Validation croisée
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée

Les bases de la validation croisée
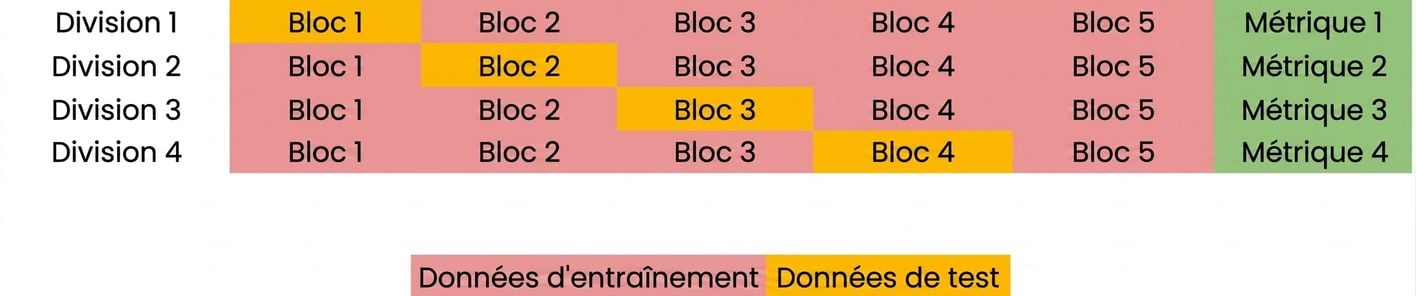
Les bases de la validation croisée


