Visual question-answering (VQA)
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Multimodal QA tasks
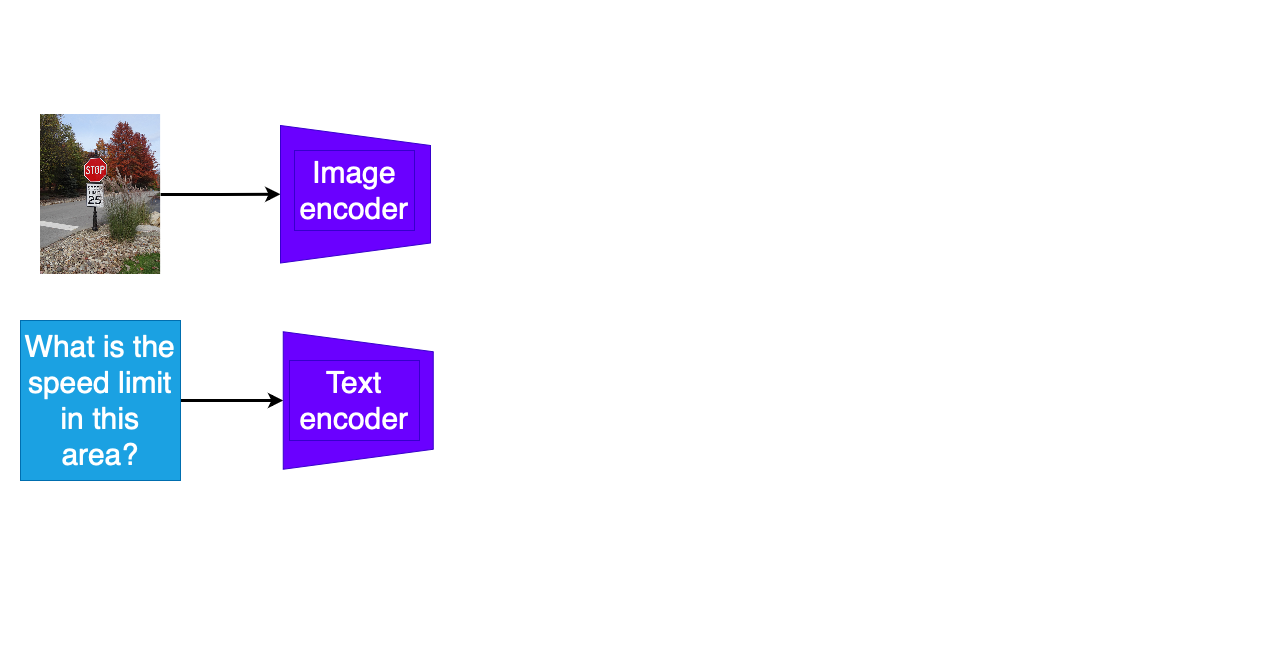
- Separate encoding of question text and other modality
Multimodal QA tasks
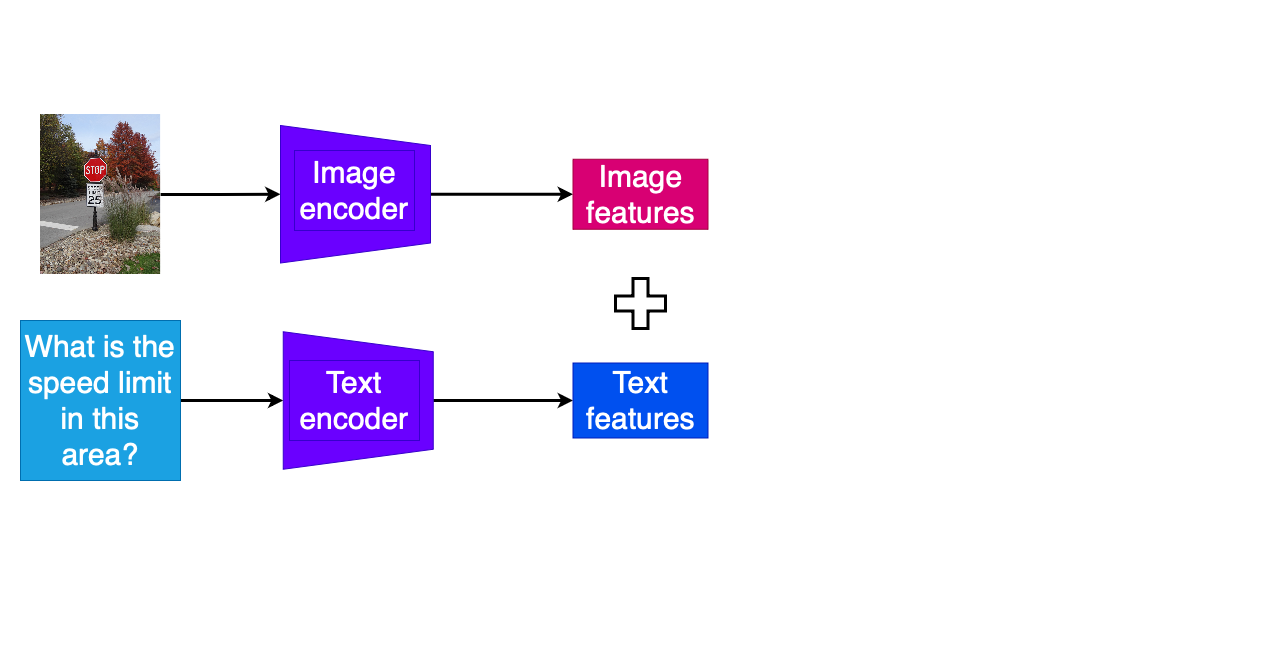
- Separate encoding of question text and other modality
- Combination of encoded features
Multimodal QA tasks
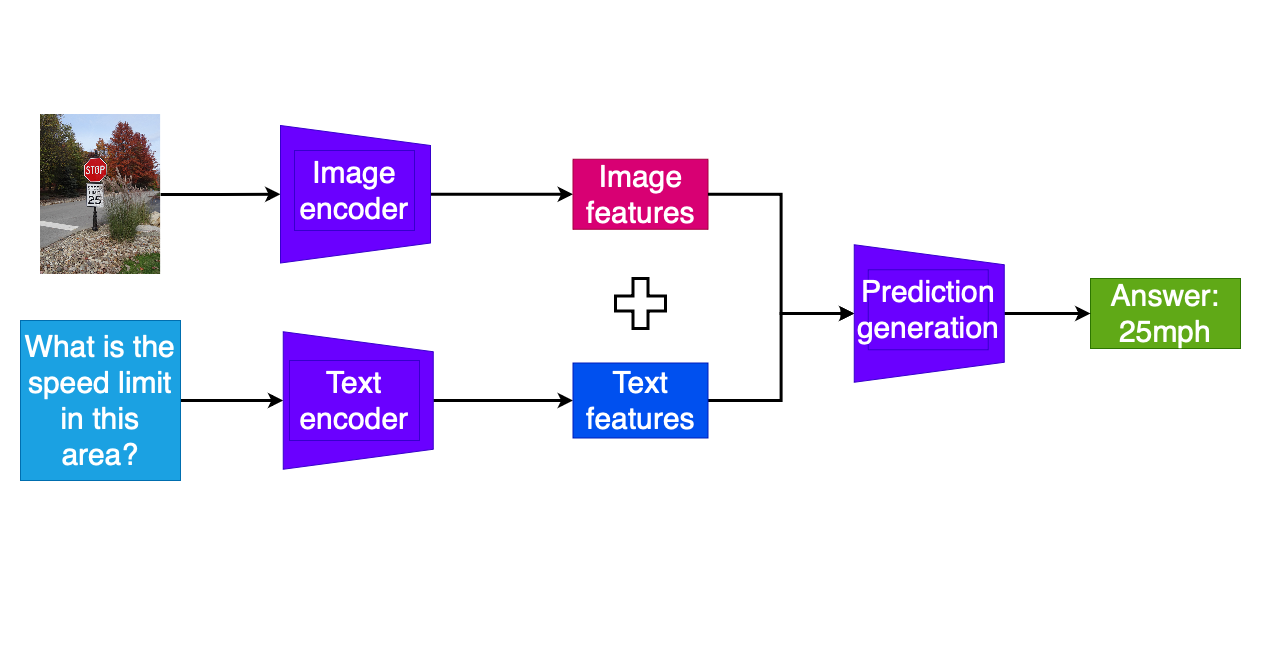
- Separate encoding of question text and other modality
- Combination of encoded features
- Additional model layers to predict answer tokens
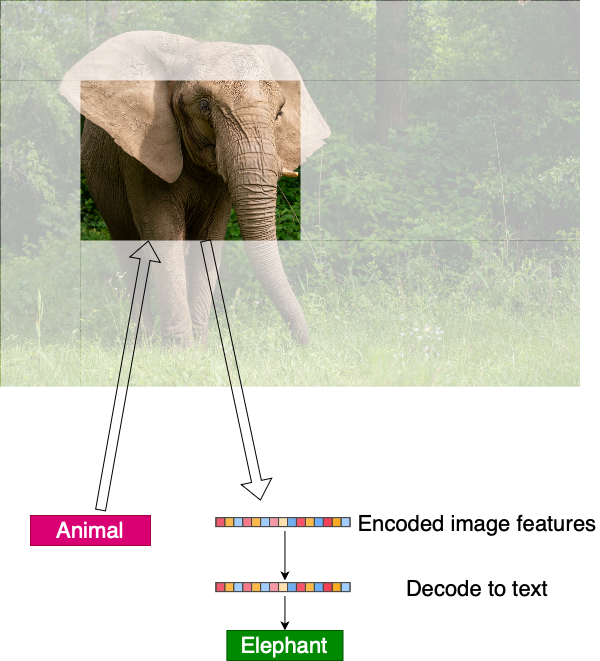
VQA

VQA
Document VQA
Document VQA

- Extra dependencies needed to run OCR
pytesseractinstalled viapip- Tesseract OCR via package installer (e.g.
apt-get,exeorhomebrew/macports)

Document VQA