Data Intelligence Platform - Calcul
Introduction à Databricks

Kevin Barlow
Data Practitioner
Pourquoi les organisations accordent-elles de l’importance à l’informatique ?


Apache Spark
Types de clusters
Types de clusters
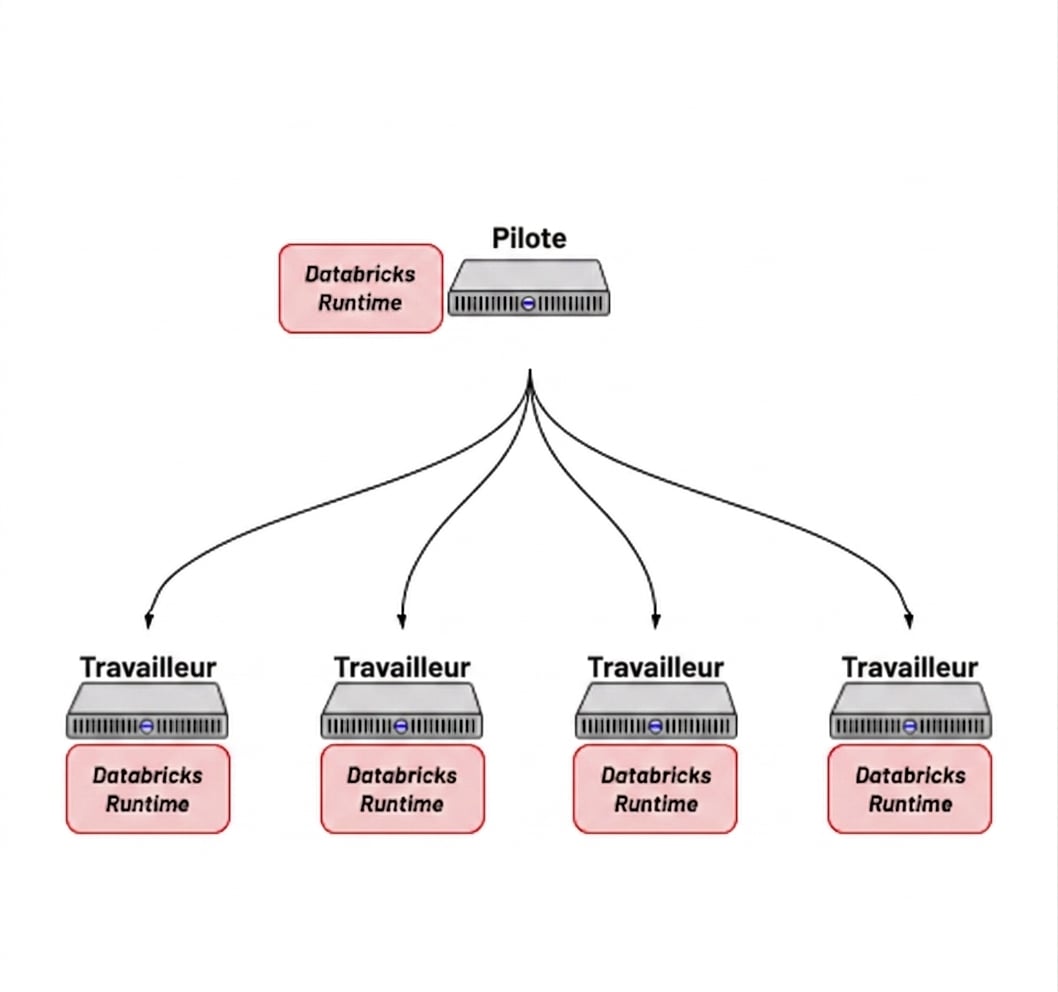
Nœud unique vs. Multi-nœuds
Nœud unique
- Cluster avec uniquement un nœud Driver
- Peut toujours exécuter Spark
- Peut également exécuter des frameworks à nœud unique (c’est-à-dire pandas)
- Idéal pour les petits jeux de données

Multi-nœud
- Cluster avec un nœud pilote et un ou plusieurs nœuds de travail
- Spark peut répartir le travail sur plusieurs nœuds
- Idéal pour les ensembles de données volumineux

Databricks Runtime