Quelle est la qualité de votre modèle ?
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
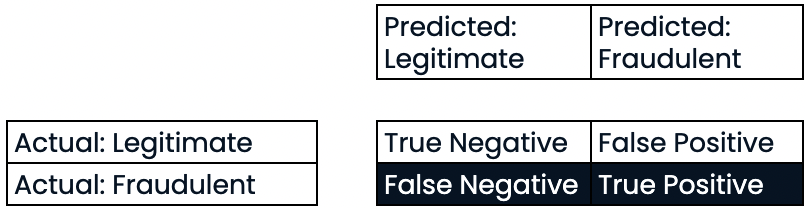
Matrice de confusion pour l’évaluation des performances de la classification
- Matrice de confusion
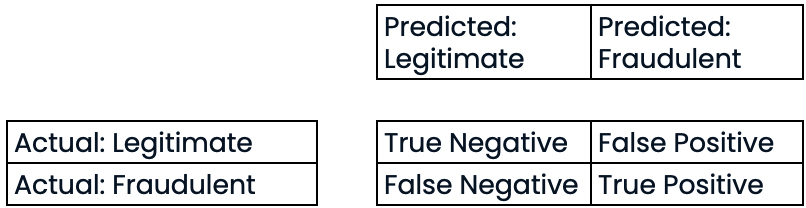
Évaluer les performances de la classification
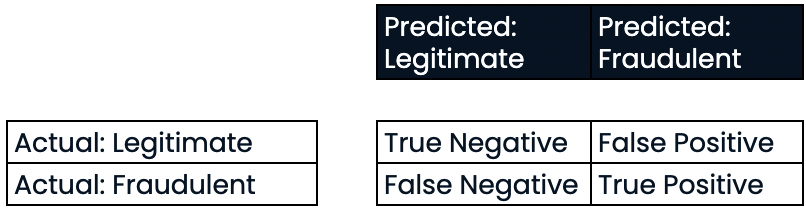
Évaluer les performances de la classification

Évaluer les performances de la classification
Évaluer les performances de la classification
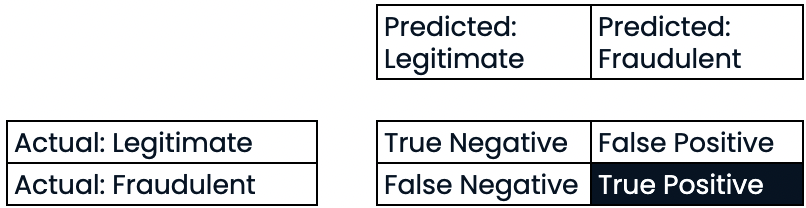
Évaluer les performances de la classification
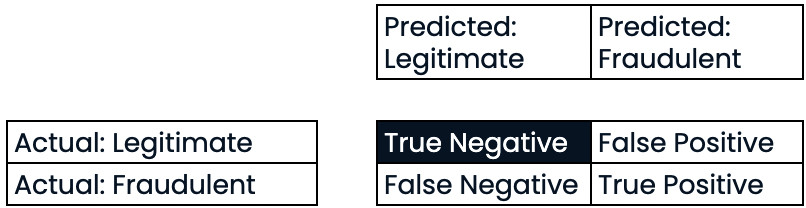
Évaluer les performances de la classification
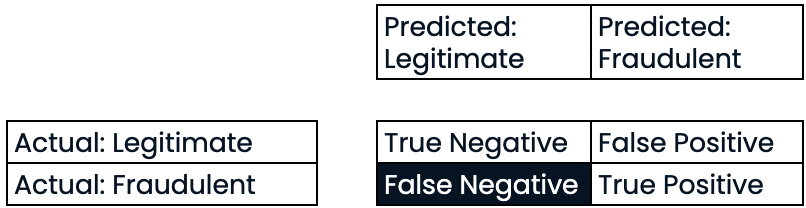
Évaluer les performances de la classification
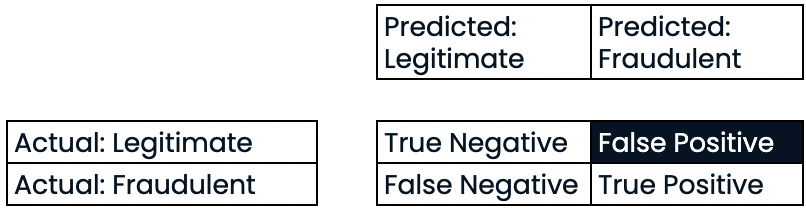
Évaluer les performances de la classification
- Exactitude :
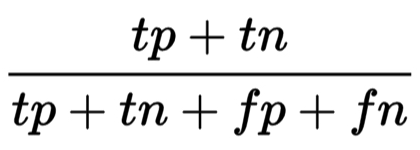
Précision
- Précision
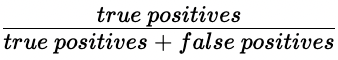
- Précision élevée = taux de faux positifs plus faible
- Précision élevée : peu de transactions légitimes sont prédites comme étant frauduleuses
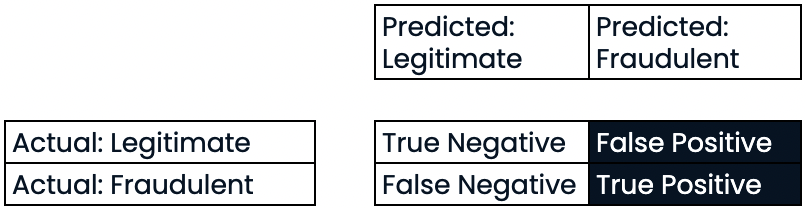
Rappel
- Rappel
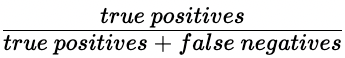
- Rappel élevé = taux de faux négatifs plus faible
- Rappel élevé : prévision correcte de la plupart des transactions frauduleuses

