Contraintes d'adhésion
Nettoyage des données en Python

Adel Nehme
Content Developer @DataCamp
Pourquoi pourrions-nous rencontrer ces difficultés ?

Comment traitons-nous ces problèmes ?
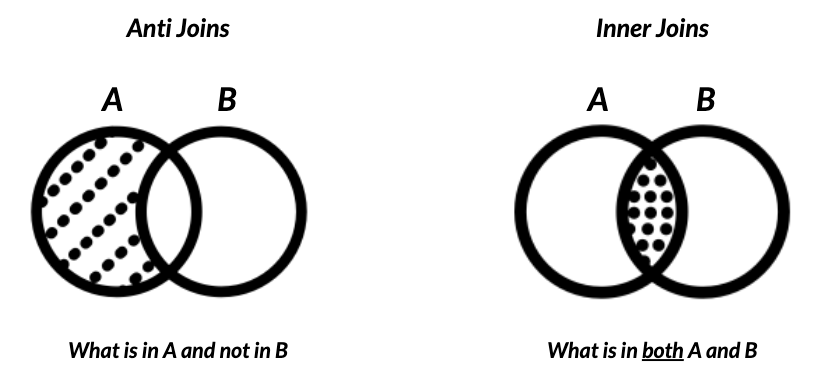
Remarque sur les jointures
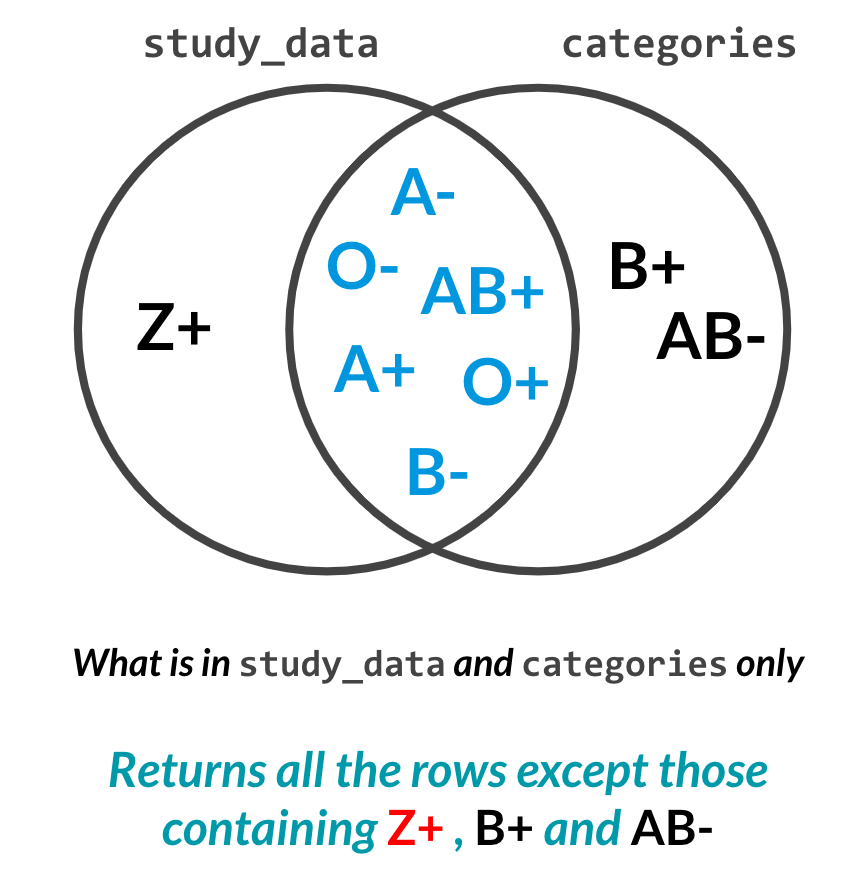
Une anti-jointure gauche sur les groupes sanguins
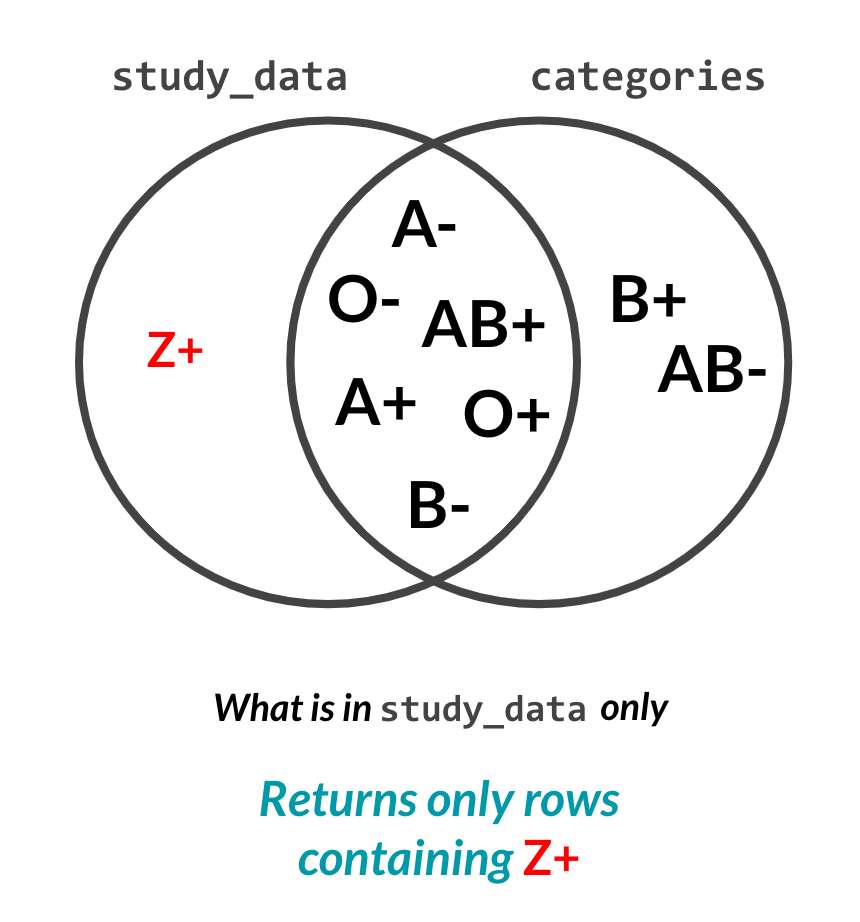
Une jointure interne sur les groupes sanguins