Speech recognition and audio generation
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Speech

Automatic speech recognition

Speech embeddings
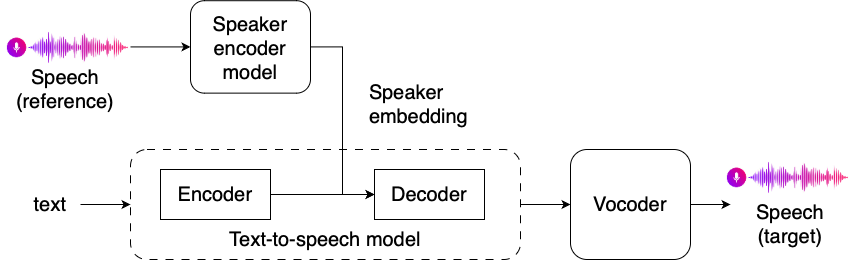
Audio generation
inputs = processor(audio=dataset[0]["audio"], sampling_rate=dataset[0]["audio"]["sampling_rate"], return_tensors="pt")speech = model.generate_speech(inputs["input_values"], speaker_embedding, vocoder=vocoder)