Zero-shot image classification
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
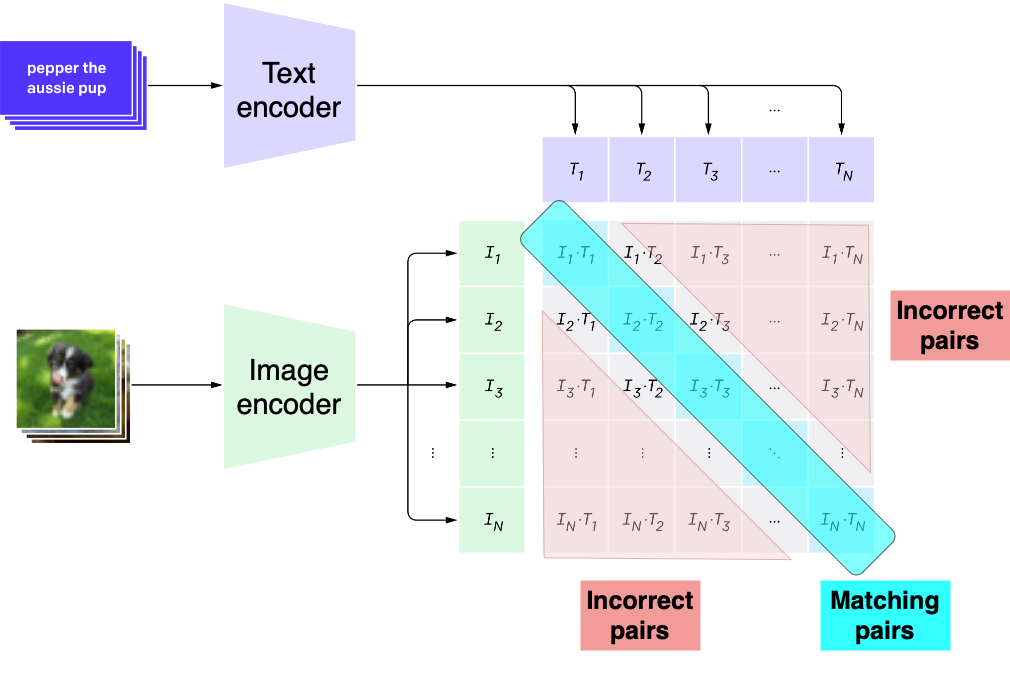
CLIP
1 https://openai.com/index/clip/
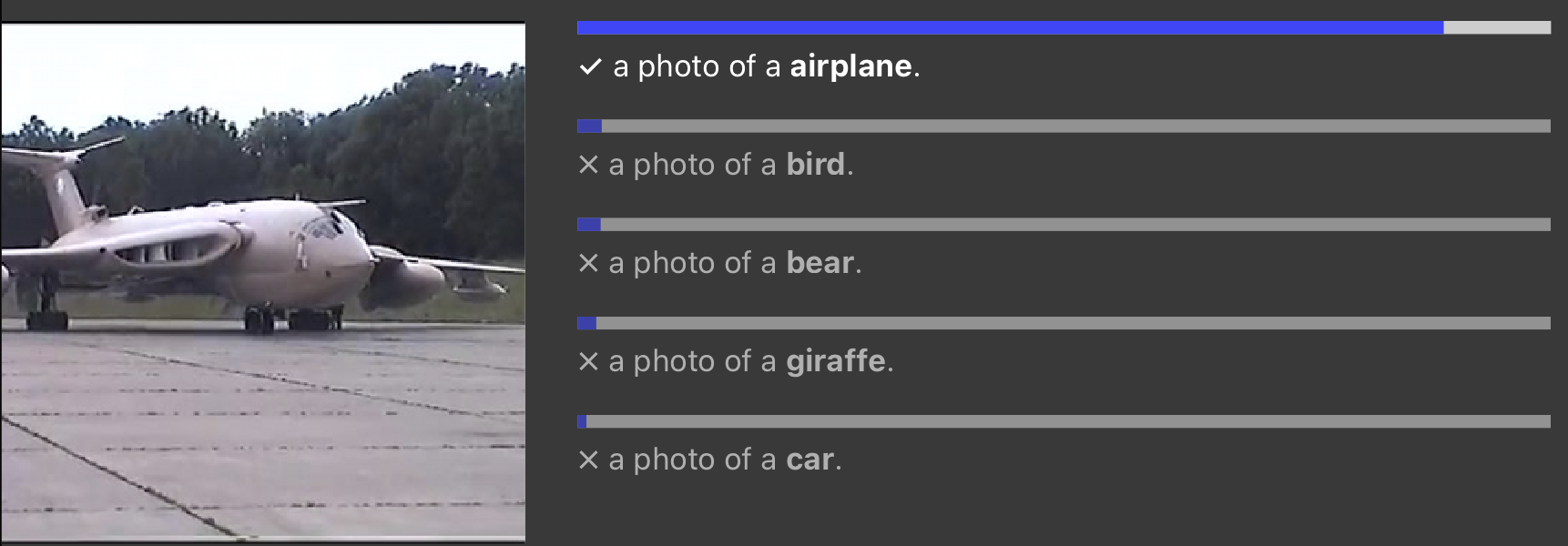
Zero-shot learning
- Perform tasks that the model wasn't trained for
1 https://openai.com/index/clip/
Use case: product categorization