Les bases de la régression linéaire
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
La fonction de perte
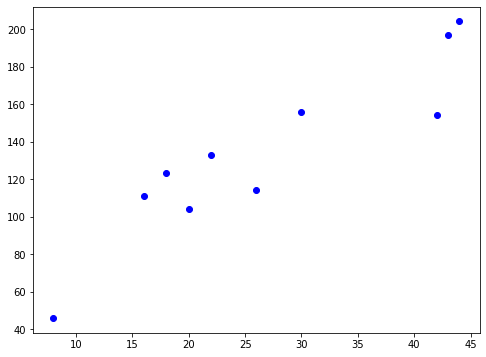
La fonction de perte
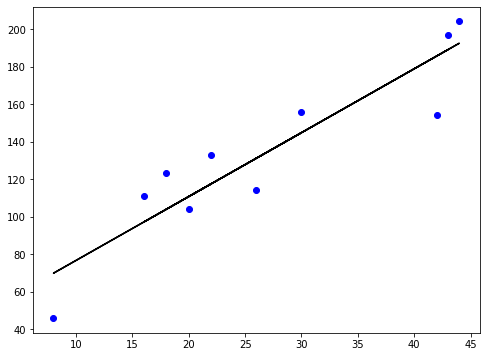
La fonction de perte
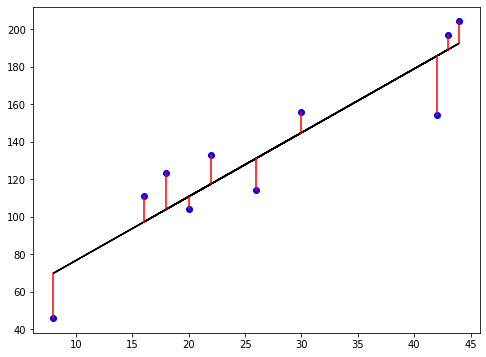
La fonction de perte
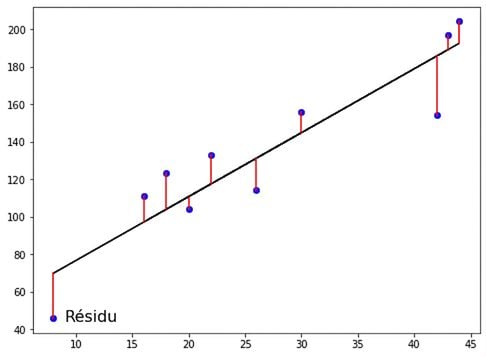
La fonction de perte
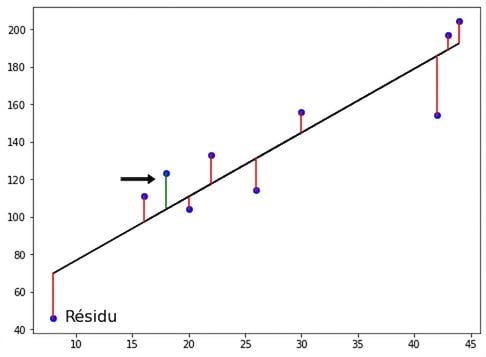
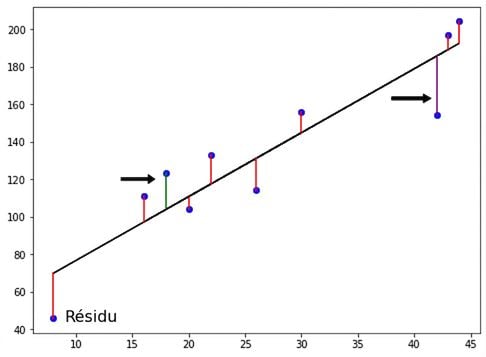
Moindres carrés ordinaires
R-carré
$R^2$ : quantifie la variance des valeurs cibles expliquée par les caractéristiques
- Les valeurs sont comprises entre 0 et 1
$R^2$ élevé :
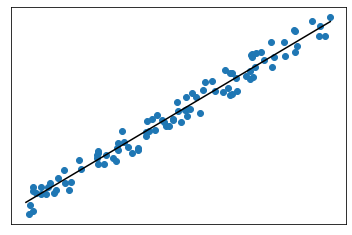
- $R^2$ faible :