Exploration initiale
Analyse de données exploratoires en Python

Izzy Weber
Curriculum Manager, DataCamp
Analyse exploratoire des données (EDA)

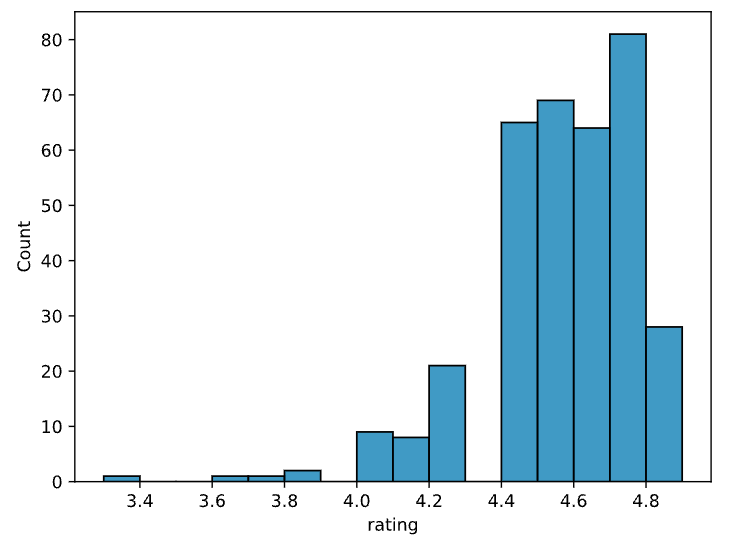
Visualisation de données numériques
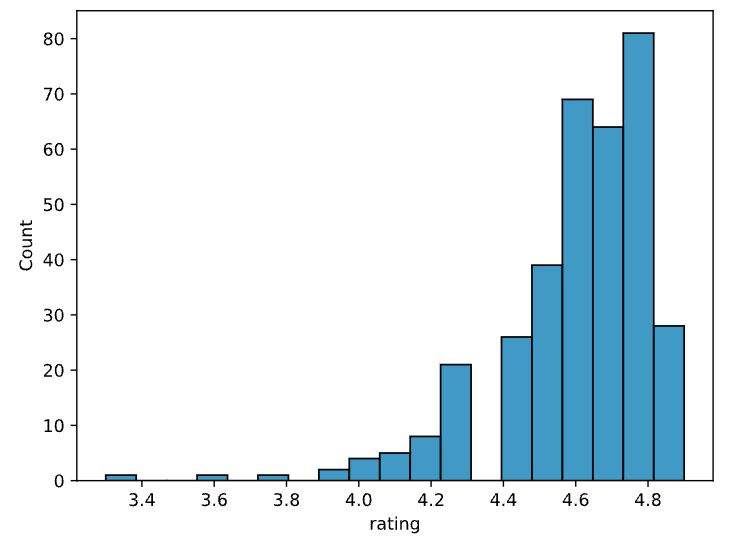
Analyse de données exploratoires en Python
Izzy Weber
Curriculum Manager, DataCamp


{kind=link}