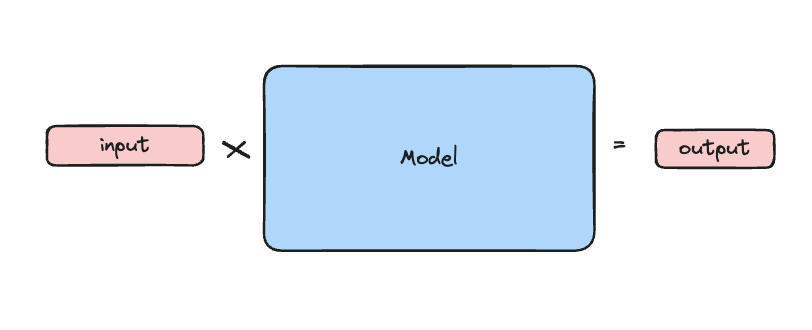
Fine-Tuning with Llama 3
Francesca Donadoni
Curriculum Manager, DataCamp
from peft import LoraConfig lora_config = LoraConfig( r=12, lora_alpha=32, lora_dropout=0.05, bias="none", task_type="CAUSAL_LM", target_modules=['q_proj', 'v_proj'] )
from peft import LoraConfig
lora_config = LoraConfig(
r=12,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM", target_modules=['q_proj', 'v_proj']
)
trainer = SFTTrainer( model=model, train_dataset=ds, max_seq_length=250, dataset_text_field='conversation', tokenizer=tokenizer, args=training_arguments peft_config=lora_config, ) trainer.train()
trainer = SFTTrainer( model=model,
train_dataset=ds,
max_seq_length=250, dataset_text_field='conversation',
tokenizer=tokenizer, args=training_arguments
peft_config=lora_config,
trainer.train()
TinyLlama/TinyLlama-1.1B-Chat-v1.0
nvidia/Llama3-ChatQA-1.5-8B