Réglage des hyperparamètres
Apprentissage supervisé avec scikit-learn

George Boorman
Core Curriculum Manager
Validation croisée par recherche de grille
Validation croisée par recherche de grille
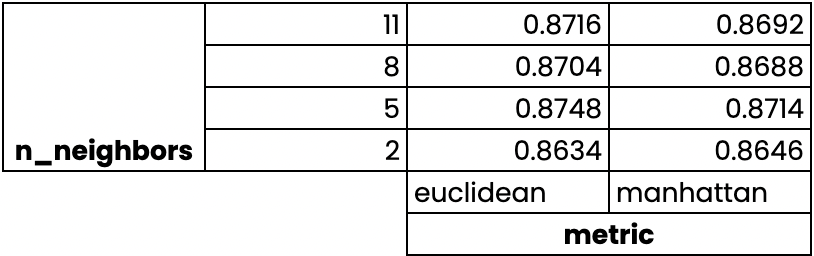
Validation croisée par recherche de grille
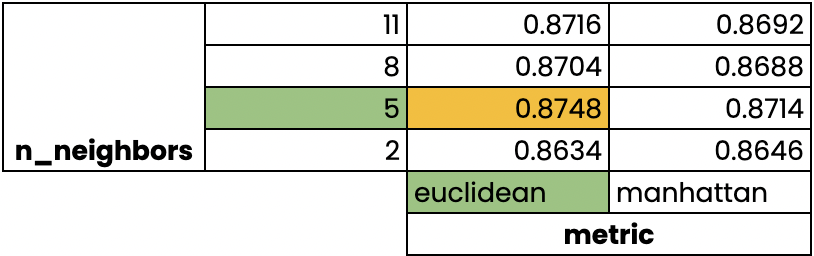
Apprentissage supervisé avec scikit-learn
George Boorman
Core Curriculum Manager

