Preprocessing different modalities
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Preprocessing text

Preprocessing text

Preprocessing text
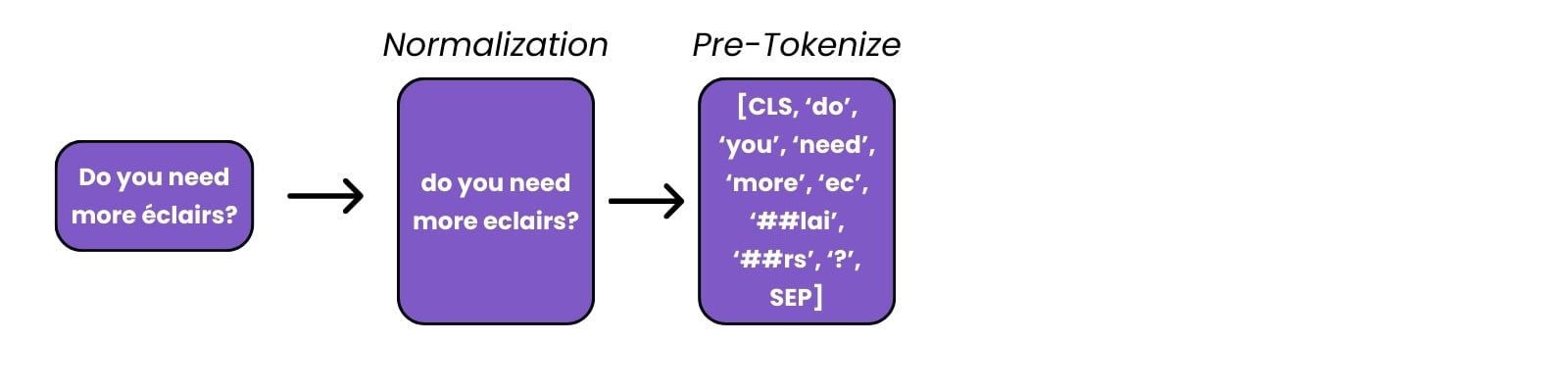
Preprocessing text
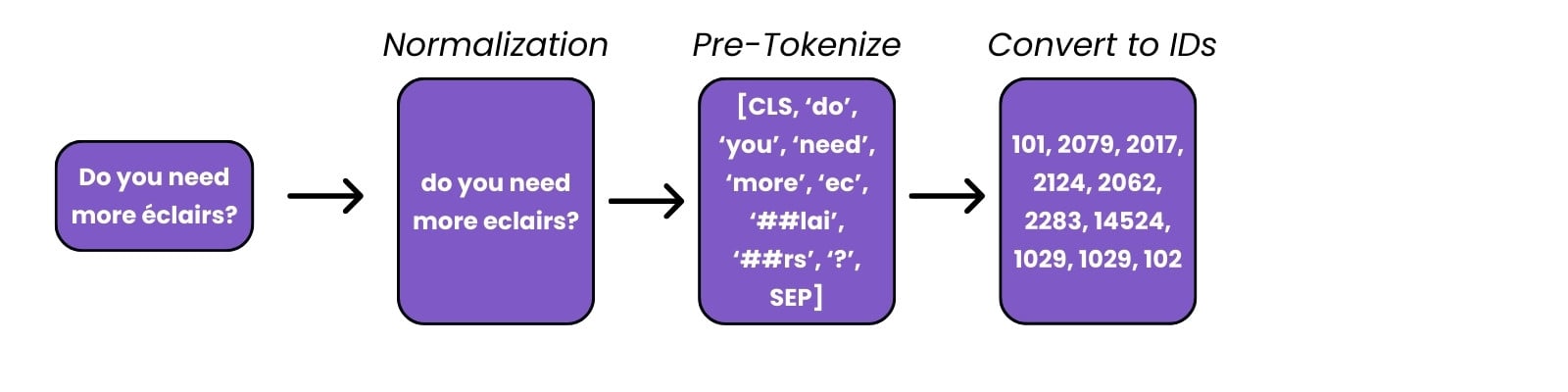
Preprocessing text
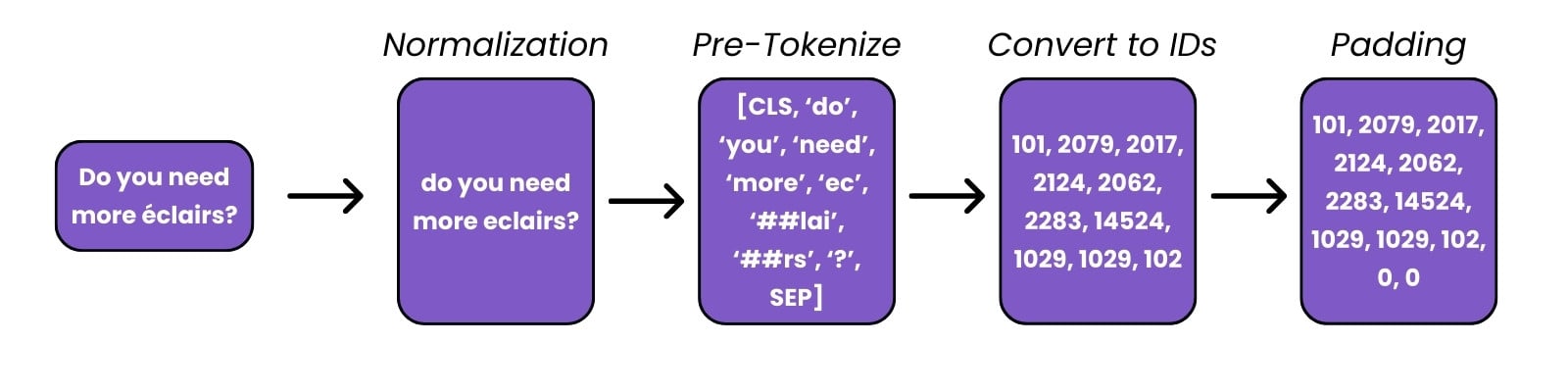
Preprocessing images
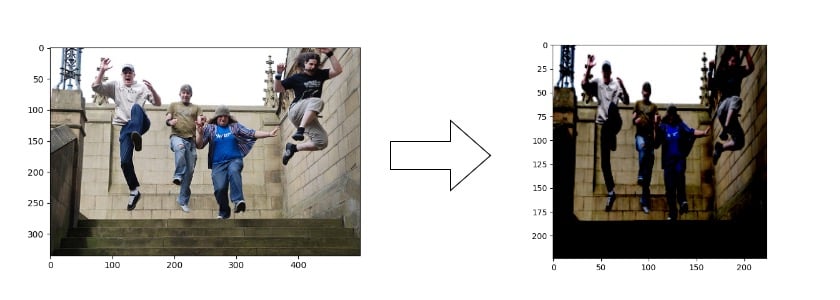
1 https://huggingface.co/datasets/nlphuji/flickr30k
Preprocessing audio
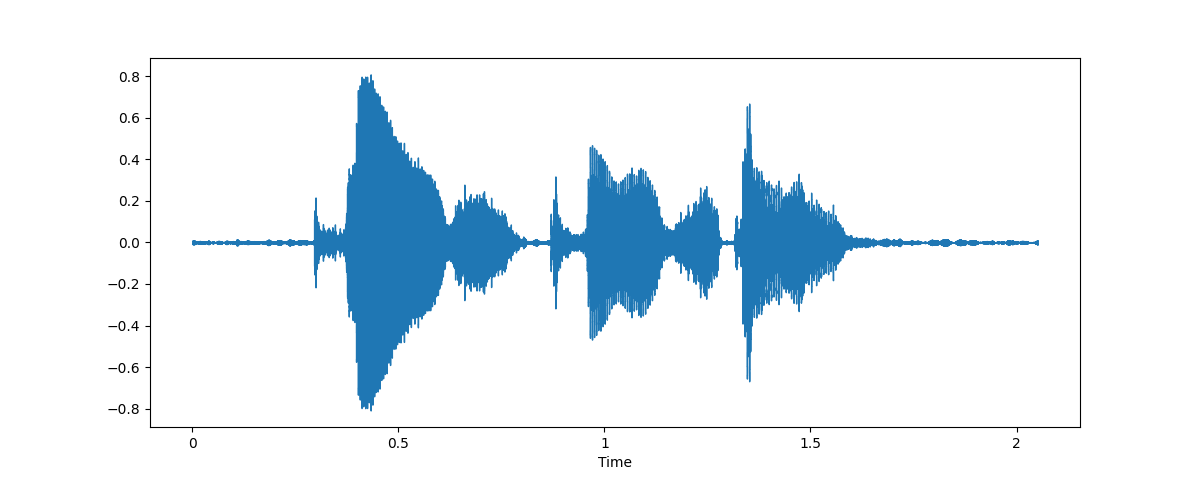
- Audio preprocessing:
- Sequential array → filter/padding
- Sampling rate → resampling
Feature extraction as model input (spectrogram)