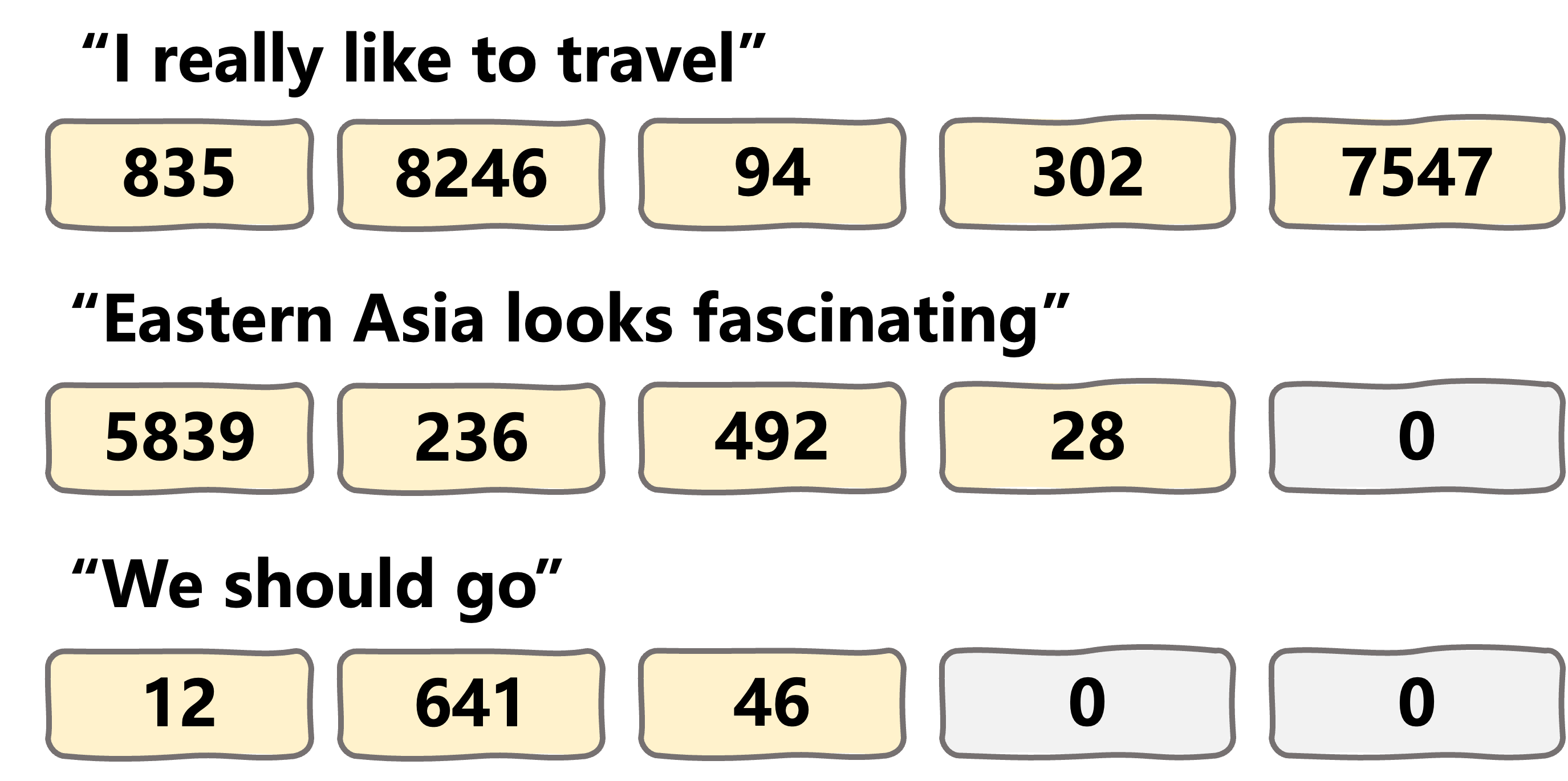
Encoder transformers
Transformer Models with PyTorch

James Chapman
Curriculum Manager, DataCamp
The original transformer
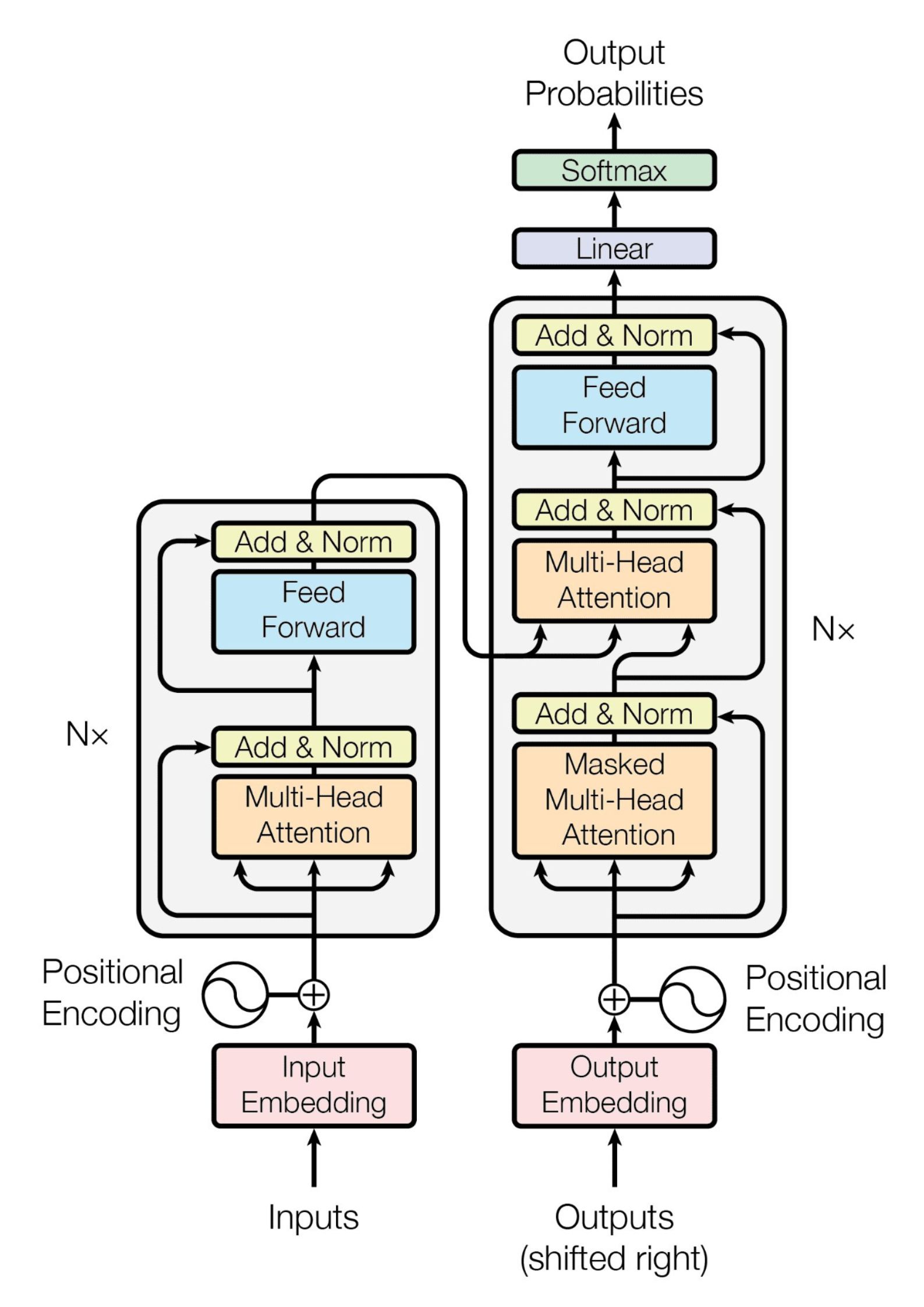
The original transformer
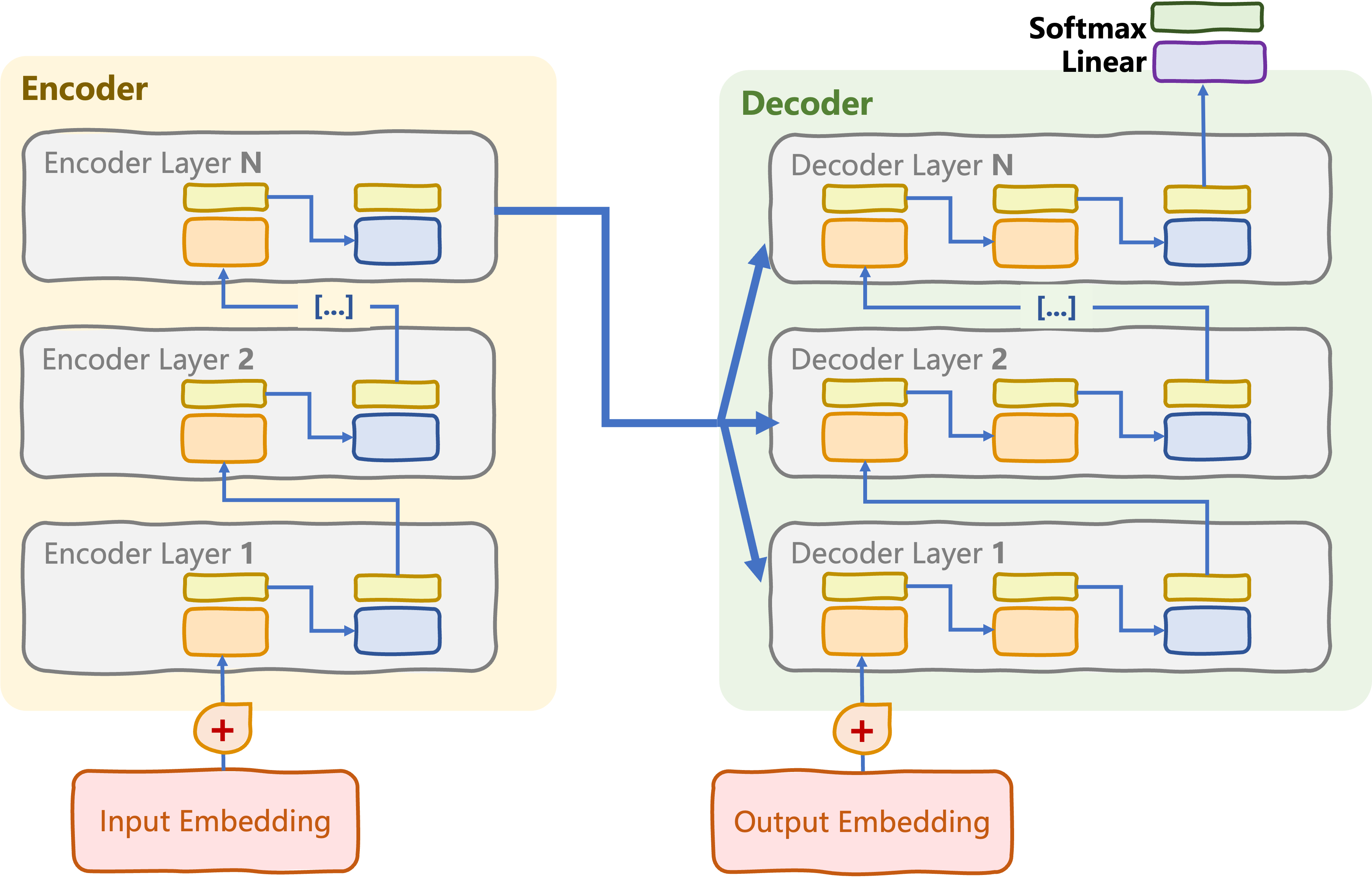
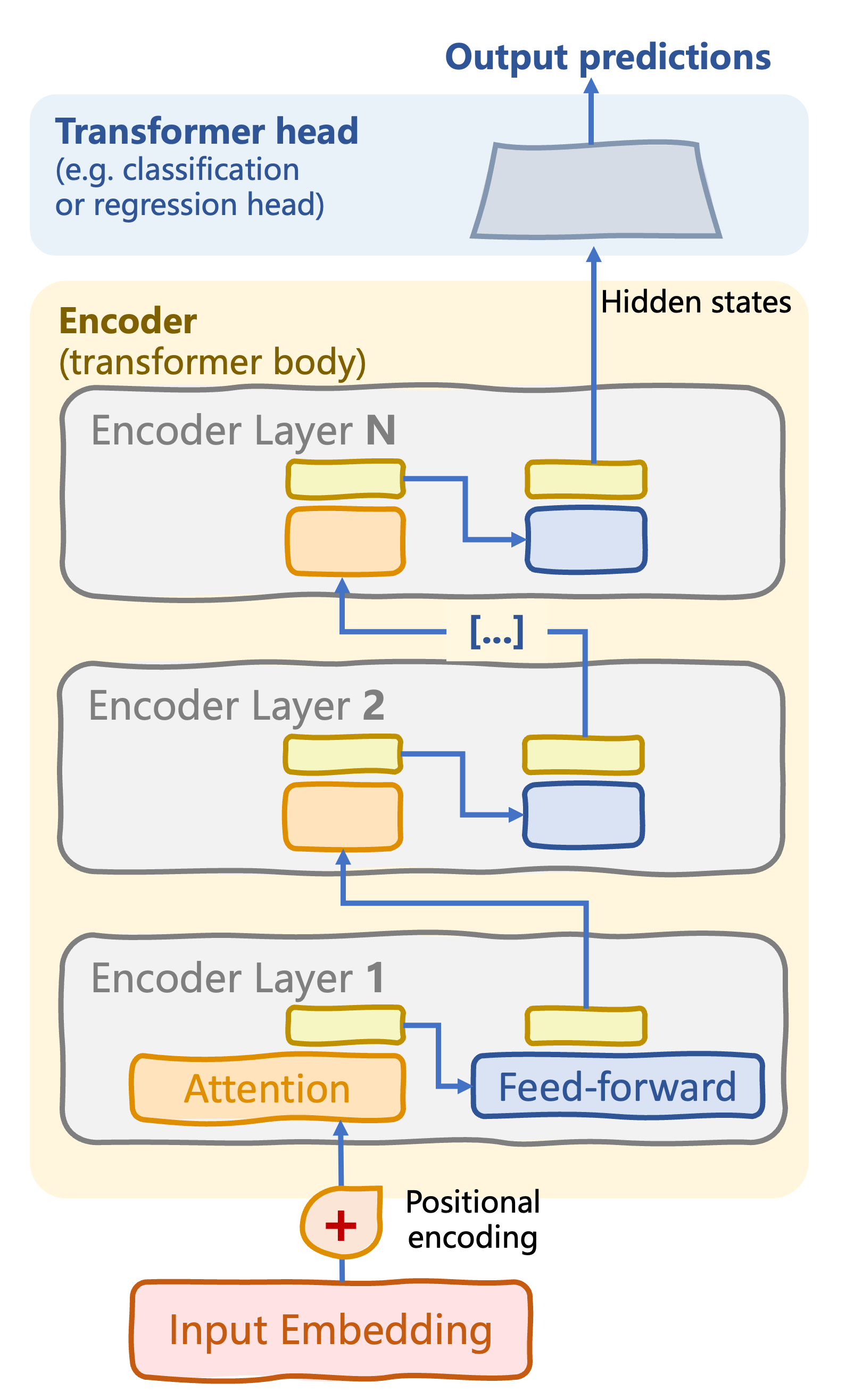
Encoder-only transformers
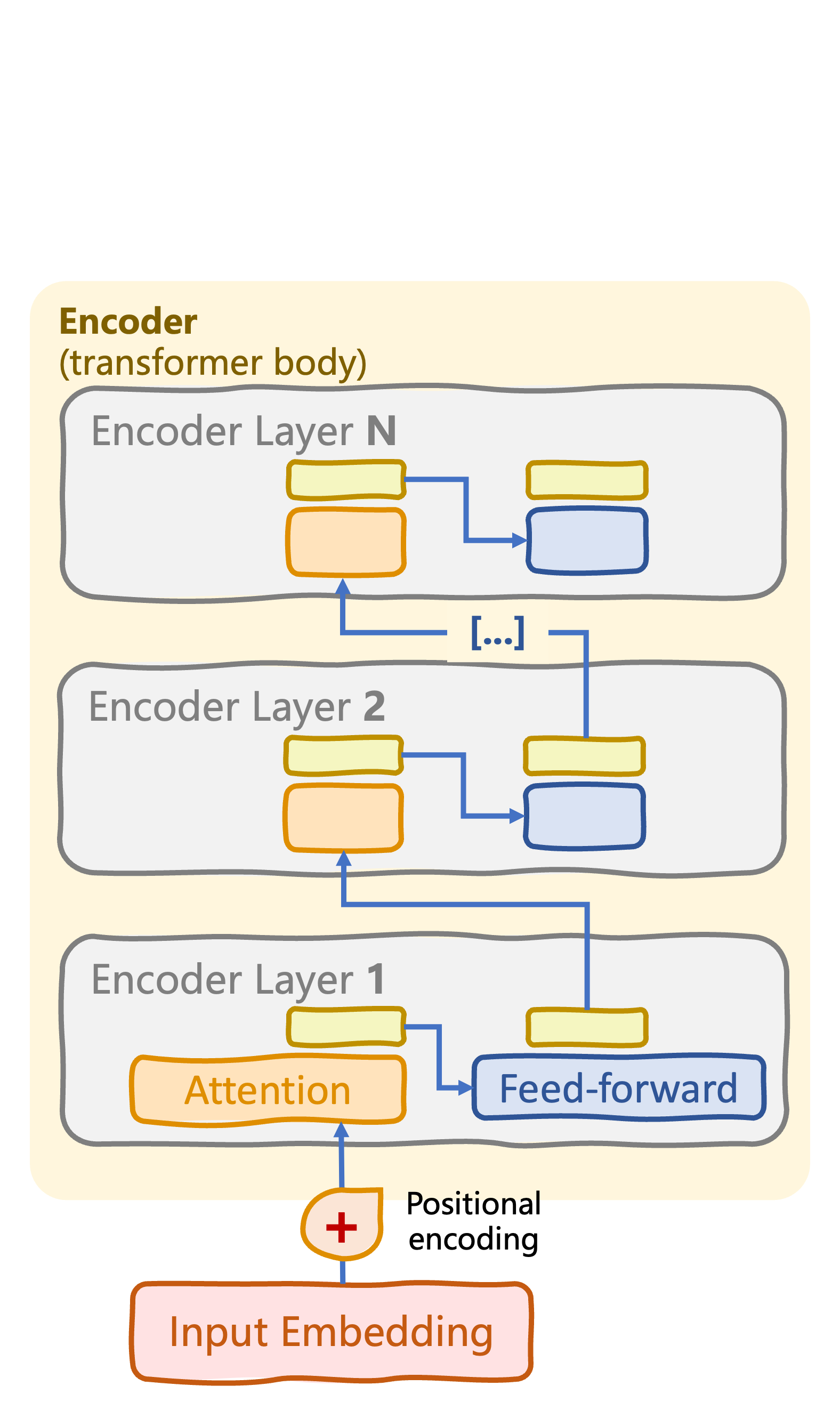
Encoder-only transformers
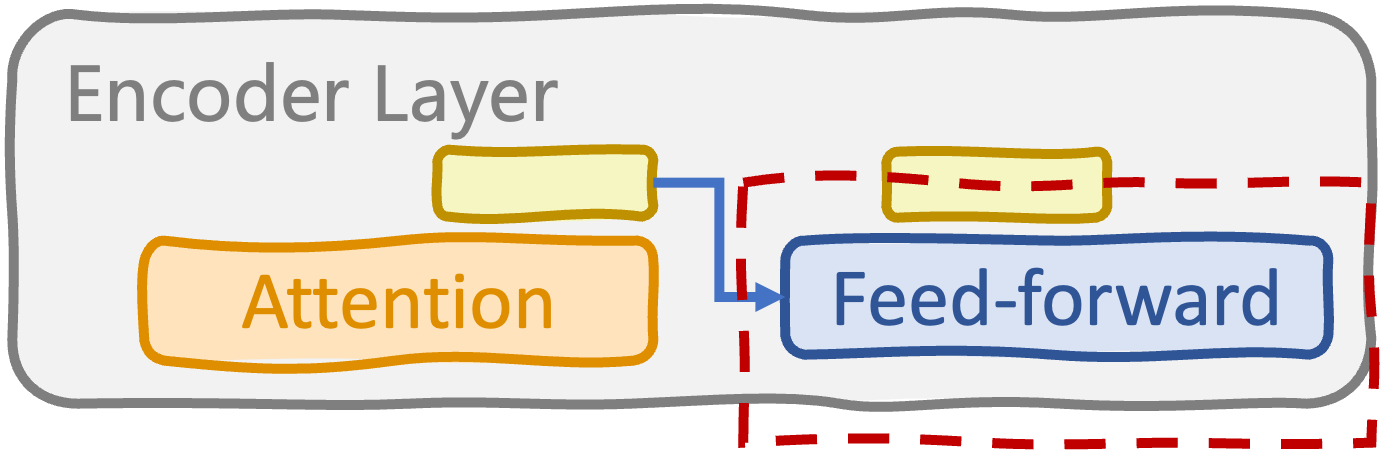
Feed-forward sublayer in encoder layers
class FeedForwardSubLayer(nn.Module): def __init__(self, d_model, d_ff): super().__init__() self.fc1 = nn.Linear(d_model, d_ff) self.fc2 = nn.Linear(d_ff, d_model) self.relu = nn.ReLU()def forward(self, x): return self.fc2(self.relu(self.fc1(x)))
Encoder layer
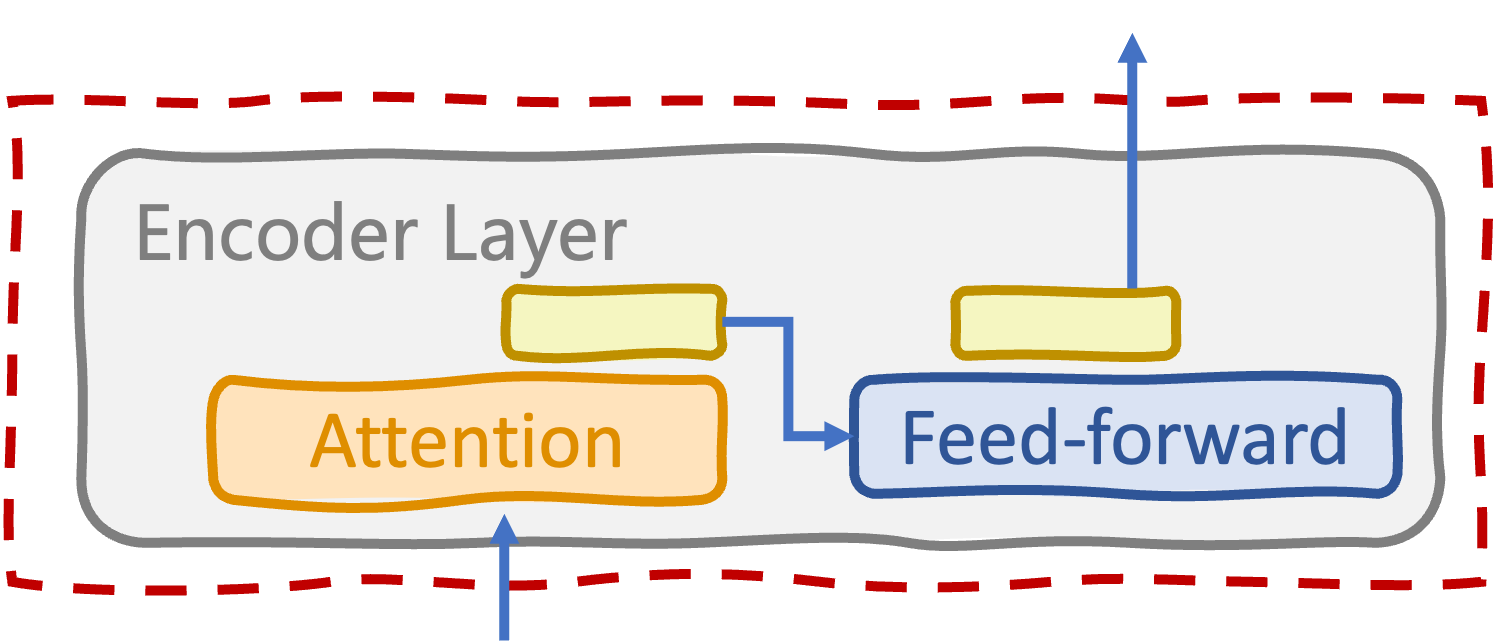
- Multi-headed self-attention
- Feed-forward sublayer
- Layer normalizations and dropouts
forward():
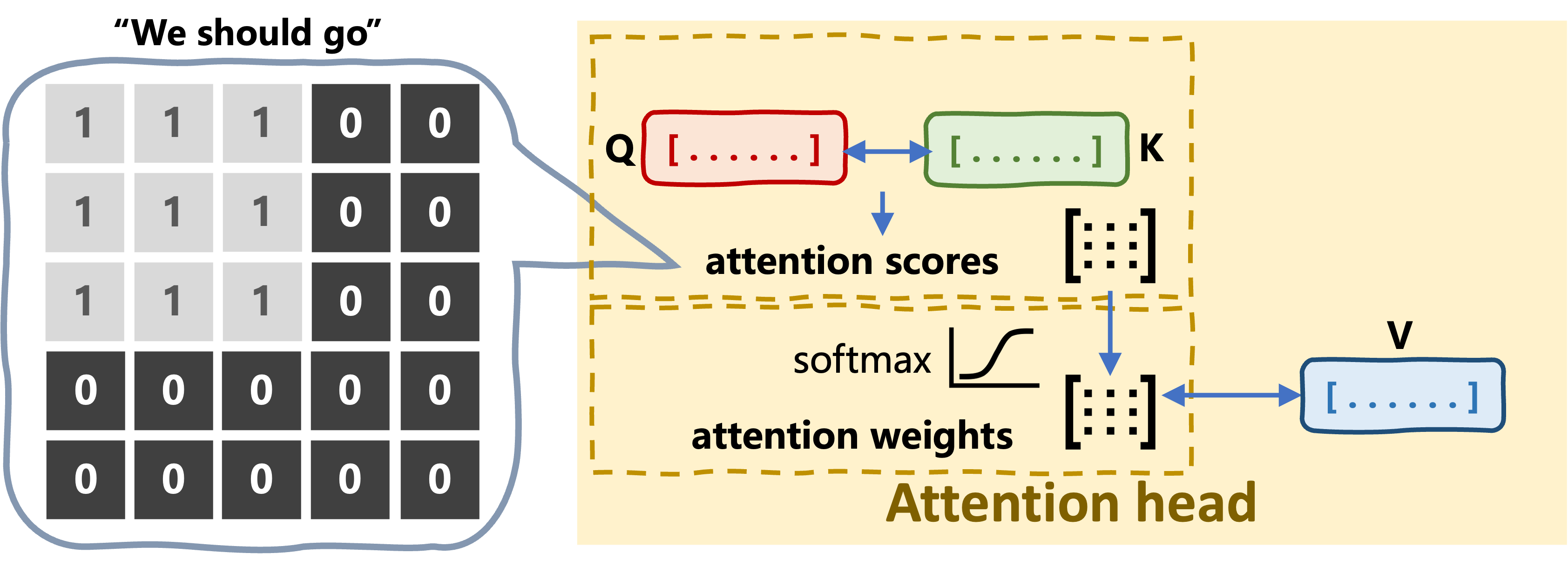
maskprevents processing padding tokens
Masking the attention process