Image editing with diffusion models
Multi-Modal Models with Hugging Face

James Chapman
Curriculum Manager, DataCamp
Diffusers

- Trained to map noise to an image
- CLIP + Diffusion → 2 types of conditional generation
- Generation: Text → image
- Modification: Text+image → image
1 https://huggingface.co/docs/diffusers
Custom image editing
ControlNet: image and text-guided conditional generation
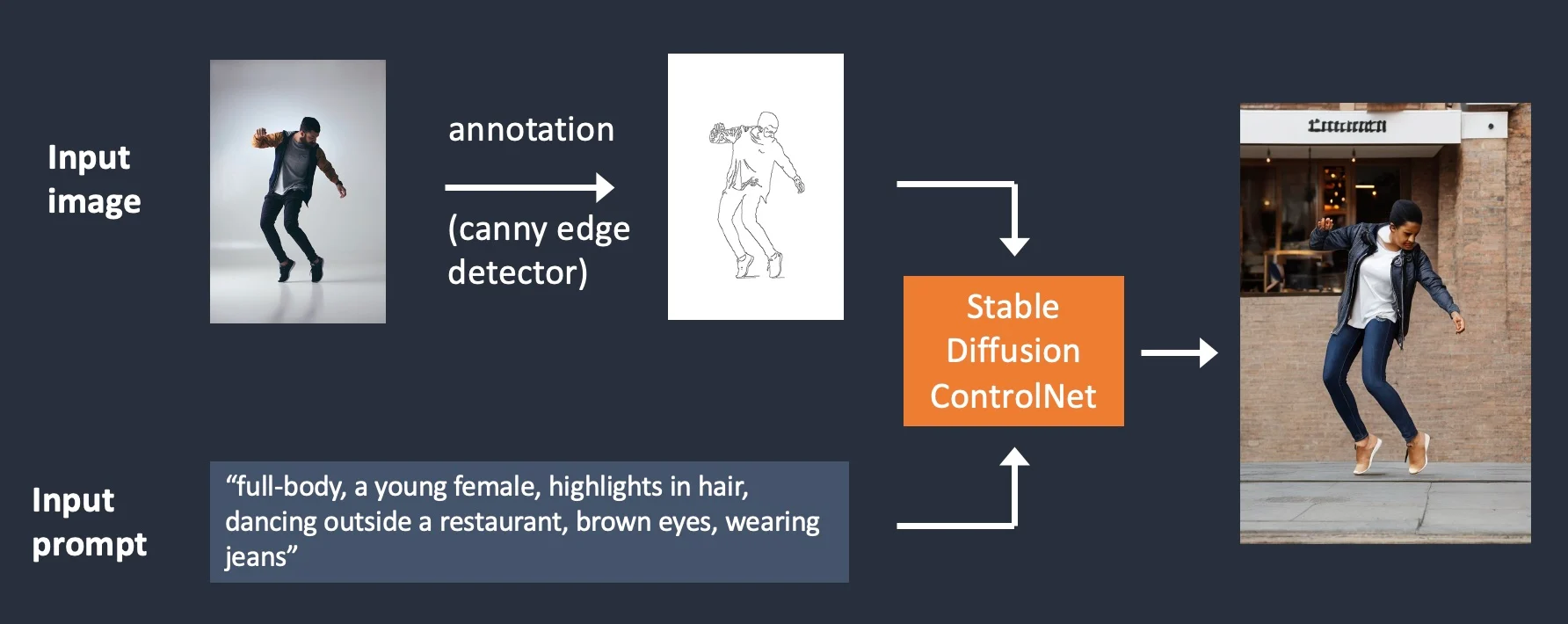
1 https://stable-diffusion-art.com/controlnet/
Custom image editing

Custom image editing

Custom image editing

Image inpainting

Image inpainting

Image inpainting


