Decoder transformers
Transformer Models with PyTorch

James Chapman
Curriculum Manager, DataCamp
From original to decoder-only transformer
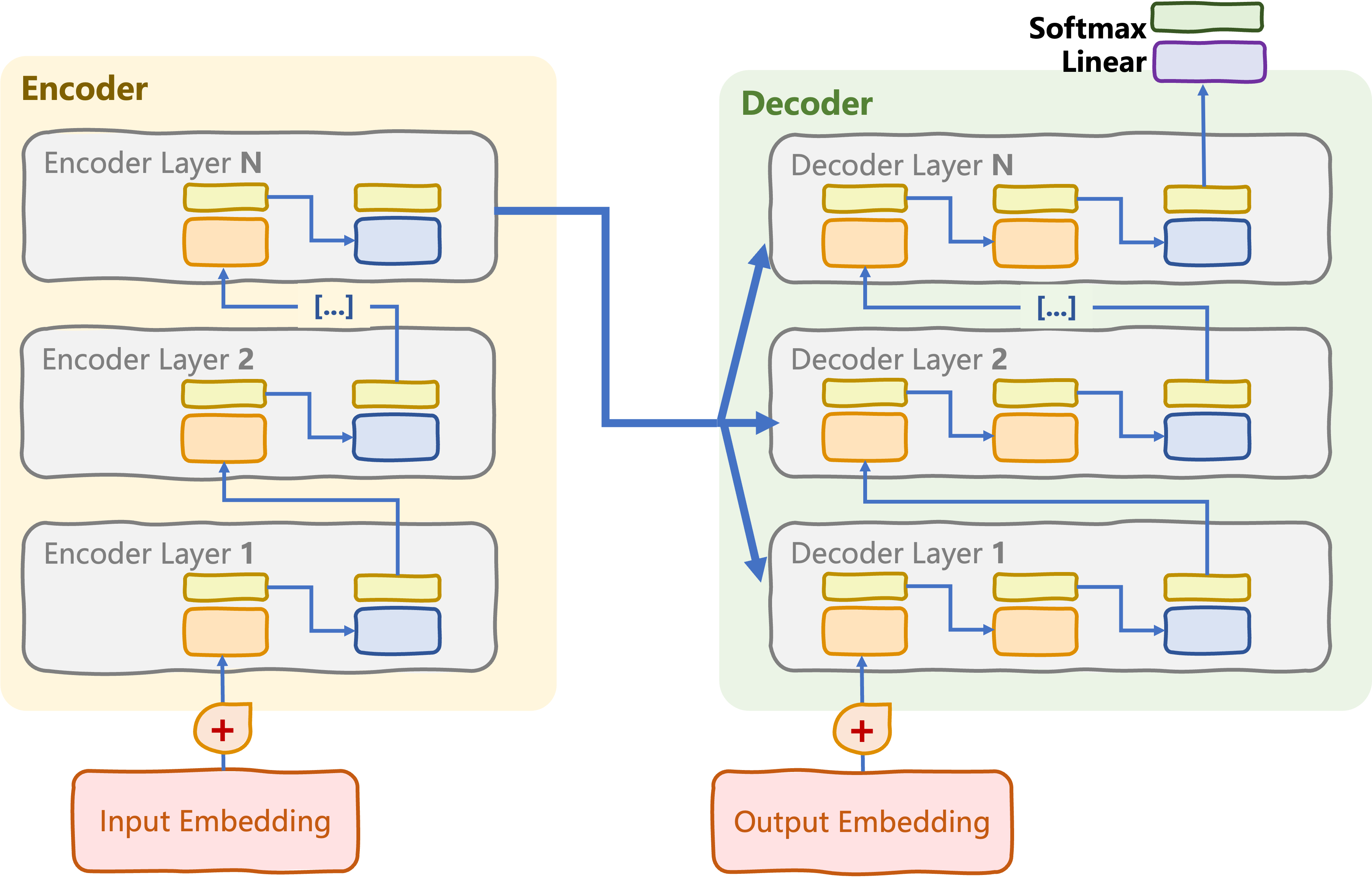
From original to decoder-only transformer
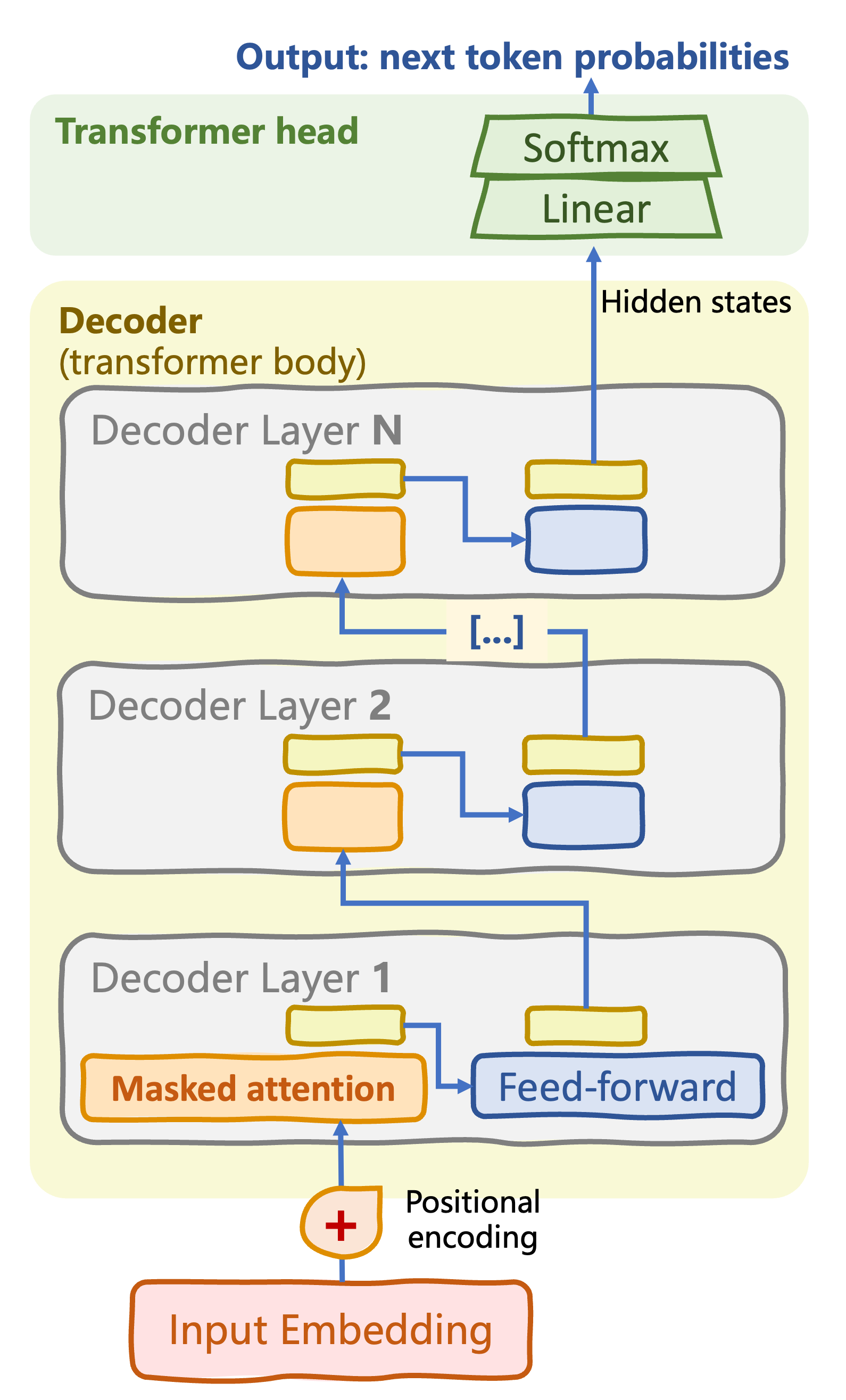
From original to decoder-only transformer
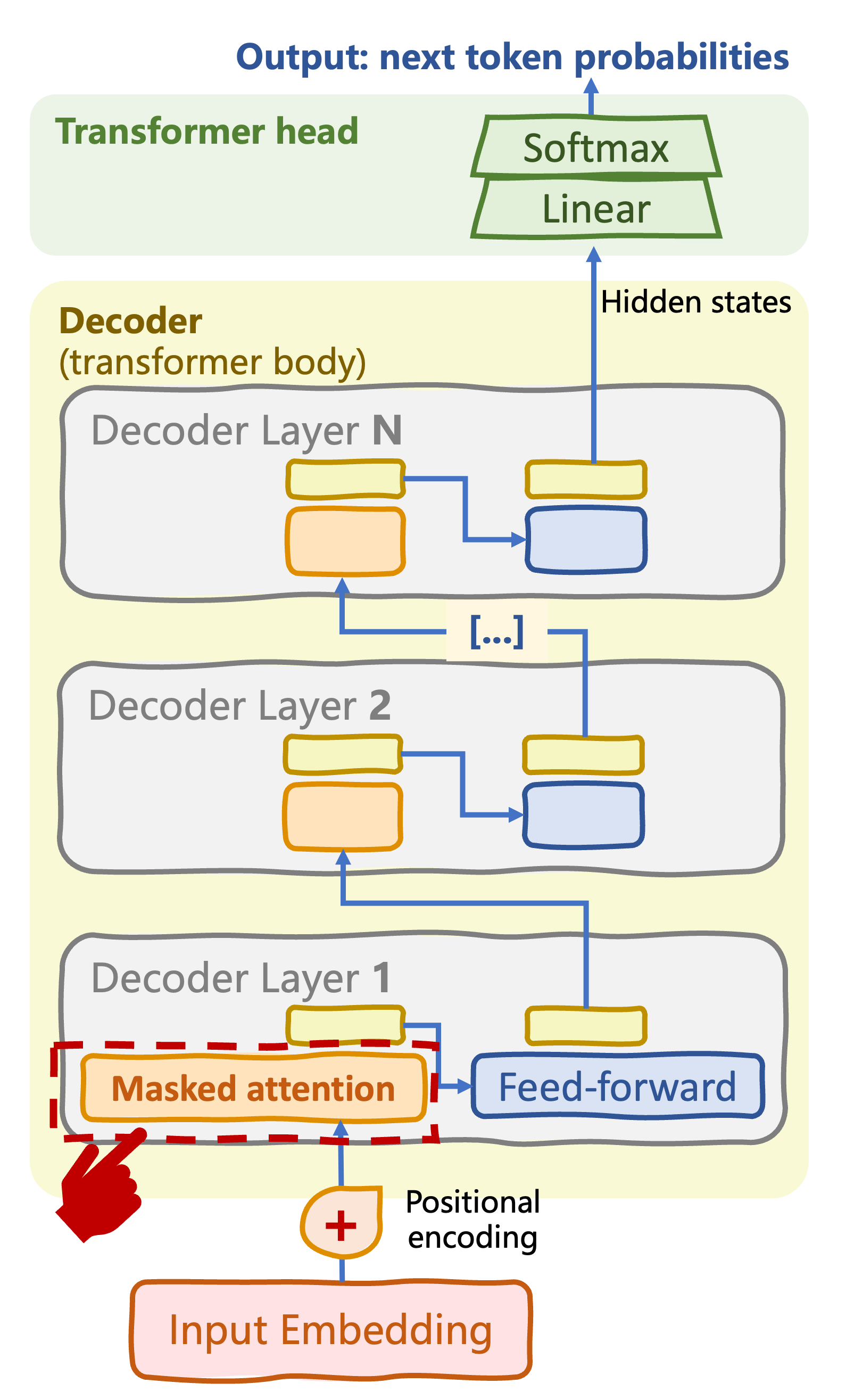
From original to decoder-only transformer
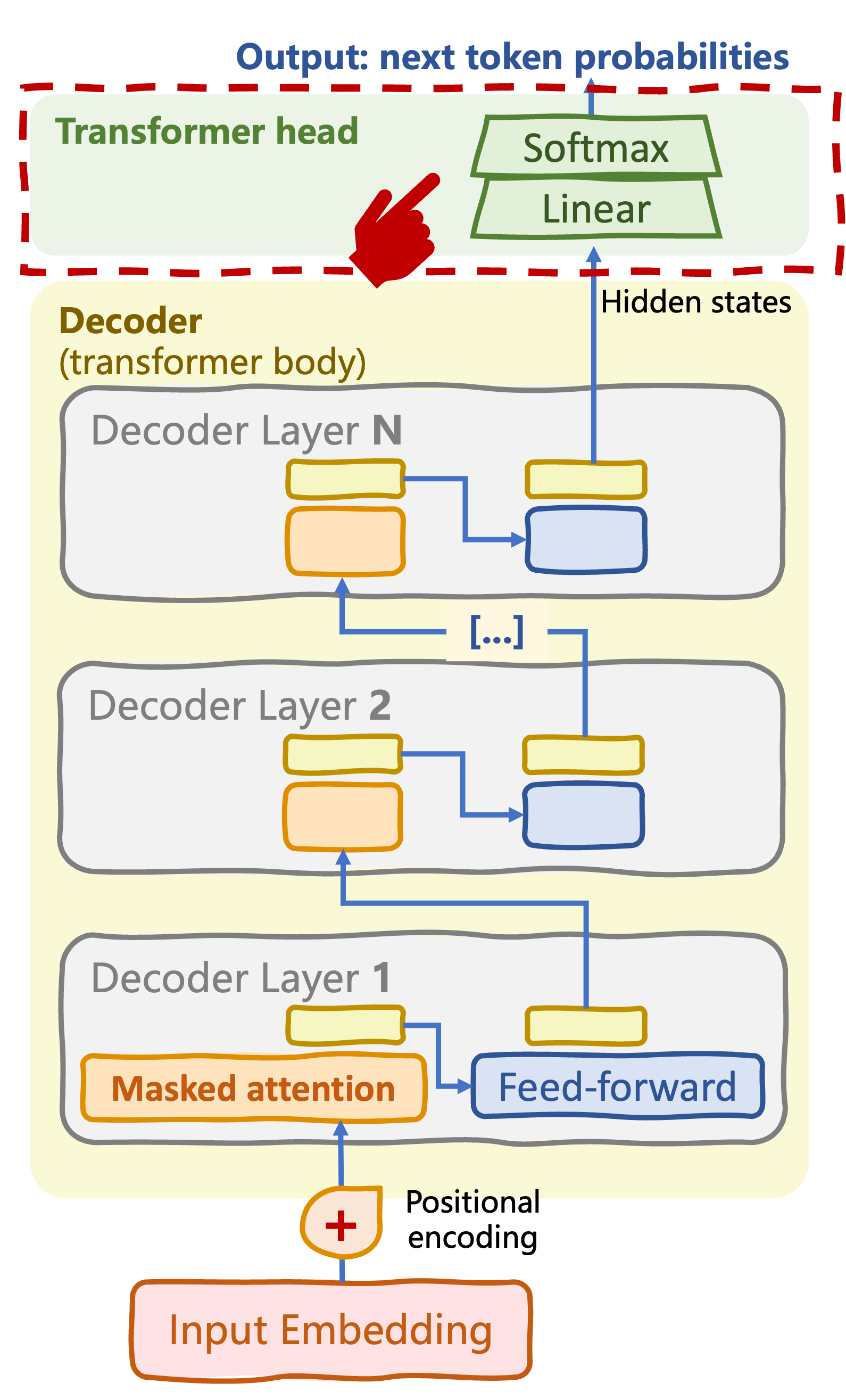
Masked self-attention/causal attention
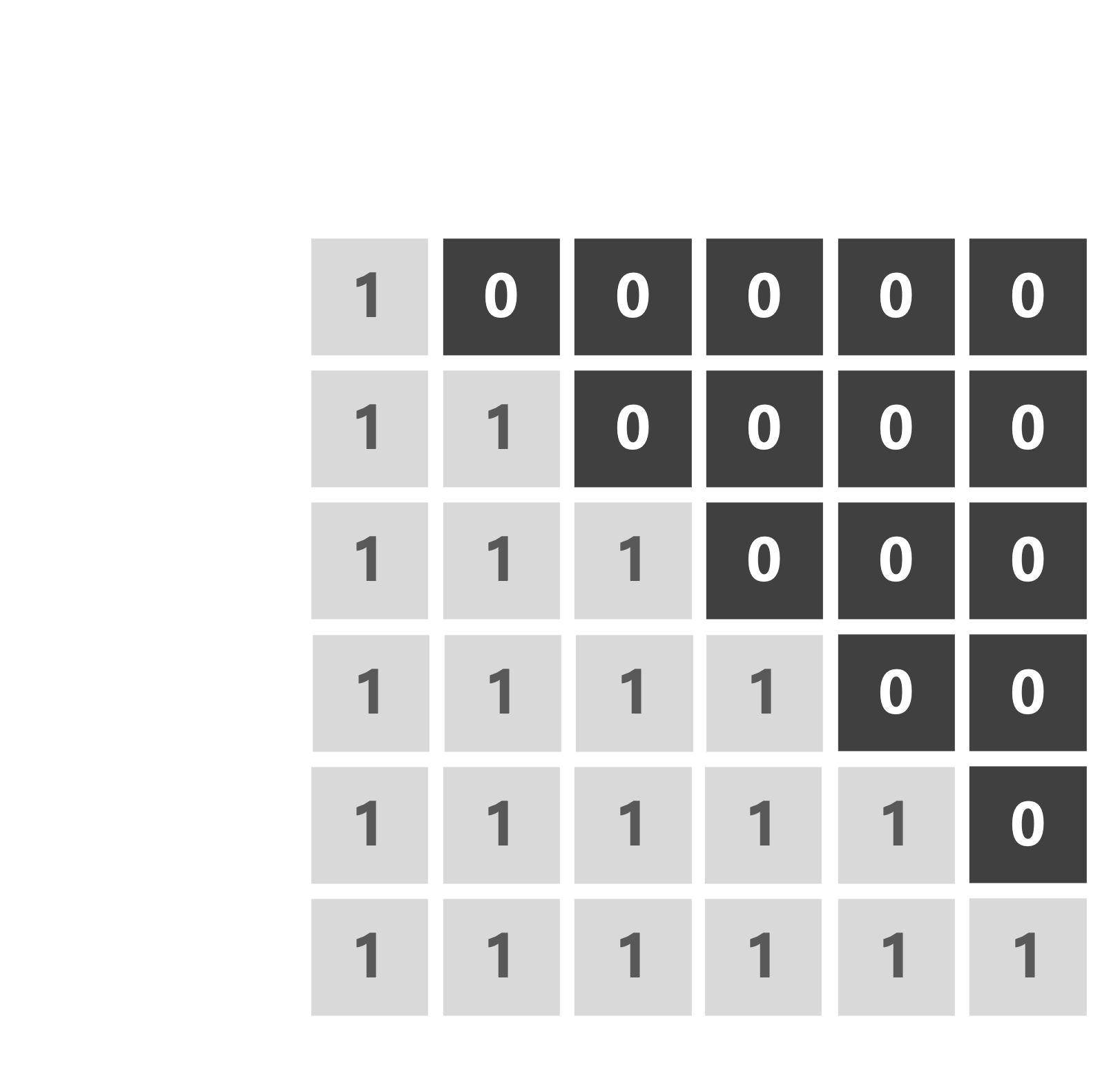
Masked self-attention/causal attention
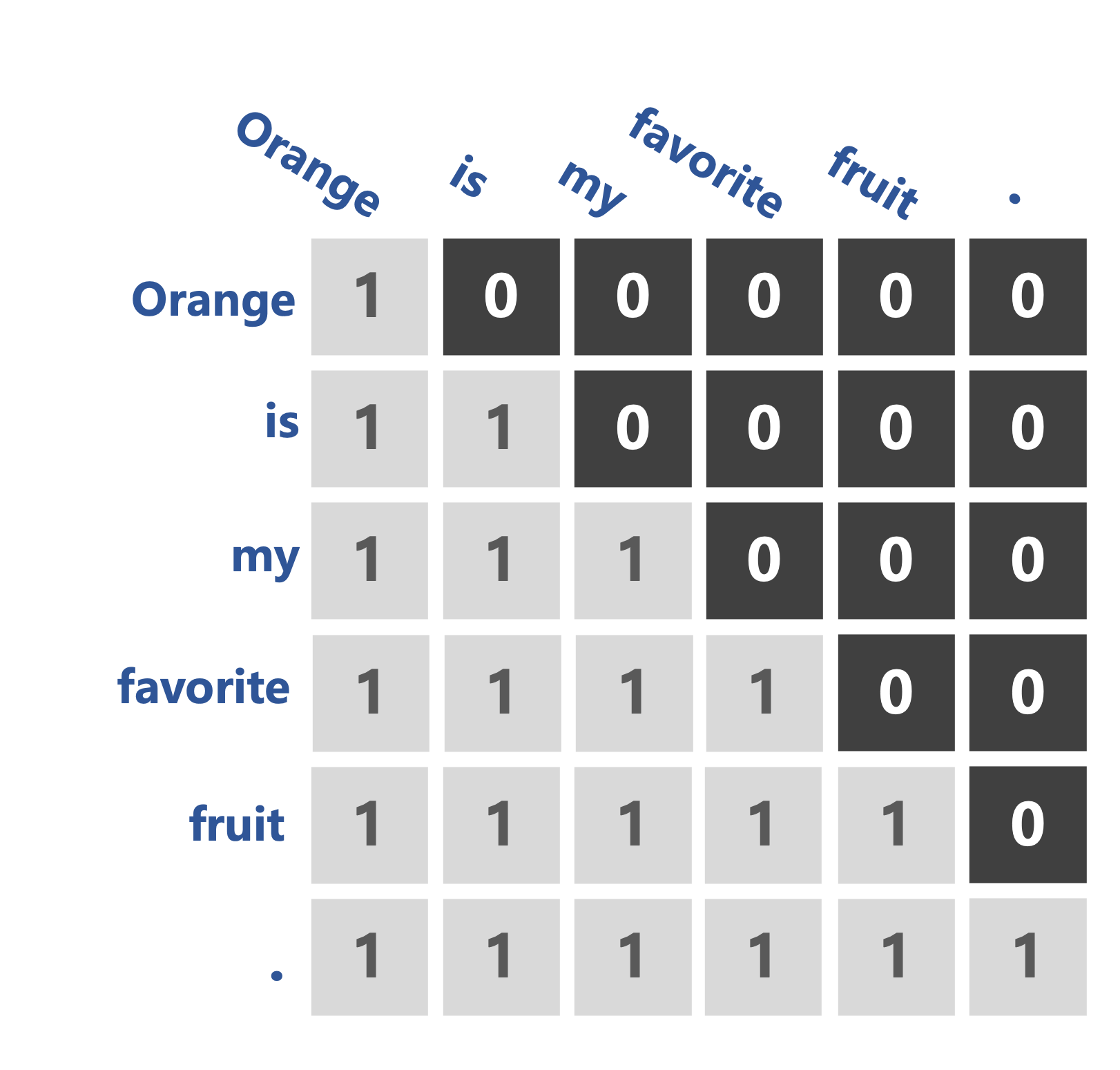
Masked self-attention/causal attention
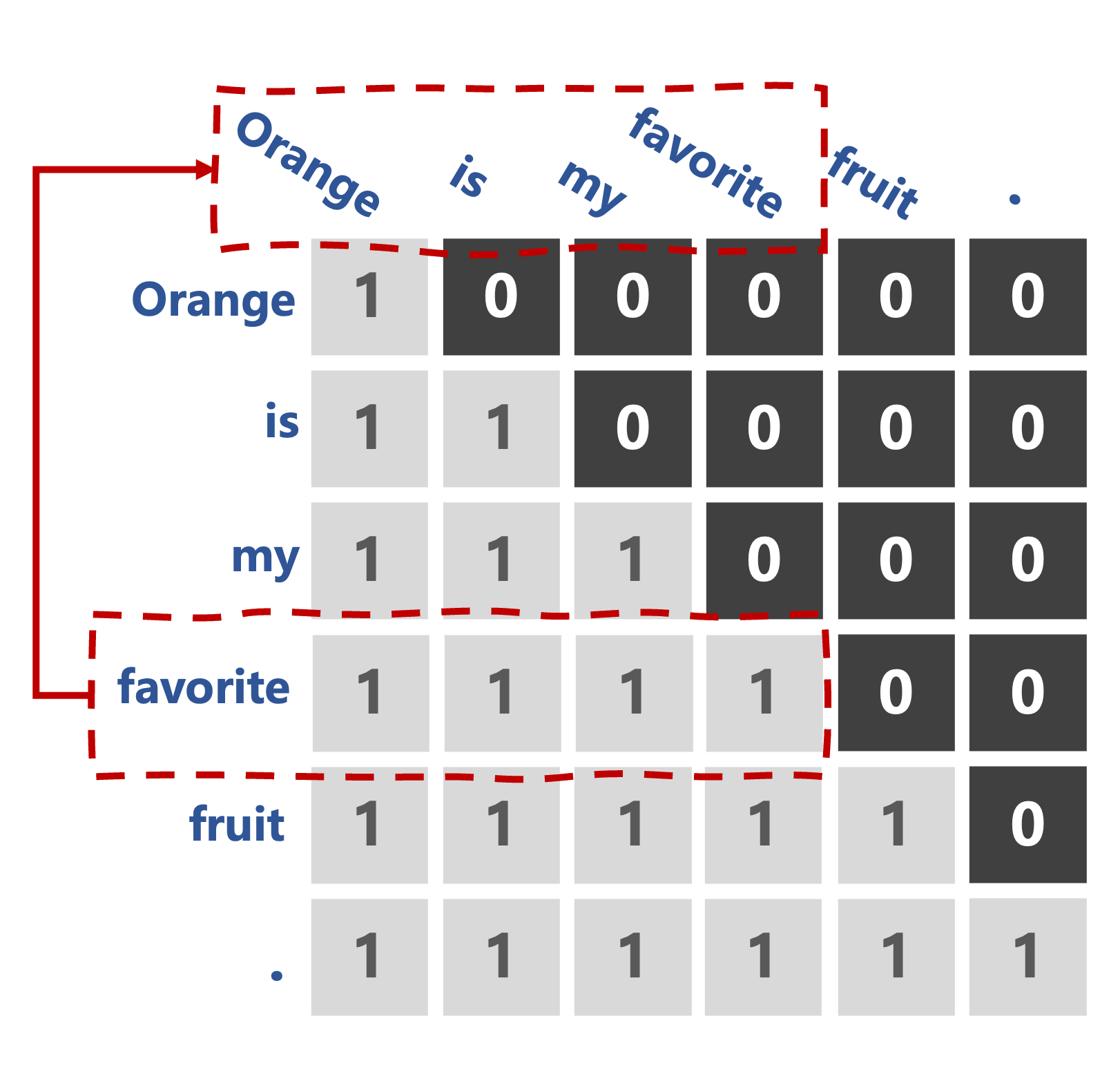
tgt_mask = (1 - torch.triu(
torch.ones(1, seq_len, seq_len), diagonal=1)
).bool()

