Lier des DataFrames
Nettoyage des données en Python

Adel Nehme
VP of AI Curriculum, DataCamp
Couplage de données
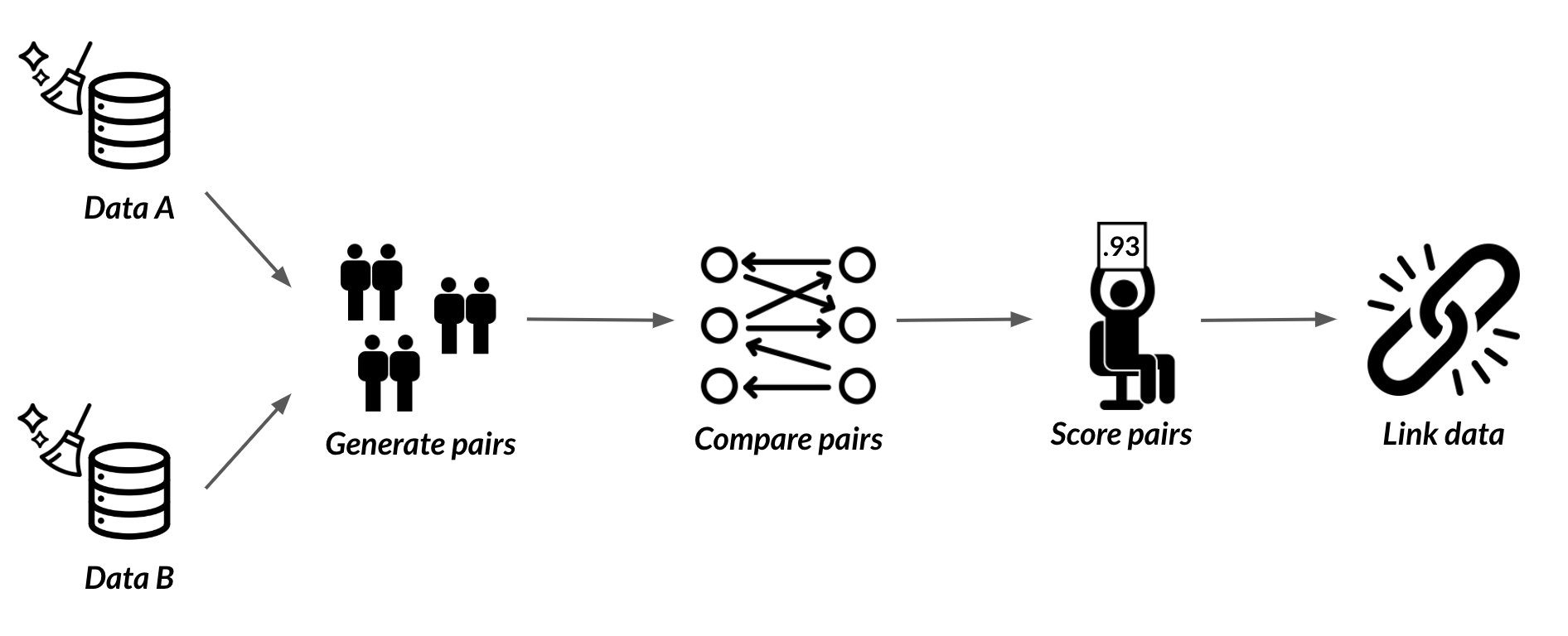
Couplage de données
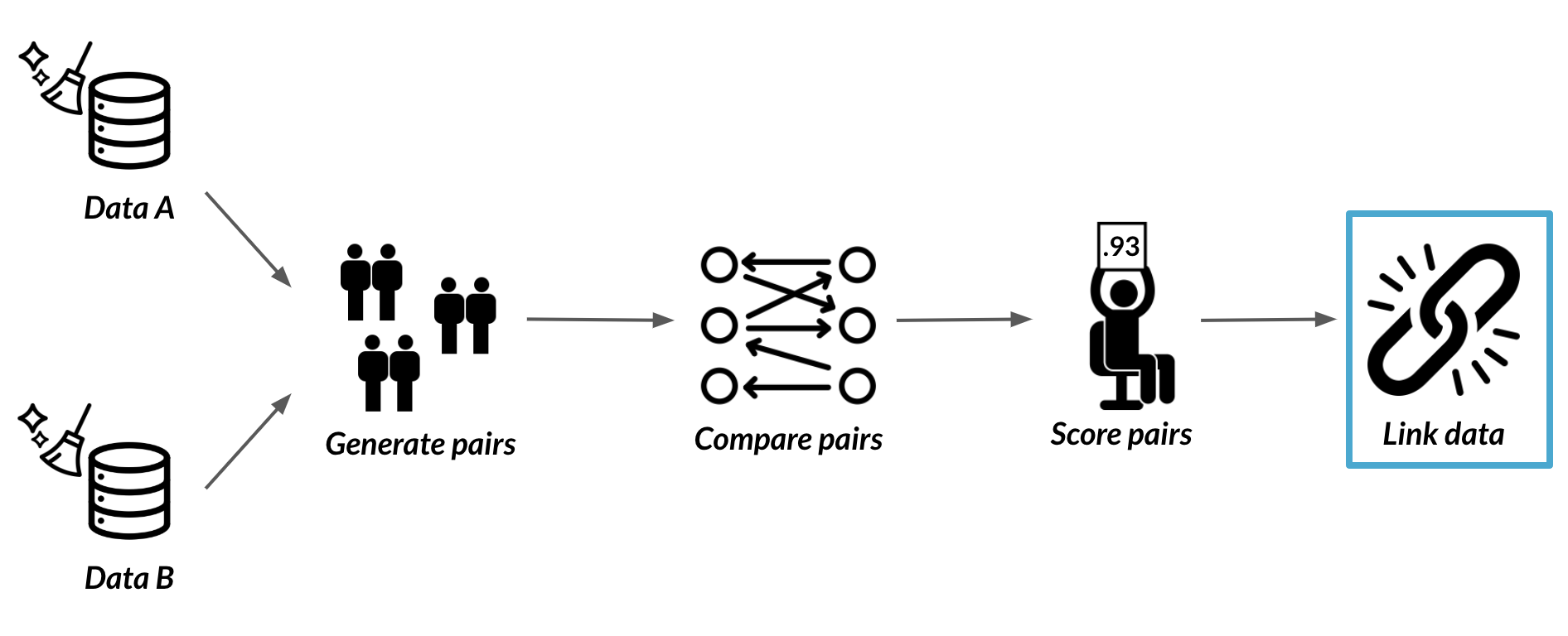
Ce que nous faisons actuellement
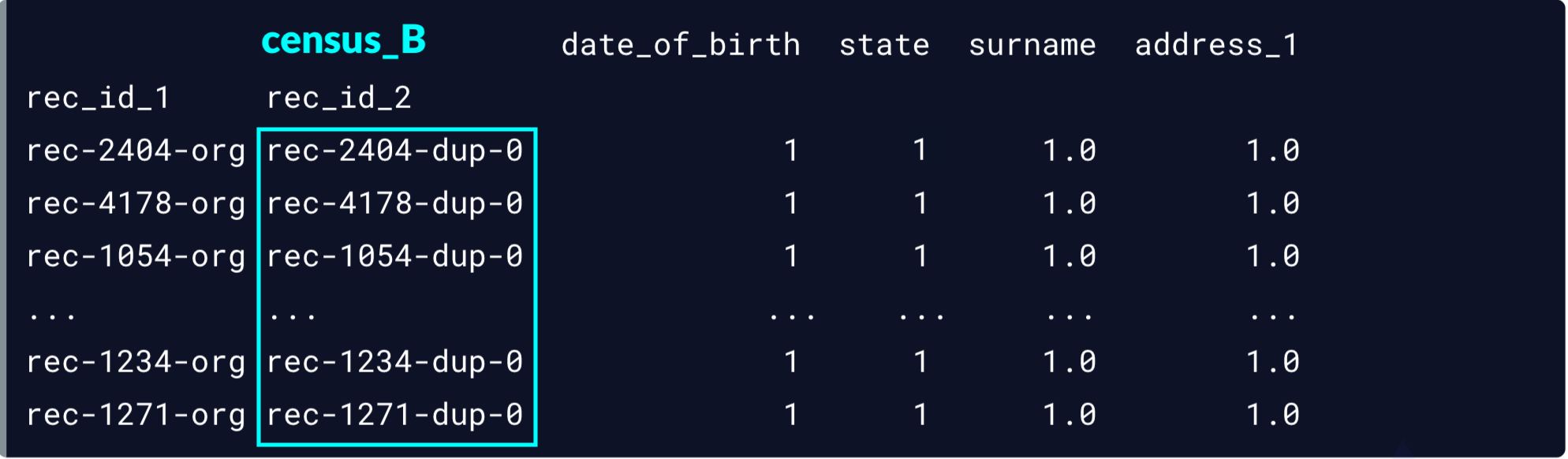
Nos correspondances potentielles
potential_matches
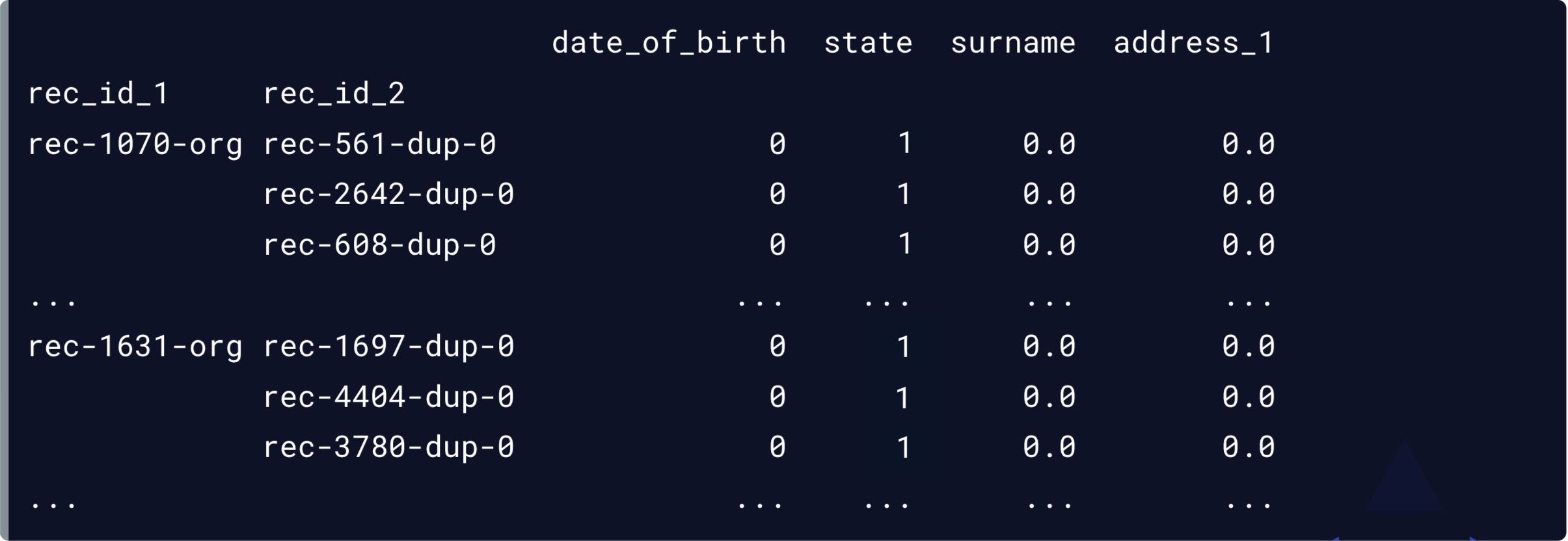
Nos correspondances potentielles
potential_matches
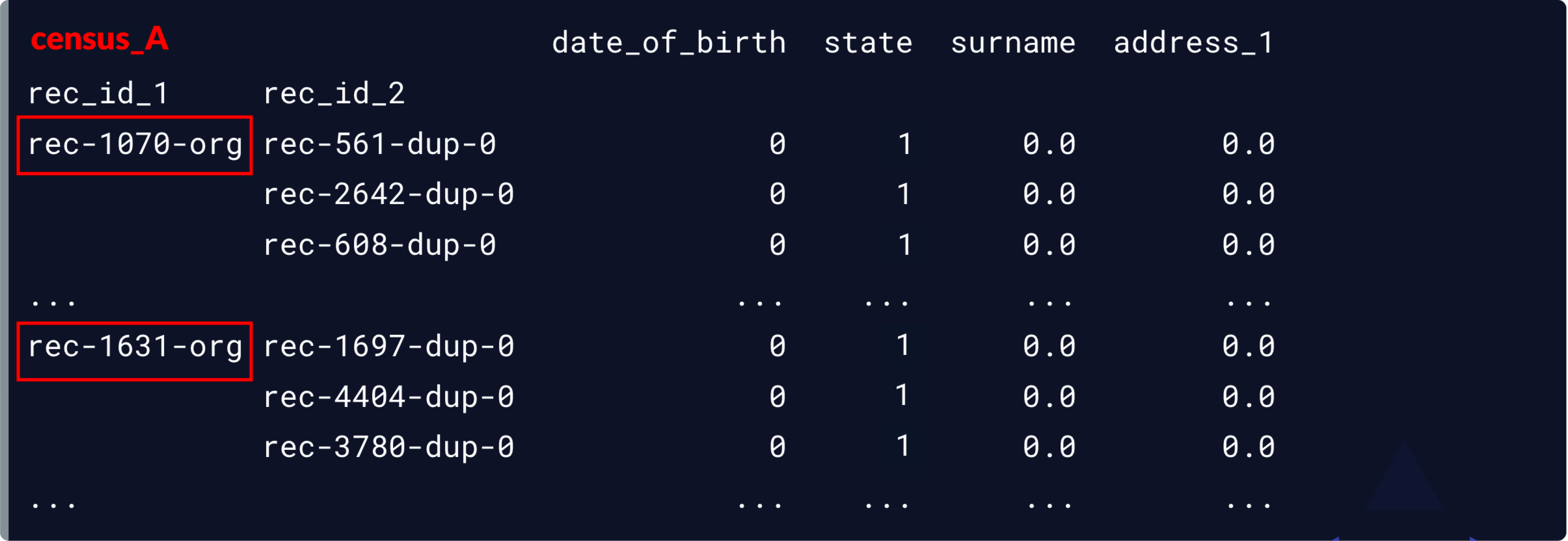
Nos correspondances potentielles
potential_matches
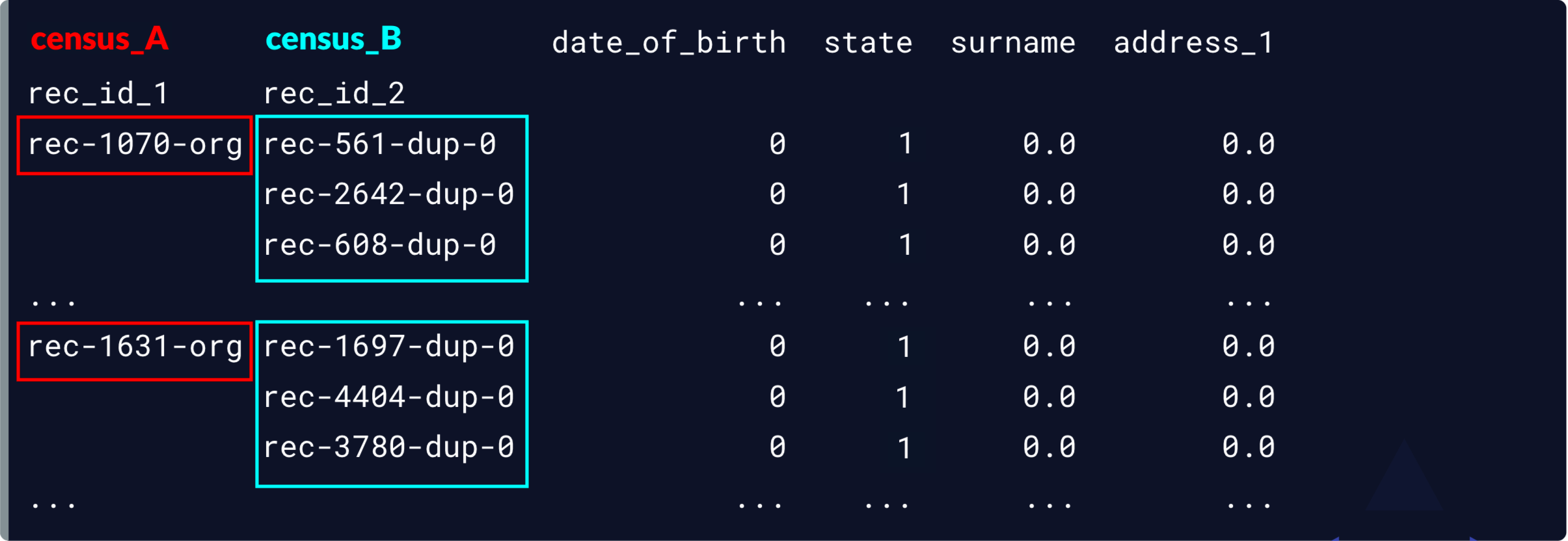
Nos correspondances potentielles
potential_matches
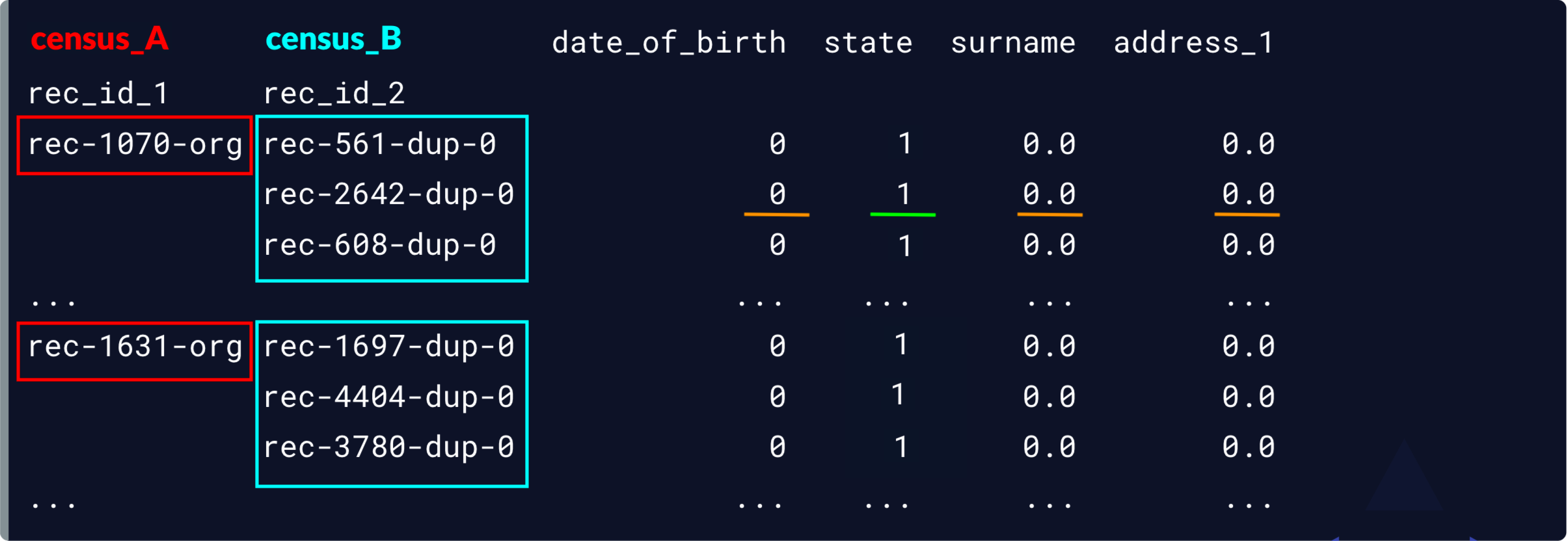
Correspondances probables
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)
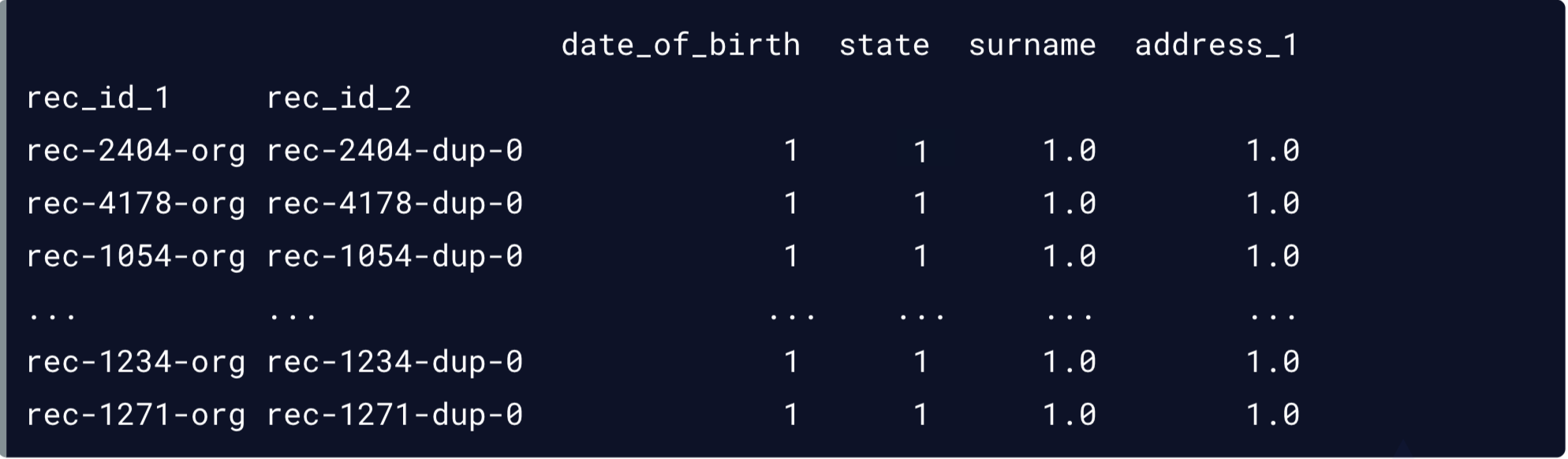
Correspondances probables
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)