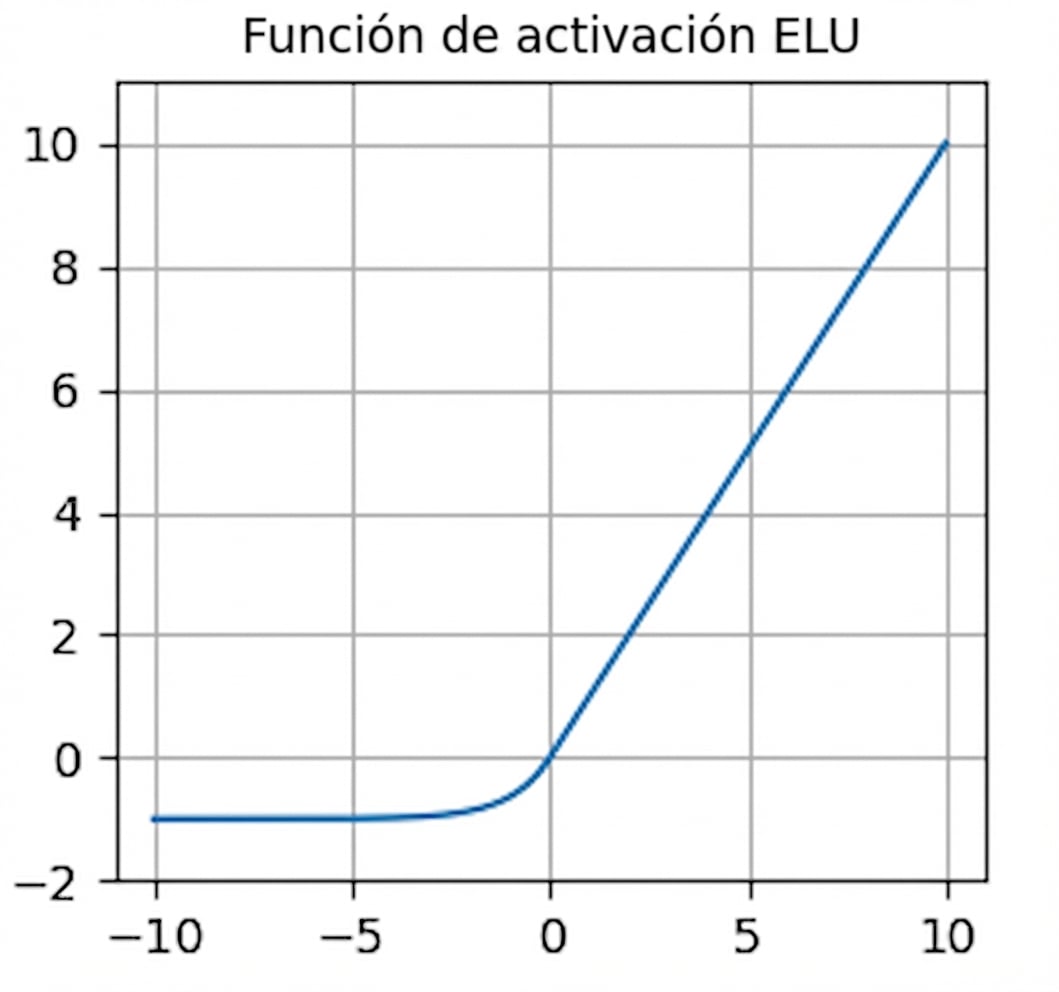
nn.functional.elu()- Gradientes distintos de cero para valores negativos: ayuda a evitar la muerte de las neuronas.
- Salida media cercana a cero: ayuda a evitar los gradientes de desaparición.

