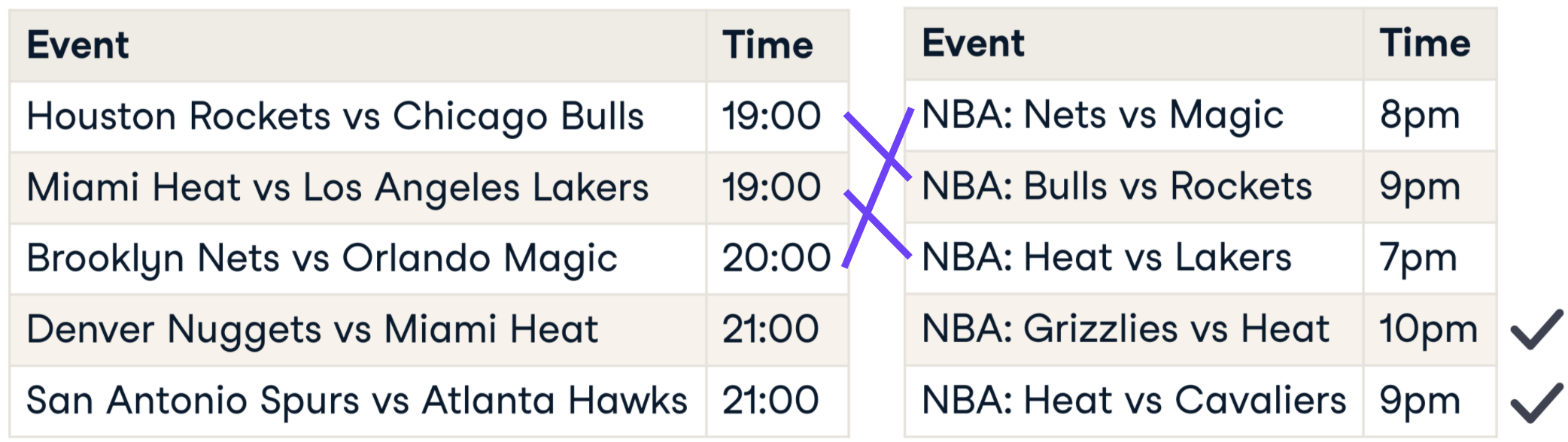
Comparaison de chaînes de caractères
Nettoyage des données en Python

Adel Nehme
VP of AI Curriculum, DataCamp
Distance minimale d'édition
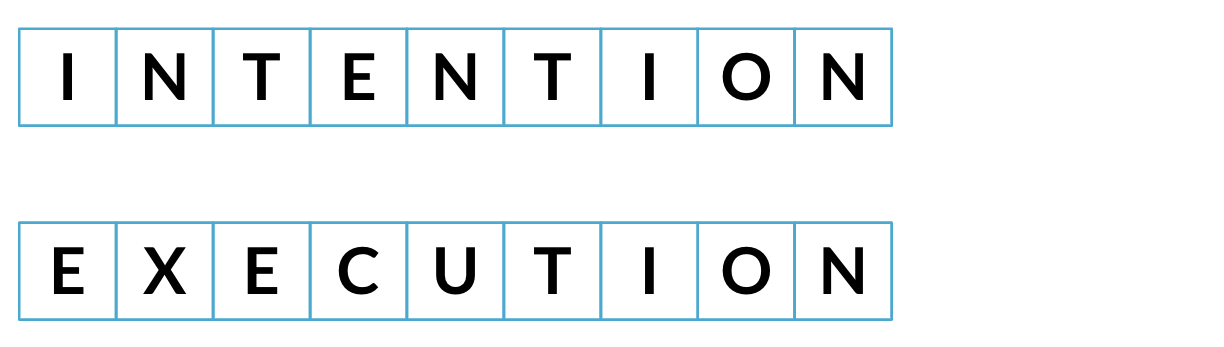
Le nombre minimal d'étapes nécessaires pour passer d'une chaîne à une autre
Distance minimale d'édition
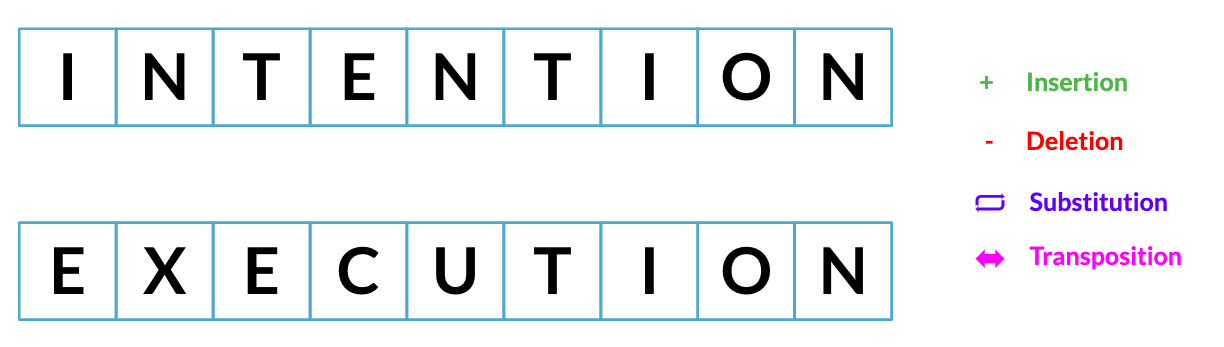
Le nombre minimal d'étapes nécessaires pour passer d'une chaîne à une autre
Distance minimale d'édition

Distance minimale d'édition
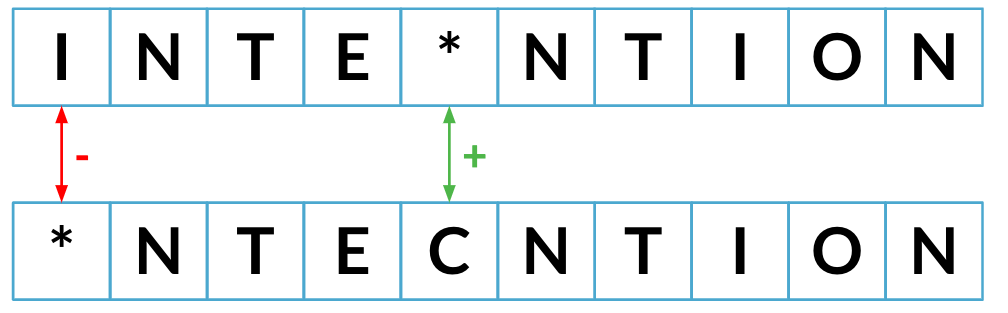
Distance d'édition minimale jusqu'à présent : 2
Distance minimale d'édition
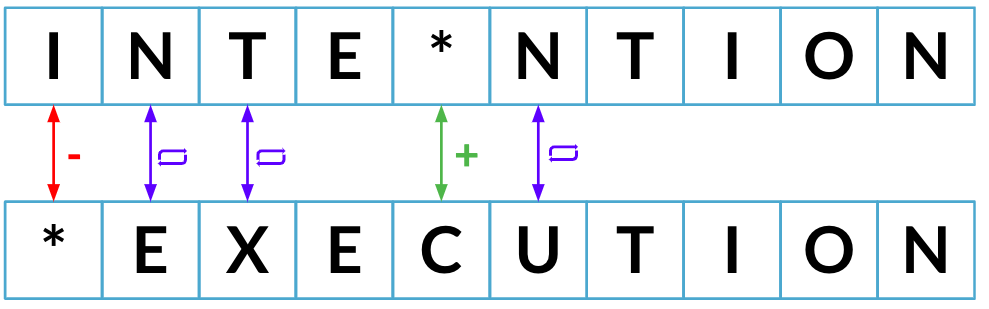
Distance minimale d’édition : 5
Distance minimale d'édition

Couplage de données