Améliorer les performances du modèle
Introduction au deep learning avec PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Étapes à suivre pour maximiser les performances


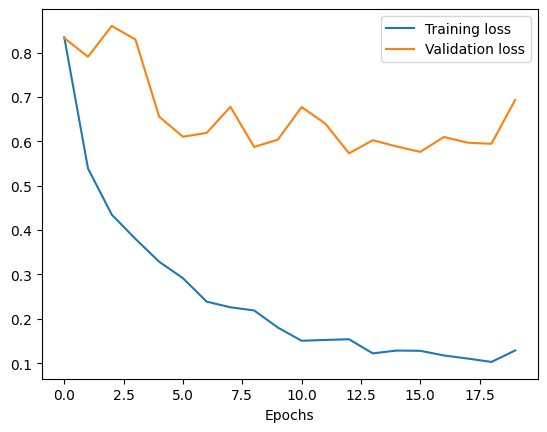
Étape 2 : réduction du surajustement
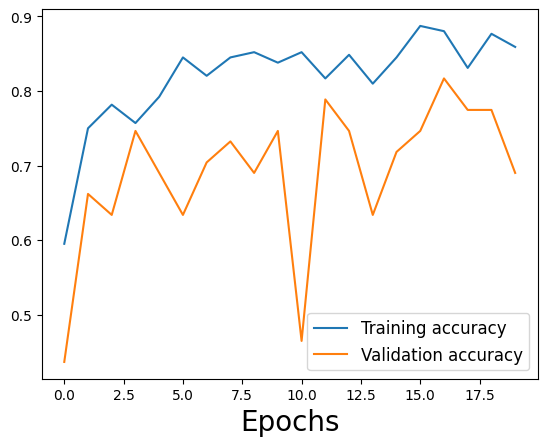
Étape 2 : réduction du surajustement
$$
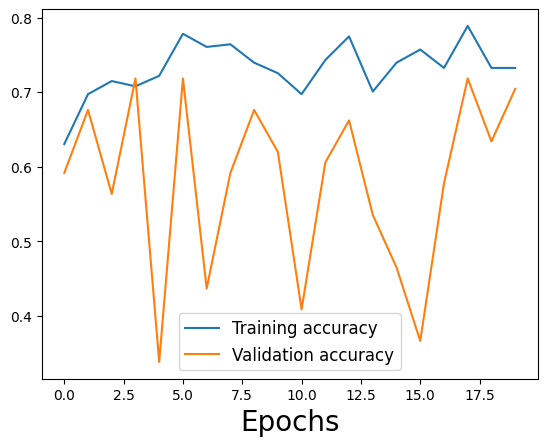
Le modèle original surajuste les données d’entraînement
$$
Modèle actualisé avec une régularisation excessive
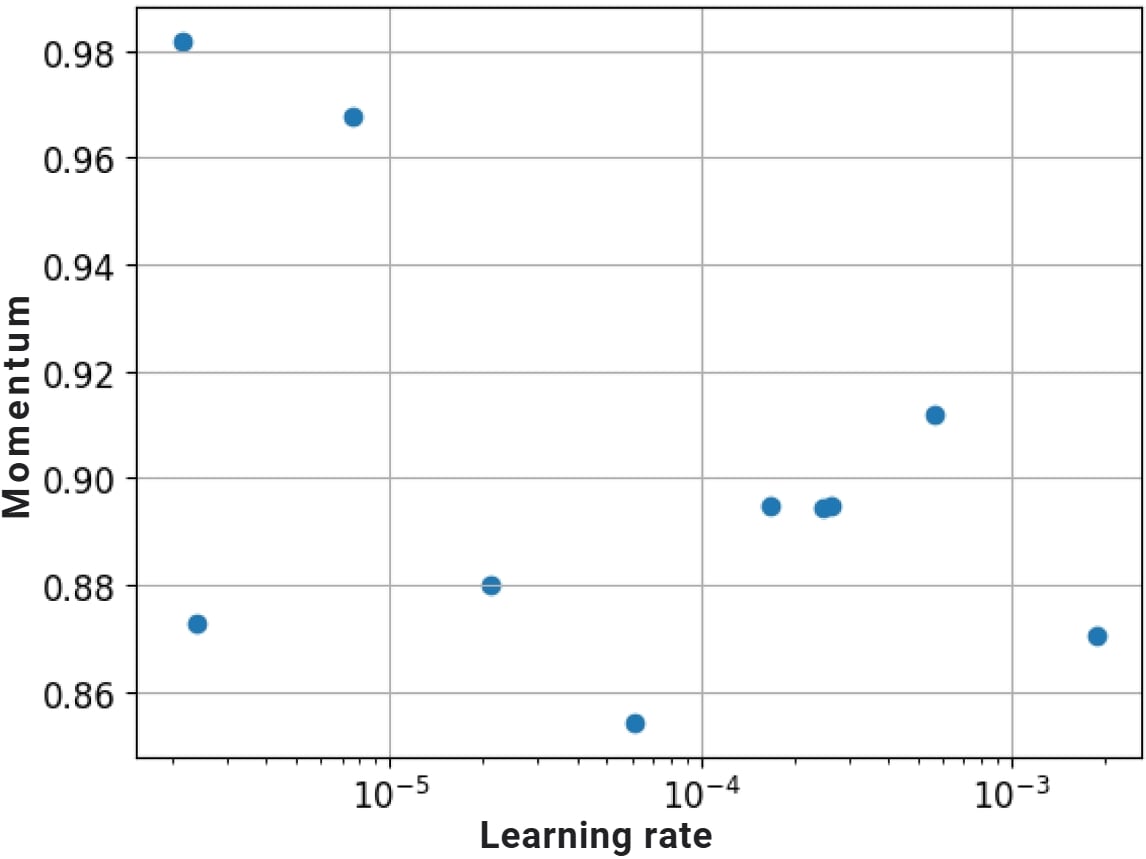
Étape 3 : affiner les hyperparamètres
- Recherche par grille
for factor in range(2, 6):
lr = 10 ** -factor
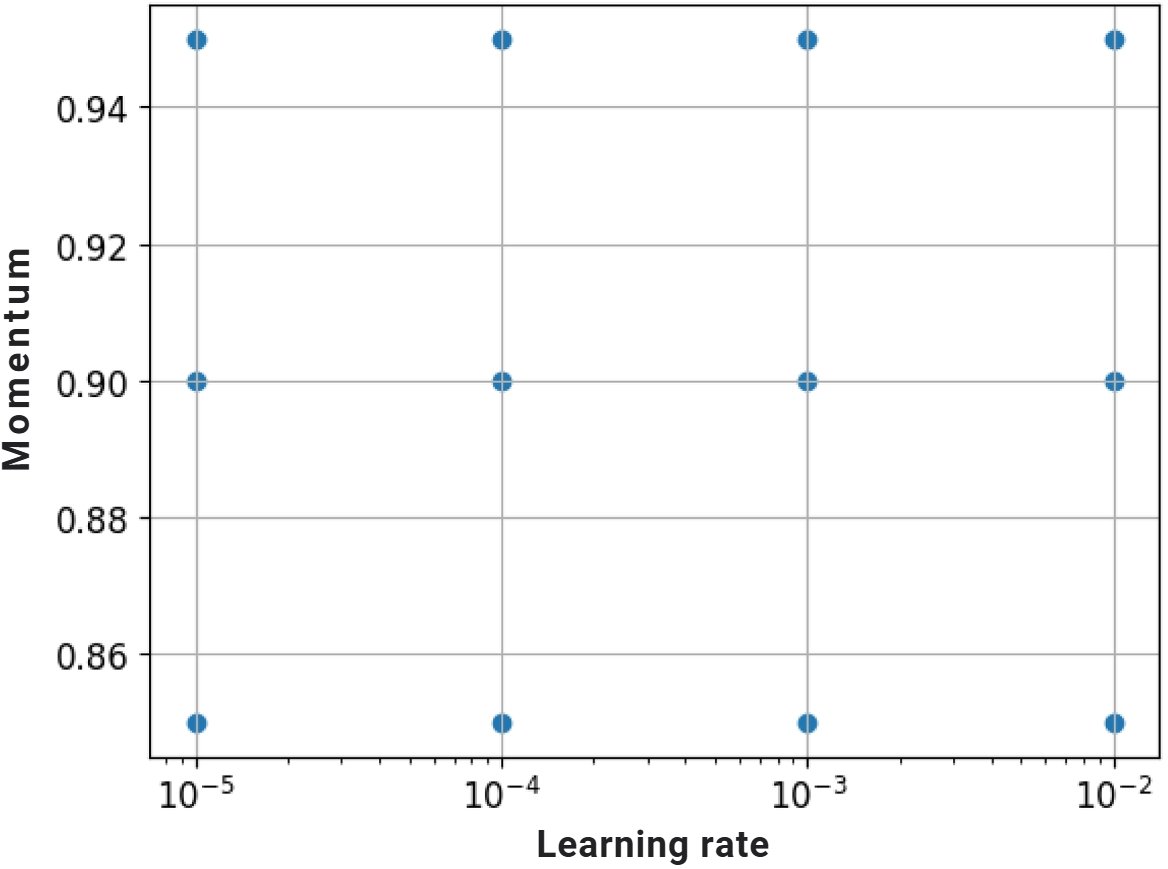
- Recherche aléatoire
factor = np.random.uniform(2, 6)
lr = 10 ** -factor