Model fine-tuning with Hugging Face
Fine-Tuning with Llama 3

Francesca Donadoni
Curriculum Manager, DataCamp
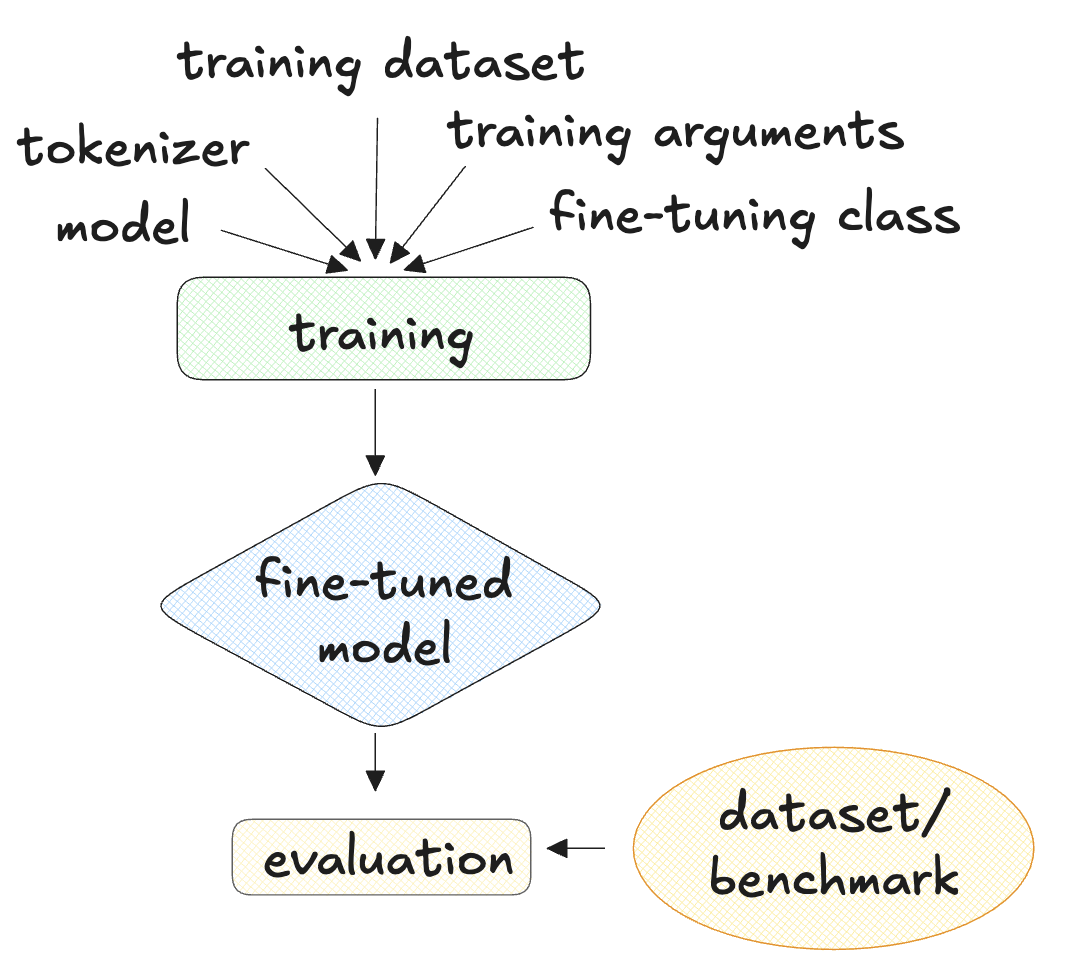
What do we need to conduct fine-tuning?
- Language model + tokenizer (a LLama model, such as TinyLLama-v0)
- Training dataset (the Bitext customer service dataset)
- Training arguments
- Conduct fine-tuning (SFTTrainer from TRL)
- Evaluation benchmark or dataset
How to load models and tokenizers with Auto classes
model_name="Maykeye/TinyLLama-v0" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)tokenizer.pad_token = tokenizer.eos_token
1 https://huggingface.co/docs/transformers/main/en/model_doc/auto
Defining training parameters with TrainingArguments
training_arguments = TrainingArguments(per_device_train_batch_size=1,learning_rate=2e-3,max_grad_norm=0.3,max_steps=200,... gradient_accumulation_steps=2, save_steps=10,)
1 https://huggingface.co/docs/transformers/v4.40.1/en/main_classes/trainer#transformers.TrainingArguments
How to set up training with SFTTrainer
trainer = SFTTrainer(model=model, tokenizer=tokenizer,train_dataset=dataset, dataset_text_field='conversation',max_seq_length=250,args=training_arguments)
Understanding fine-tuning results with SFTTrainer
trainer.train()
TrainOutput(global_step=200, training_loss=1.9401231002807617,
metrics={'train_runtime': 142.5501,
'train_samples_per_second': 2.806,
'train_steps_per_second': 1.403,
'total_flos': 1461265827840.0,
'train_loss': 1.9401231002807617,
'epoch': 2.0})
How to evaluate a trained model Using ROUGE-1
- ROUGE-1: Ratio of word overlap between a reference and generated text
import evaluaterouge = evaluate.load('rouge')predictions = ["hello there", "general kenobi"] references = ["hello there", "master yoda"]results = rouge.compute(predictions=predictions, references=references) print(results)
{'rouge1': 0.5, 'rouge2': 0.5, 'rougeL': 0.5, 'rougeLsum': 0.5}
1 https://huggingface.co/spaces/evaluate-metric/rouge
How to use the ROUGE-1 score
- Use the evaluation set in
evaluation_dataset
def generate_predictions_and_reference(dataset): predictions = [] references = [] for row in dataset: inputs = tokenizer.encode(row["instruction"], return_tensors="pt")outputs = model.generate(inputs)decoded_outputs = tokenizer.decode(outputs[0, inputs.shape[1]:], skip_special_tokens = True)references += [row["response"]] predictions += [decoded_outputs] return references, predictions
How to run ROUGE-1 on an evaluation set
references, predictions = generate_predictions_and_reference(evaluation_dataset)
rouge = evaluate.load('rouge')
results = rouge.compute(predictions=predictions, references=references)
print(results)
Finetuning vs no finetuning
Fine-tuned
{'rouge1': 0.22425812699023645,
'rouge2': 0.039502543246449,
'rougeL': 0.1501513006868983,
'rougeLsum': 0.18685597710721613}
No fine-tuning
{'rouge1': 0.1310928764315105,
'rouge2': 0.04581654122835097,
'rougeL': 0.08415351421221628,
'rougeLsum': 0.1224749866097021}
Let's practice!
Fine-Tuning with Llama 3

