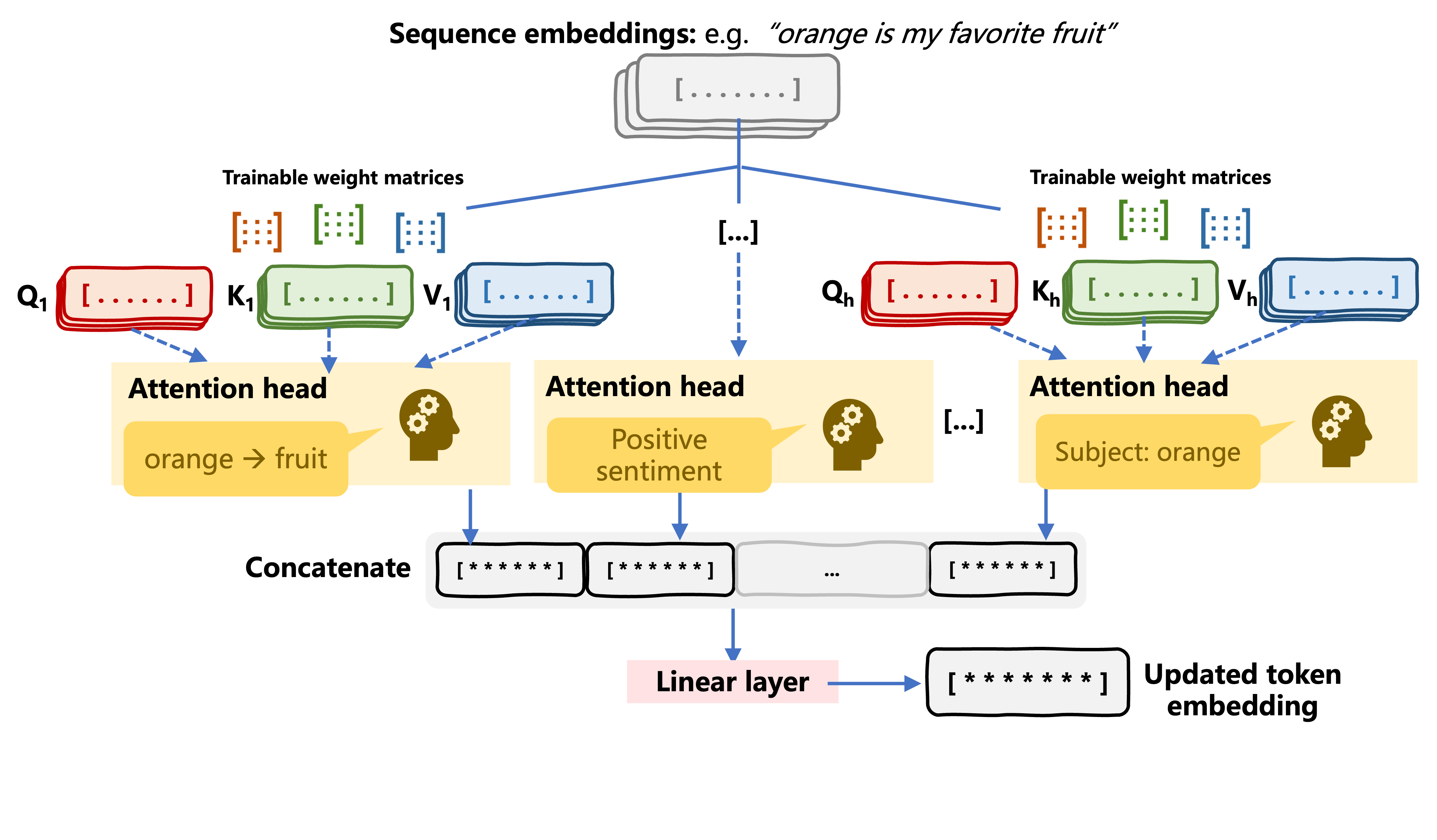
Multi-head self-attention
Transformer Models with PyTorch

James Chapman
Curriculum Manager, DataCamp
Multi-head attention in transformers
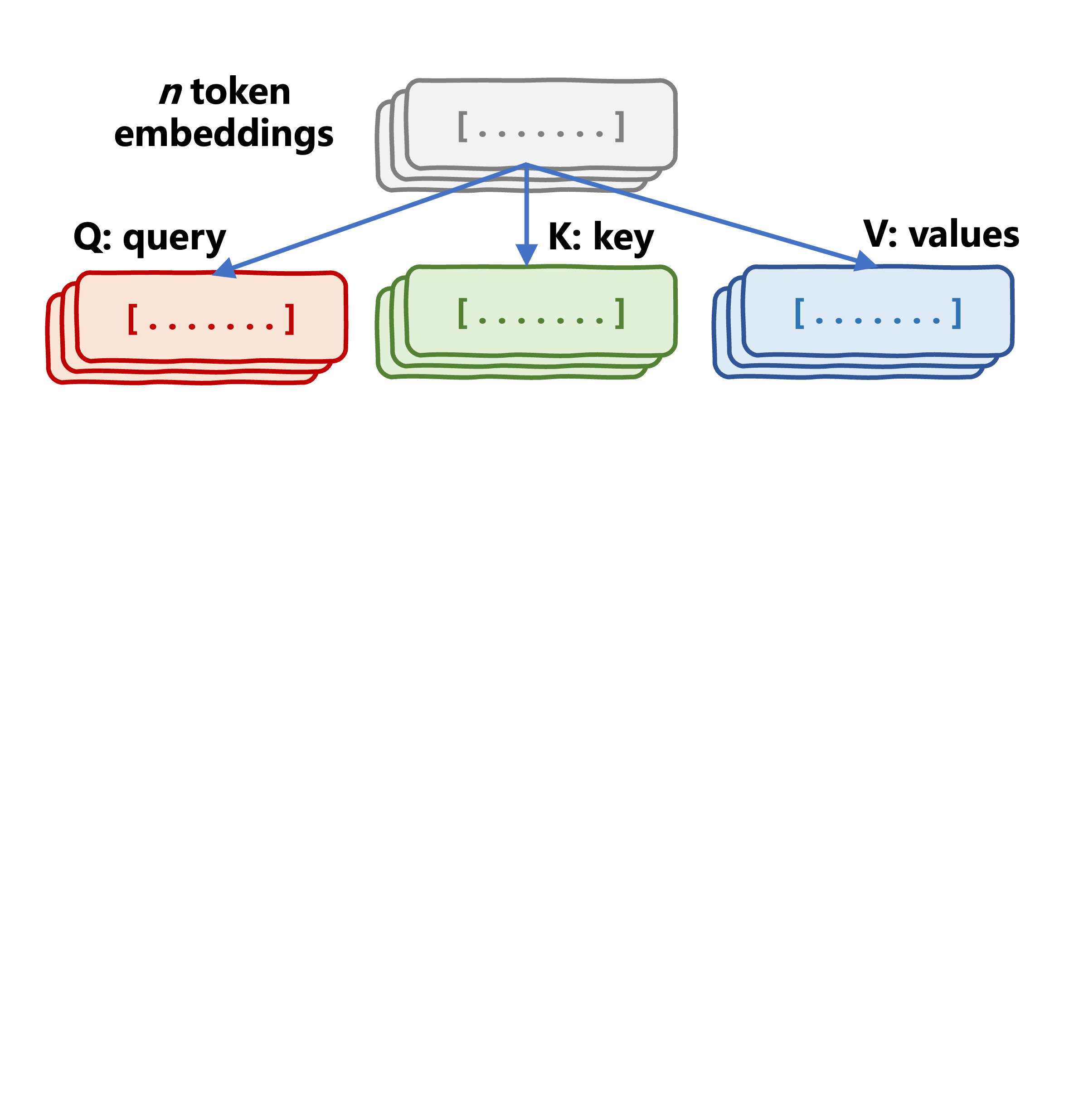
Self-attention mechanism

Self-attention mechanism
Self-attention mechanism
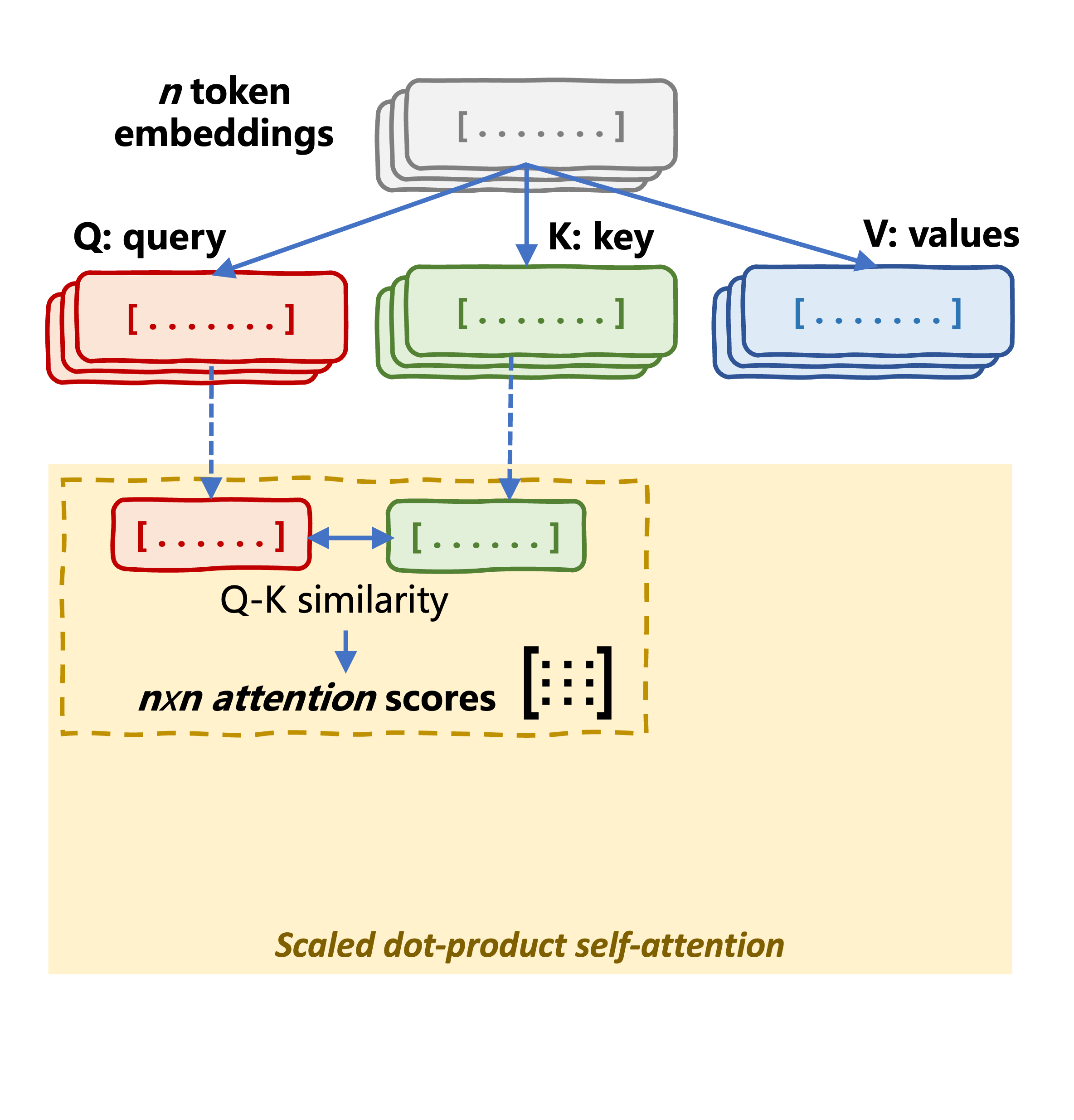
Self-attention mechanism
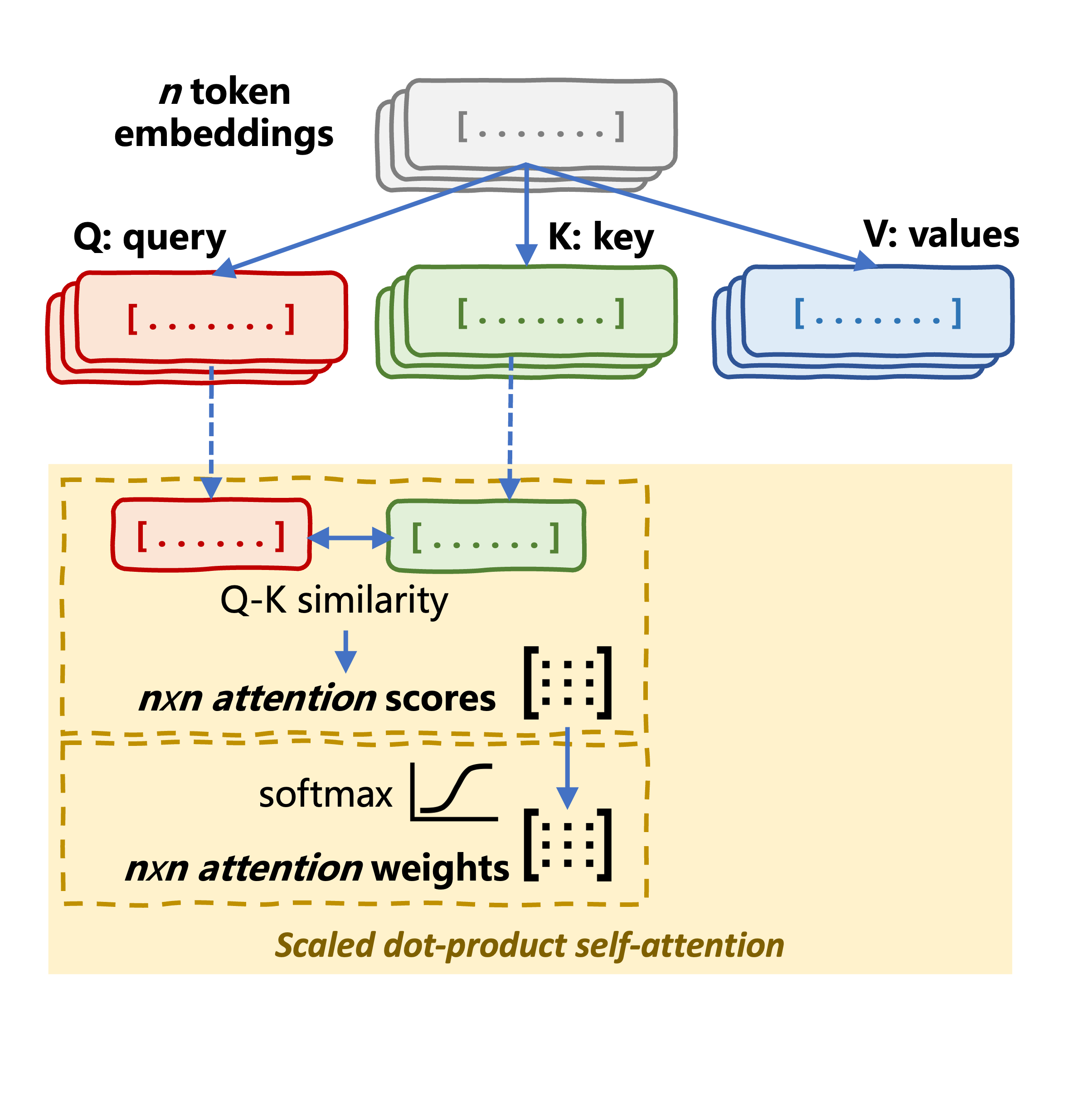
Self-attention mechanism
Self-attention mechanism
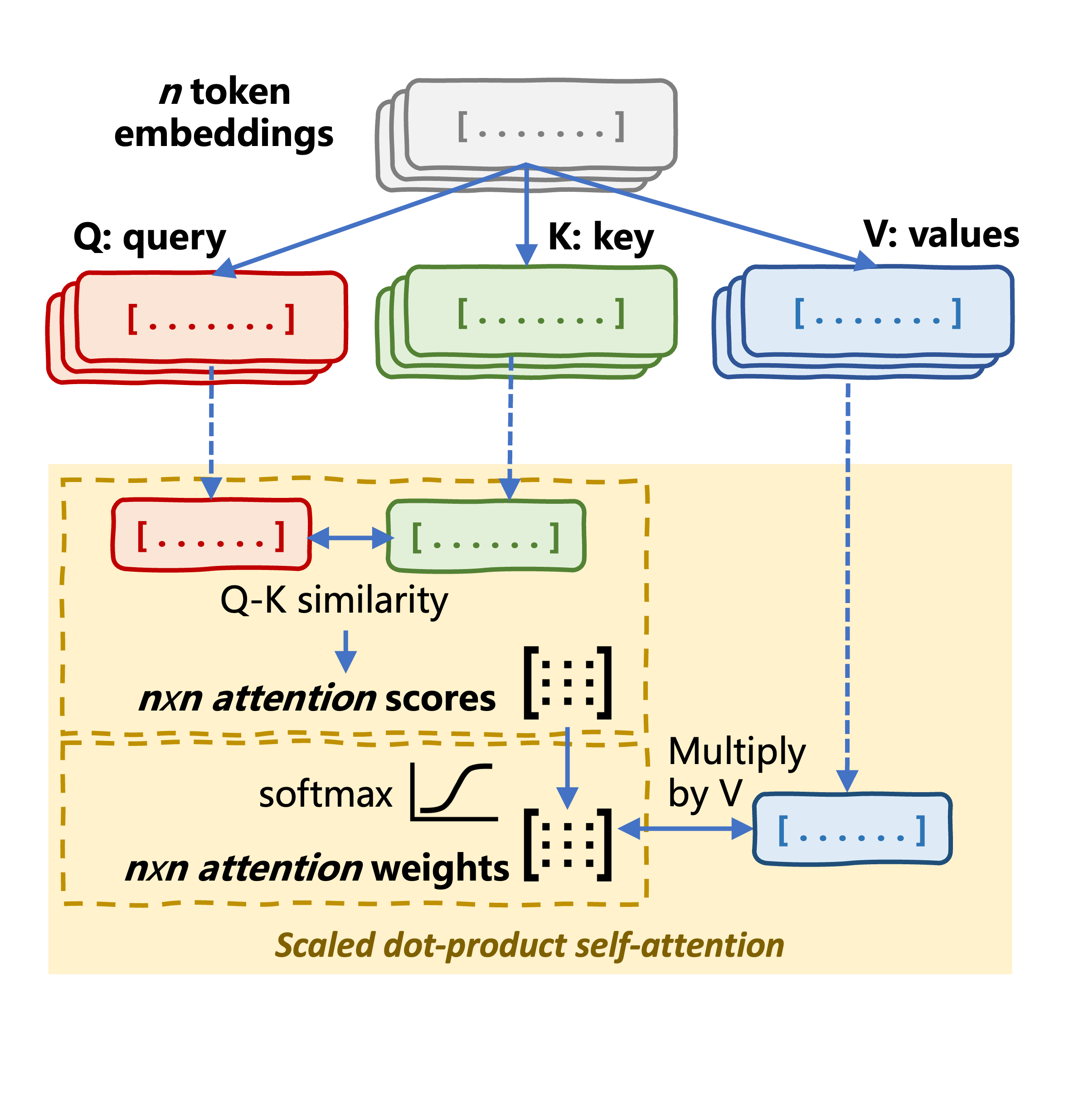
Self-attention mechanism
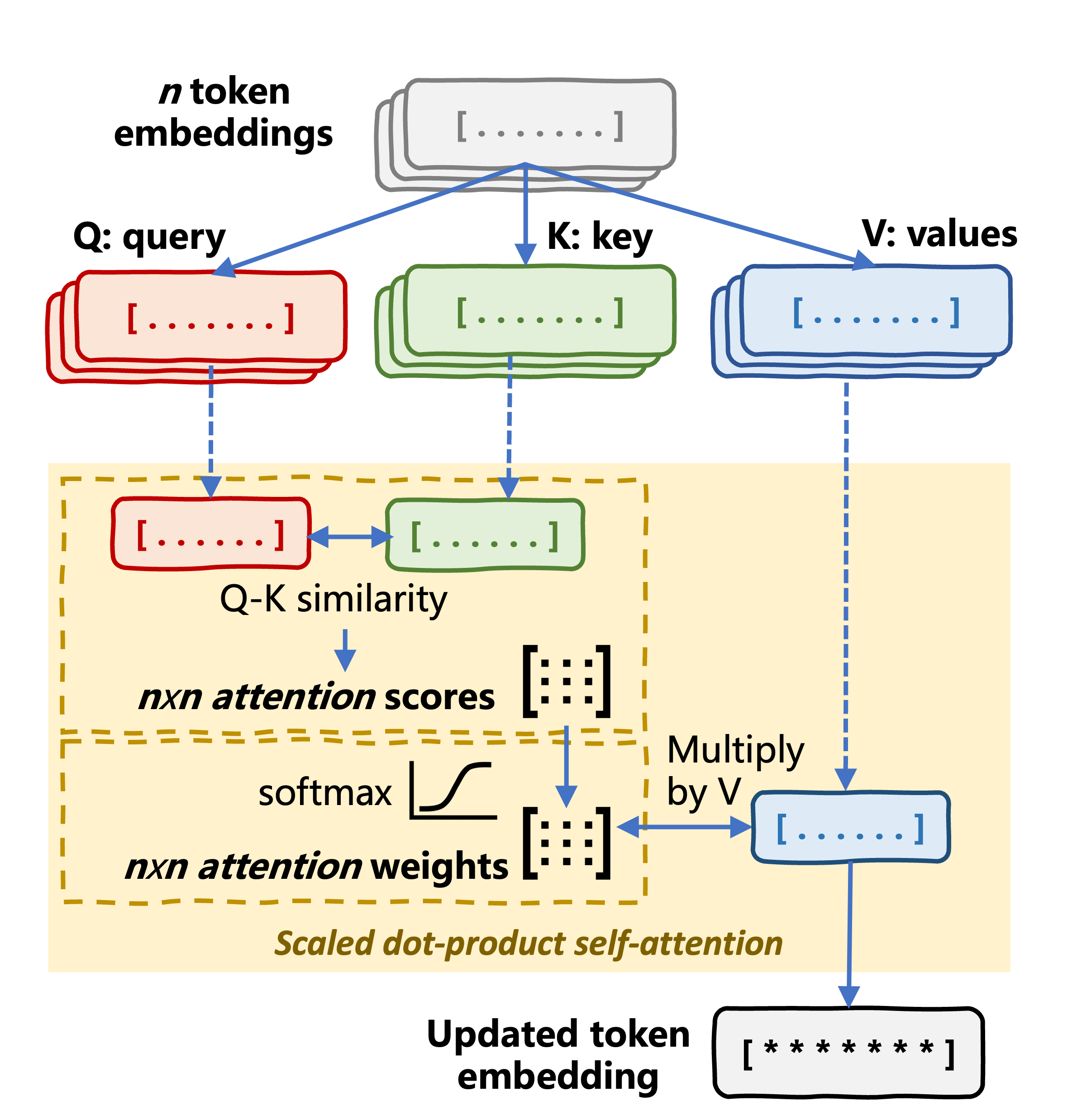
Multi-head attention
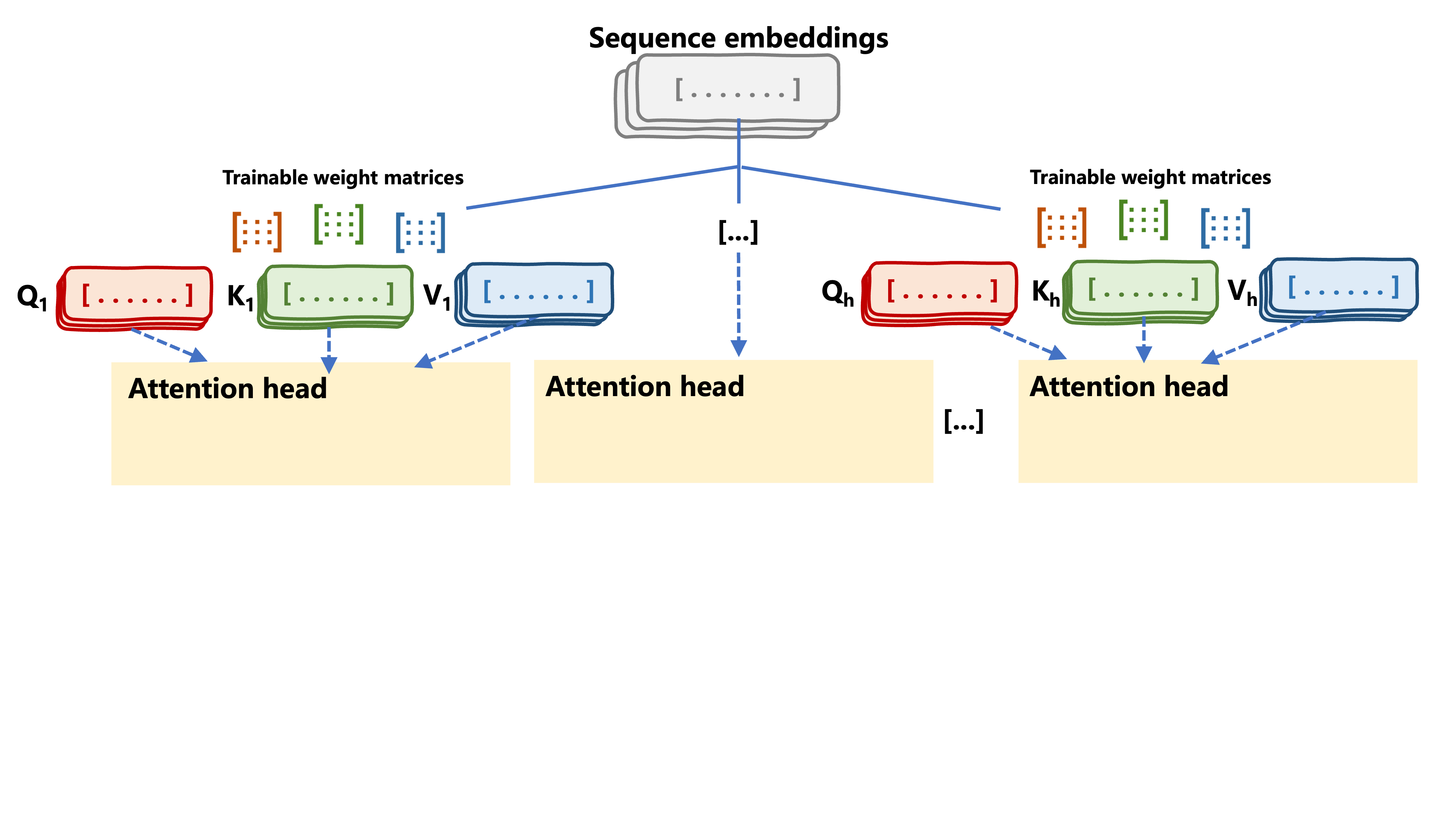
Multi-head attention
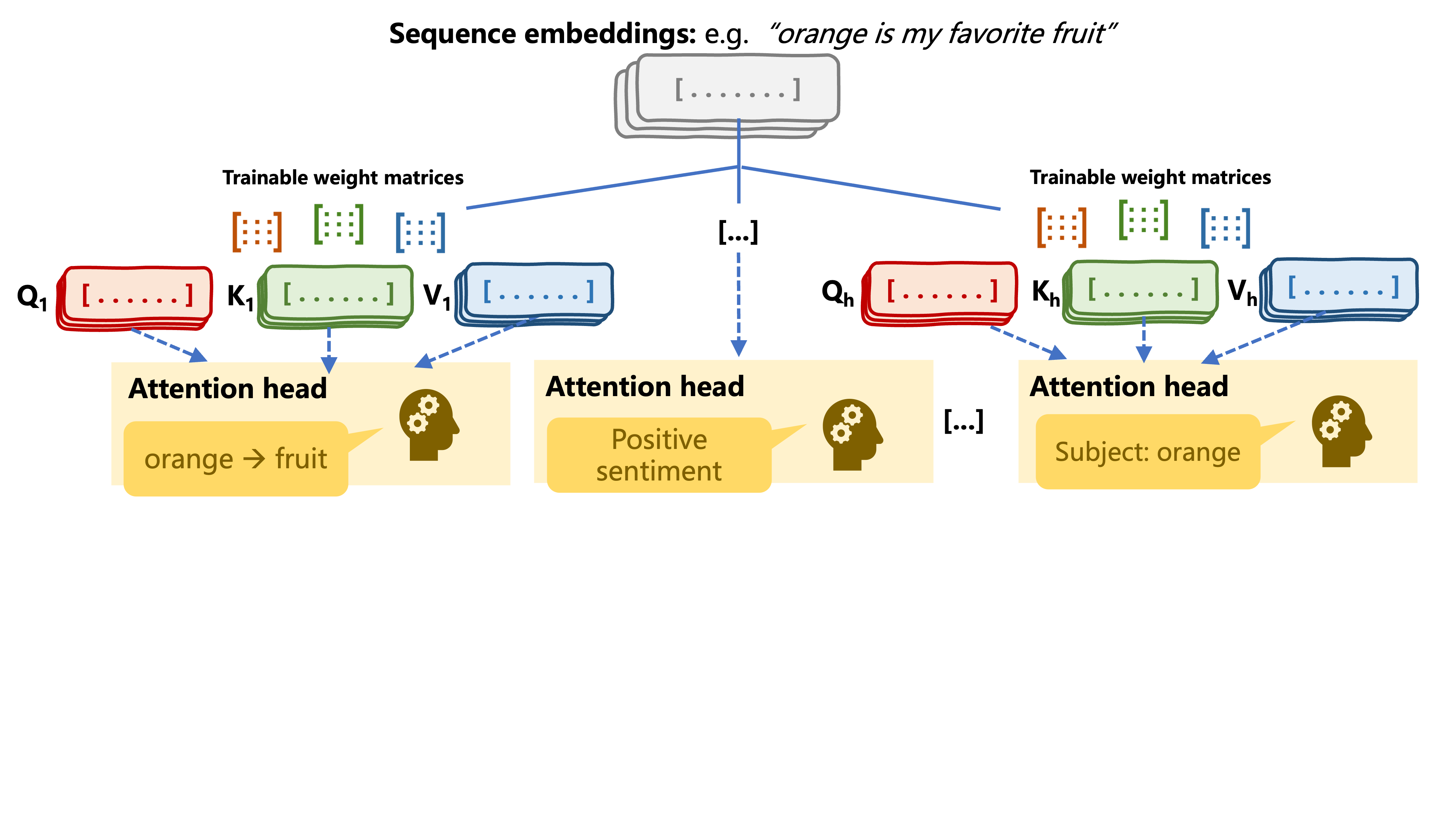
Multi-head attention