Prétraitement des données
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Variables nominales

Variables nominales
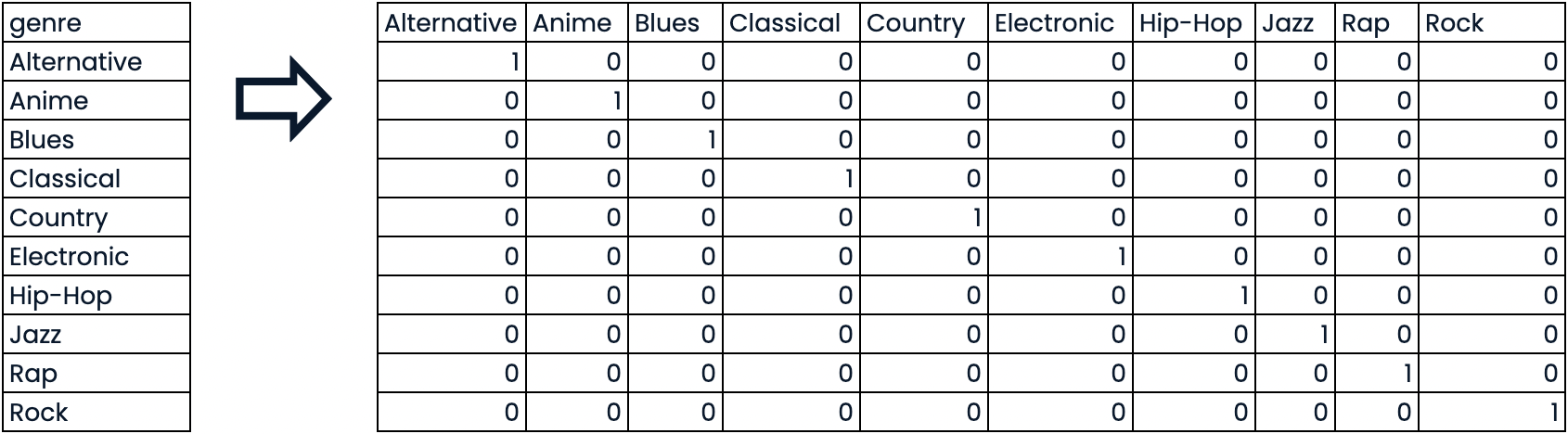
Variables nominales
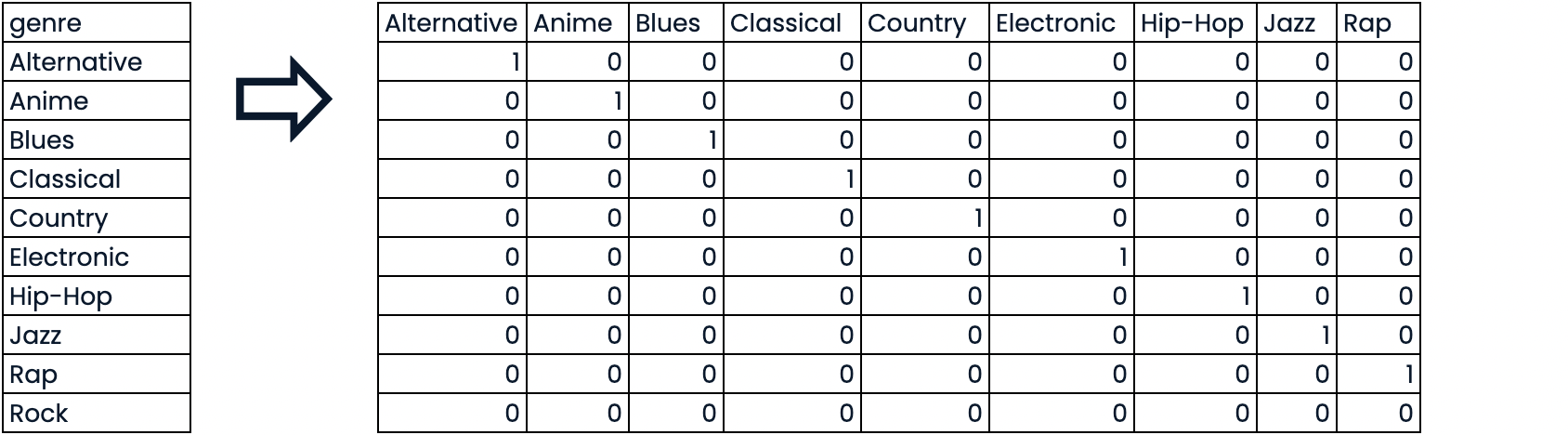
AED avec caractéristique catégorielle
Apprentissage supervisé avec scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

