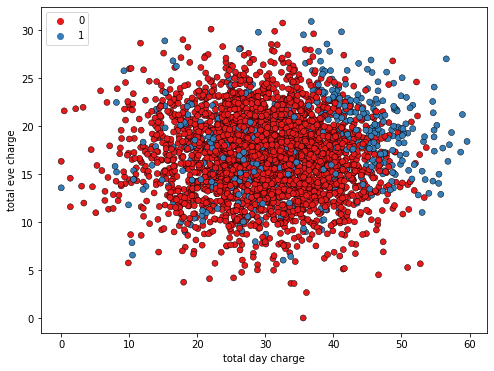
Le défi de la classification
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
k plus proches voisins
k plus proches voisins
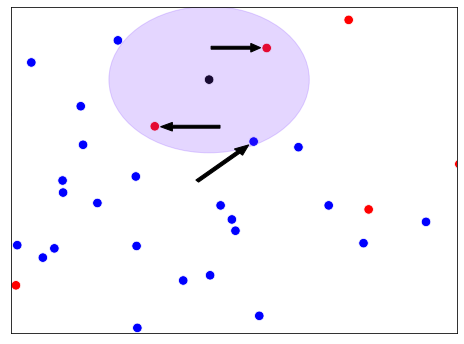
k plus proches voisins
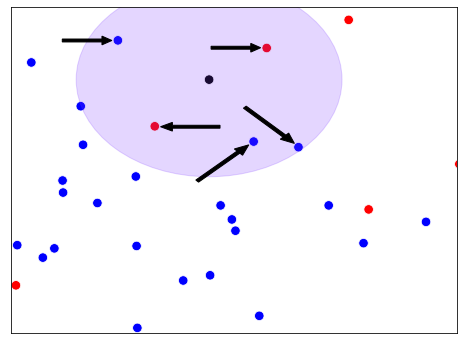
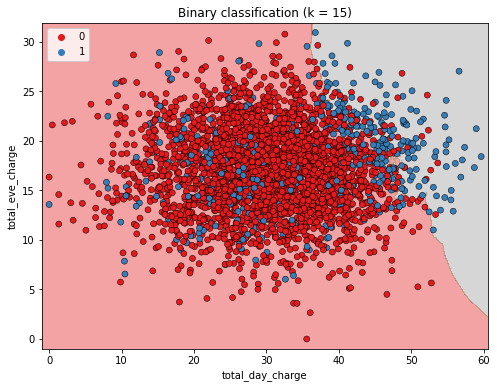
Intuition KNN
Intuition KNN
Apprentissage supervisé avec scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

