Computer vision
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
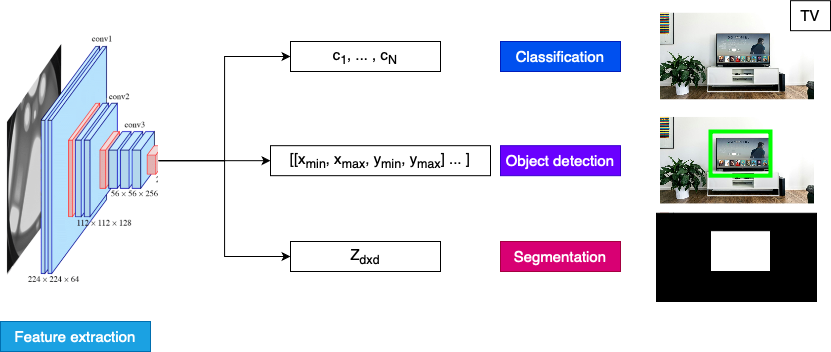
Vision models
1 https://arxiv.org/abs/1409.1556
Classification
from datasets import load_dataset
dataset = load_dataset("nlphuji/flickr30k")
image = dataset['test'][134]["image"]

Object detection
dataset['test'][52]["image"]

Object detection

Segmentation

- Output: 2D array with same dimensions as input
- Background removal: each pixel is
1(foreground) or0(background) - Image $\times$ Output → Image with background removed
Segmentation


