Évaluation de plusieurs modèles
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Différents modèles pour différents problèmes
Quelques principes directeurs
- Taille de l’ensemble de données
- Moins de caractéristiques = modèle plus simple, temps d’apprentissage plus court
- Certains modèles nécessitent de grandes quantités de données pour être performants
- Interprétabilité
- Certains modèles sont plus faciles à expliquer, ce qui peut être important pour les parties prenantes
- La régression linéaire est très facile à interpréter, car nous pouvons comprendre les coefficients
- Flexibilité
- Peut améliorer l’exactitude, en faisant moins d’hypothèses sur les données
- KNN est un modèle plus flexible, qui ne suppose aucune relation linéaire
Les métriques nous disent tout
Performance du modèle de régression :
- RMSE
- R-carré
Performance du modèle de classification :
- Exactitude
- Matrice de confusion
- Précision, rappel, score F1
- Aire sous la courbe ROC
Entraînez plusieurs modèles et évaluez les performances sans modification
Une note sur la mise à l’échelle
- Modèles affectés par la mise à l’échelle :
- KNN
- Régression linéaire (plus crête, lasso)
- Régression logistique
- Réseau de neurones artificiel
- Il est préférable de mettre à l’échelle nos données avant d’évaluer les modèles
Évaluation des modèles de classification
import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score, KFold, train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifierX = music.drop("genre", axis=1).values y = music["genre"].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
Évaluation des modèles de classification
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()} results = []for model in models.values():kf = KFold(n_splits=6, random_state=42, shuffle=True)cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)results.append(cv_results)plt.boxplot(results, labels=models.keys()) plt.show()
Visualisation des résultats
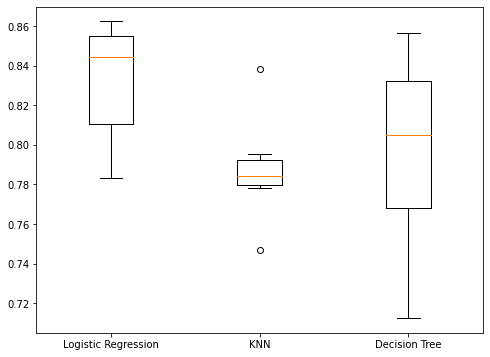
Performances de l’ensemble de test
for name, model in models.items():model.fit(X_train_scaled, y_train)test_score = model.score(X_test_scaled, y_test)print("{} Test Set Accuracy: {}".format(name, test_score))
Logistic Regression Test Set Accuracy: 0.844
KNN Test Set Accuracy: 0.82
Decision Tree Test Set Accuracy: 0.832
Passons à la pratique !
Apprentissage supervisé avec scikit-learn

