Traiter les données manquantes
Analyse de données exploratoires en Python

George Boorman
Curriculum Manager, DataCamp
Pourquoi les données manquantes constituent-elles un problème ?
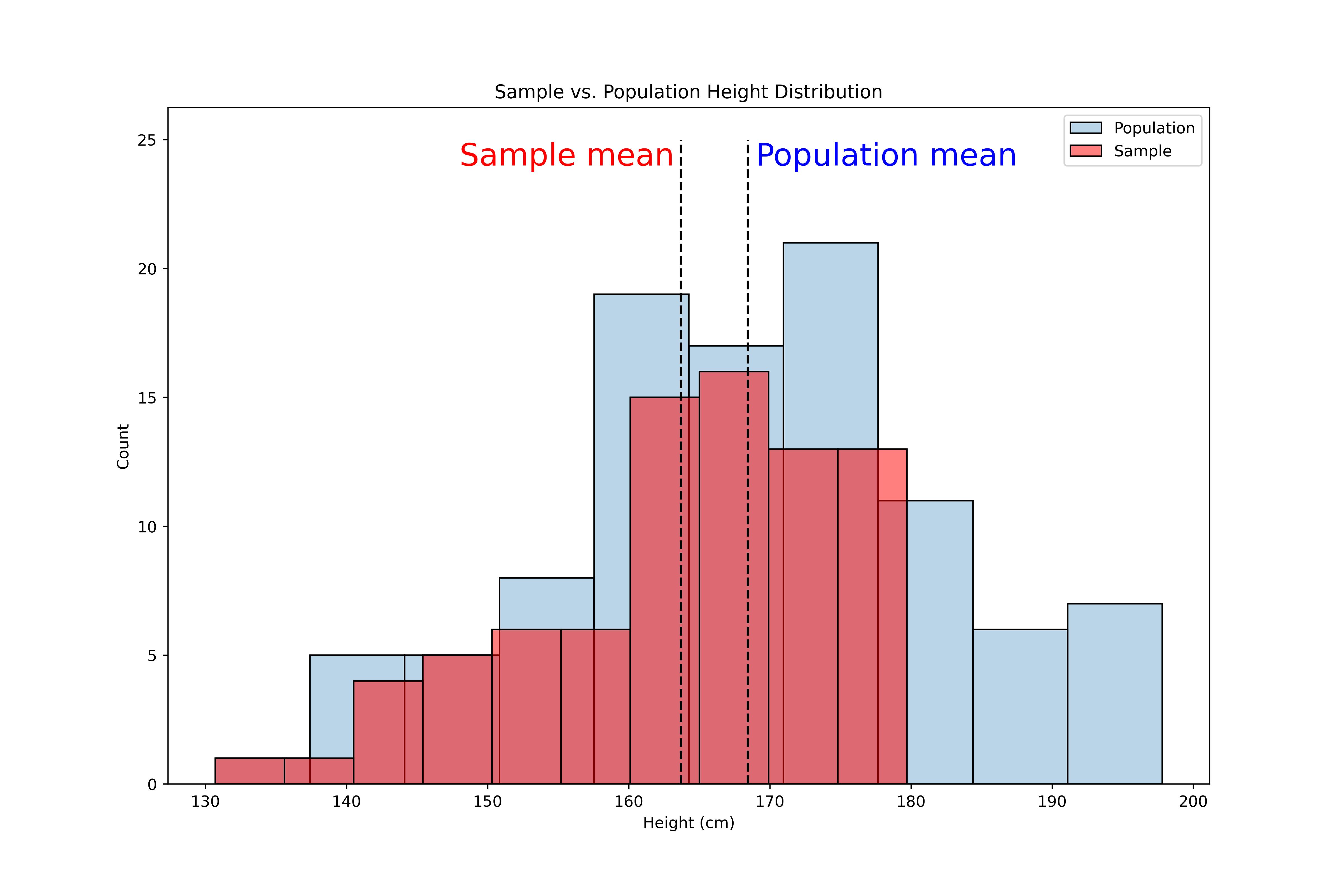
Salaire en fonction du niveau d'expérience
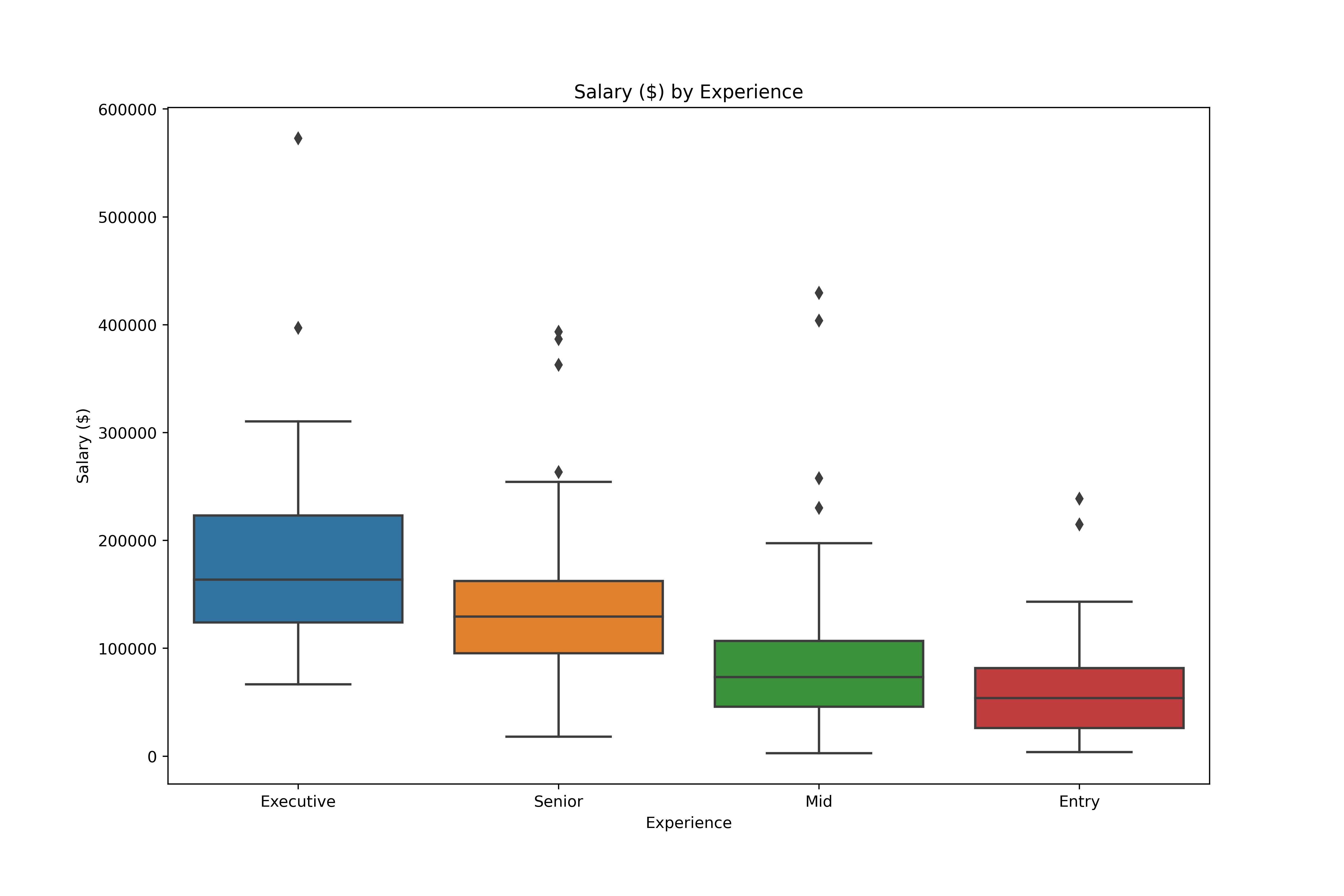
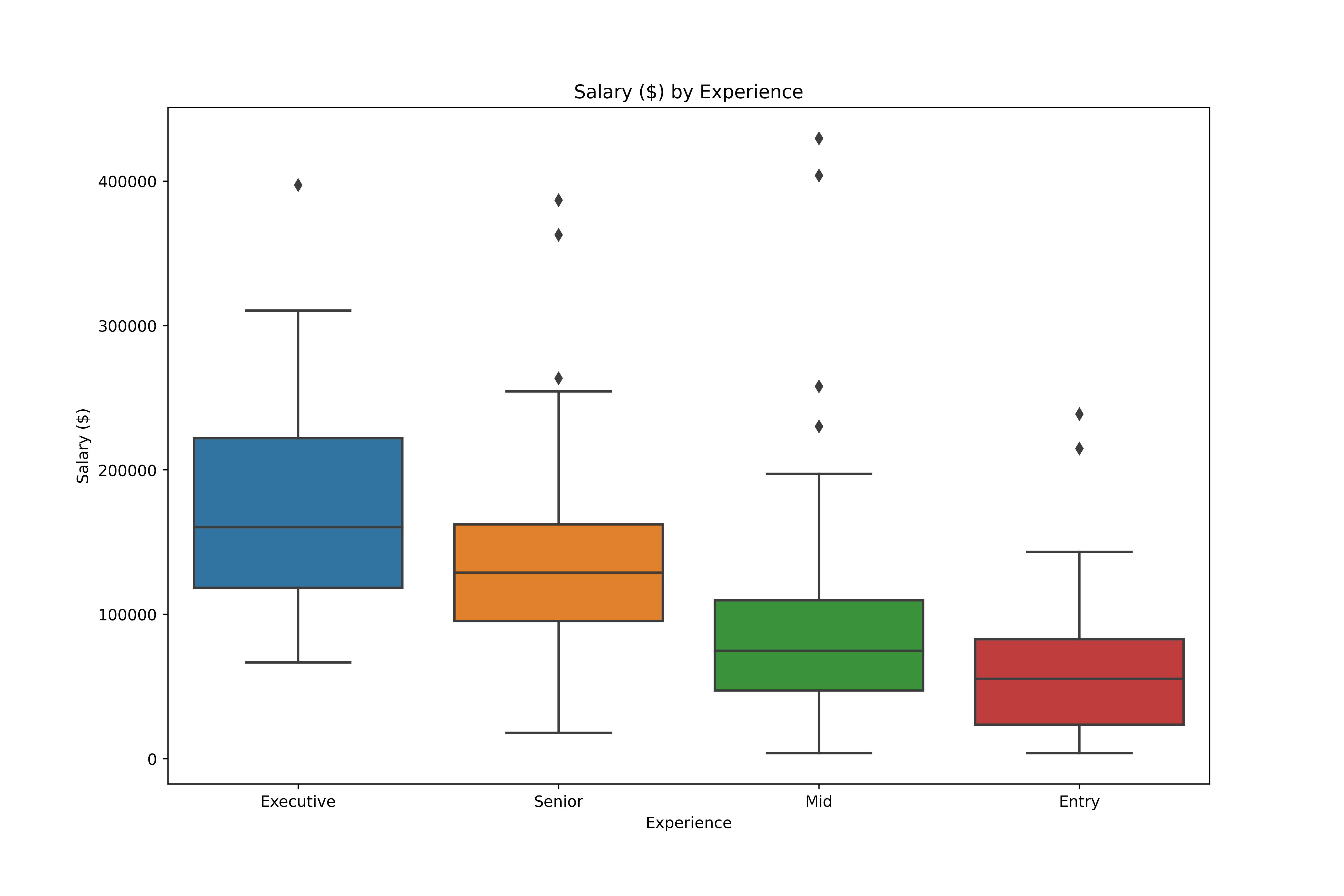
Analyse de données exploratoires en Python
George Boorman
Curriculum Manager, DataCamp

