Video generation
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Video generation
![]()
1 https://link.springer.com/article/10.1007/s11263-024-02271-9
Video generation

1 https://huggingface.co/THUDM/CogVideoX-2b
Video generation

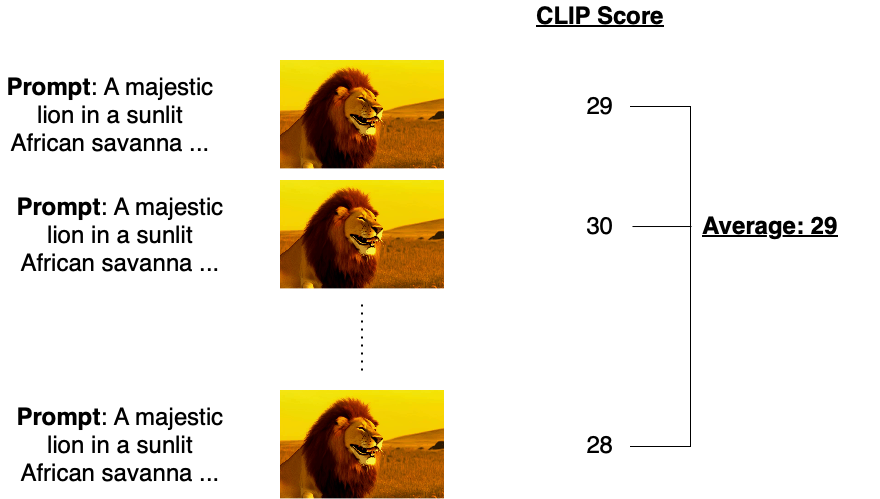
Quantitative analysis
- Prompt adherence difficult for videos
- CLIP provides a possible strategy: